原文标题:Accelerate Generative AI Inference on Amazon SageMaker AI with G7e Instances
原文链接:https://aws.amazon.com/blogs/machine-learning/accelerate-generative-ai-inference-on-amazon-sagemaker-ai-with-g7e-instances/

随着生成式 AI 需求的持续增长,开发者和企业正在寻求更灵活、更具成本效益且更强大的加速器来满足其需求。今天,我们很高兴地宣布,由 NVIDIA RTX PRO 6000 Blackwell 服务器版 GPU 提供支持的 G7e 实例现已在 Amazon SageMaker AI 上正式推出。
您可以配置搭载 1、2、4 和 8 块 RTX PRO 6000 GPU 的节点,每块 GPU 提供 96 GB GDDR7 显存。本次发布使您能够使用单节点 GPU(G7e.2xlarge 实例)托管 GPT-OSS-120B、Nemotron-3-Super-120B-A12B(NVFP4 变体)和 Qwen3.5-35B-A3B 等强大的开源基础模型(FM),为希望在保持高推理性能的同时降低成本的组织提供了一个高性价比的选择。G7e 实例的主要亮点包括:
- GPU 显存是 G6e 实例的两倍,支持以 FP16 精度部署大型语言模型(LLM),最高可达:
- 在单 GPU 节点(G7e.2xlarge)上部署 350 亿参数模型
- 在 4 GPU 节点(G7e.24xlarge)上部署 1500 亿参数模型
- 在 8 GPU 节点(G7e.48xlarge)上部署 3000 亿参数模型
- 网络吞吐量高达 1600 Gbps
- G7e.48xlarge 上的 GPU 显存总量高达 768 GB
Amazon Elastic Compute Cloud(Amazon EC2)G7e 实例代表了云端 GPU 加速推理的重大飞跃。与上一代 G6e 实例相比,它们的推理性能提升了最多 2.3 倍。每块 G7e GPU 提供 1,597 GB/s 的带宽,单块 GPU 的显存是 G6e 的两倍,是 G5 的四倍。在最大 G7e 规格上,通过 EFA 的网络带宽可扩展至 1,600 Gbps——比 G6e 提升 4 倍,比 G5 提升 16 倍——解锁了此前在 G 系列实例上不切实际的低延迟多节点推理和微调场景。下表汇总了 8 GPU 层级的代际演进:
| 规格 | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
|---|---|---|---|
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| 每 GPU 显存 | 24 GB GDDR6 | 48 GB GDDR6 | 96 GB GDDR7 |
| GPU 显存总量 | 192 GB | 384 GB | 768 GB |
| GPU 显存带宽 | 600 GB/s/GPU | 864 GB/s/GPU | 1,597 GB/s/GPU |
| vCPU | 192 | 192 | 192 |
| 系统内存 | 768 GiB | 1,536 GiB | 2,048 GiB |
| 网络带宽 | 100 Gbps | 400 Gbps | 1,600 Gbps (EFA) |
| 本地 NVMe 存储 | 7.6 TB | 7.6 TB | 15.2 TB |
| 相对 G6e 的推理性能 | 基准 | ~1x | 最高 2.3x |
在单一实例上拥有 768 GB 聚合 GPU 显存,G7e 可托管此前在 G5 或 G6e 上需要多节点设置才能运行的模型,从而降低了运维复杂性和节点间延迟。结合对使用第五代 Tensor Core 的 FP4 精度的支持,以及通过 EFAv4 的 NVIDIA GPUDirect RDMA,G7e 实例已成为在 AWS 上部署 LLM、多模态 AI 和 Agent 推理工作负载的首选。
G7e 的适用场景
G7e 兼具显存密度、带宽和网络能力,非常适合广泛的现代生成式 AI 工作负载:
- 聊天机器人和对话式 AI – G7e 的低首个 Token 时间(TTFT)和高吞吐量,即使在高并发负载下也能保持交互体验的响应性。
- Agent 和工具调用工作流 – CPU 到 GPU 带宽提升 4 倍,使 G7e 在检索增强生成(RAG)流水线和需要从检索存储快速注入上下文的 Agent 工作流中表现尤为出色。
- 文本生成、摘要和长上下文推理 – G7e 每 GPU 96 GB 的显存可容纳超长文档上下文的大型 KV 缓存,减少截断并实现对长输入更丰富的推理。
- 图像生成和视觉模型 – 在较早代实例上会因显存不足而出错的大型多模态模型,G7e 翻倍的显存可彻底解决这一限制。
- 物理 AI 和科学计算 – G7e 的 Blackwell 代计算能力、FP4 支持和空间计算能力(DLSS 4.0、第四代 RT 核心)将其适用范围扩展到数字孪生、3D 仿真和物理 AI 模型推理。
部署演练
前提条件
要使用 SageMaker AI 尝试此方案,您需要满足以下前提条件:
- 一个包含所有 AWS 资源的 AWS 账户。
- 一个用于访问 Amazon SageMaker AI 的 AWS 身份和访问管理(IAM) 角色。如需了解 IAM 与 SageMaker AI 协作方式的更多信息,请参阅 Amazon SageMaker AI 的身份和访问管理。
- 访问 Amazon SageMaker Studio、SageMaker 笔记本实例,或 PyCharm、Visual Studio Code 等集成开发环境(IDE)。我们建议使用 Amazon SageMaker Studio 进行简单的部署和推理。
- 适用于 Amazon SageMaker AI 端点用途的一个 ml.g7e.2xlarge(或更大)实例的配额。您可以通过 Service Quotas 控制台申请增加配额。
部署
您可以克隆仓库并使用此处提供的示例 Notebook。
性能基准测试
为了量化代际改进,我们使用相同的工作负载对 G6e 和 G7e 实例上的 Qwen3-32B(BF16)进行了基准测试:每次请求约 1,000 个输入 Token 和约 560 个输出 Token。这代表了文档摘要或纠错任务。两种配置均使用启用了前缀缓存的原生 vLLM 容器。
生成这些结果所使用的基准测试套件可在示例 Jupyter Notebook 中找到。它遵循三步流程:(1)使用原生 vLLM 容器在 SageMaker AI 端点上部署模型;(2)在 1 到 32 个并发请求的并发级别下进行负载测试;(3)分析结果以生成以下性能表格。
G6e 基准:ml.g6e.12xlarge [4x L40S,$13.12/小时]
配备 4 块 L40S GPU 和张量并行度 4,G6e 提供了出色的单请求吞吐量:单并发时为 37.1 tok/s,C=32 时为 21.5 tok/s。
| C | 成功率 | p50 (s) | p99 (s) | tok/s | RPS | 聚合 tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 16.1 | 16.3 | 37.1 | 0.07 | 37 | $38.09 |
| 8 | 100% | 19.8 | 20.2 | 30.3 | 0.42 | 242 | $5.85 |
| 16 | 100% | 23.1 | 23.5 | 26.0 | 0.73 | 416 | $3.41 |
| 32 | 100% | 26.0 | 29.2 | 21.5 | 1.21 | 686 | $2.06 |
G7e:ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell,$4.20/小时]
G7e 在单块 GPU 上运行相同的 320 亿参数模型,张量并行度为 1。虽然单请求 tok/s 低于 G6e 4 GPU 配置,但成本表现截然不同。
| C | 成功率 | p50 (s) | p99 (s) | tok/s | RPS | 聚合 tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 27.2 | 27.5 | 22.0 | 0.04 | 22 | $21.32 |
| 8 | 100% | 28.7 | 28.9 | 20.9 | 0.28 | 167 | $2.81 |
| 16 | 100% | 30.3 | 30.6 | 19.9 | 0.53 | 318 | $1.48 |
| 32 | 100% | 33.2 | 33.3 | 18.5 | 0.99 | 592 | $0.79 |
数字揭示了什么
在生产并发(C=32)下,G7e 每百万输出 Token 的成本为 $0.79,与 G6e 的 $2.06 相比降低了 2.6 倍。这由两个因素驱动:G7e 显著更低的小时费率($4.20 对比 $13.12)及其在负载下维持一致吞吐量的能力。G7e 的单 GPU 架构扩展也更为优雅。延迟从 C=1 到 C=32 仅增加 22%(27.2s 到 33.2s),而 G6e 则增加了 62%(16.1s 到 26.0s)。张量并行度为 1 时,不存在:
- GPU 间同步开销
- 每个 Transformer 层的 all-reduce 操作
- 跨 GPU 的 KV 缓存碎片化
- NVLink 通信瓶颈
随着并发增加和 GPU 趋于饱和,这种无协调开销的特性使延迟保持可预测。对于低并发下的延迟敏感型工作负载,G6e 的 4 GPU 并行仍然能提供更快的单次响应。对于追求规模化低成本每 Token 的生产部署,G7e 是明确的选择,正如我们在下一节所示,将 G7e 与 EAGLE(用于提升语言模型效率的外推算法)推测性解码相结合会进一步放大这一优势。
组合基准测试:G7e + EAGLE 推测性解码
G7e 本身的硬件改进已经相当显著,但将其与 EAGLE 推测性解码相结合会产生复合收益。EAGLE 通过从模型自身的隐藏表示预测多个未来 Token,然后在单次前向传播中验证它们,从而加速 LLM 解码。这在保持相同输出质量的同时,每步生成多个 Token。如需了解 EAGLE 在 SageMaker AI 上的详细介绍,包括优化作业设置和基础版与训练版 EAGLE 工作流,请参阅 Amazon SageMaker AI 推出基于 EAGLE 的自适应推测性解码以加速生成式 AI 推理。
在本节中,我们使用 BF16 精度的 Qwen3-32B 衡量从基准到 G7e + EAGLE3 的叠加改进效果。基准工作负载每次请求使用约 1,000 个输入 Token 和约 560 个输出 Token,代表文档摘要或纠错任务。EAGLE3 使用带有 num_speculative_tokens=4 的社区训练推测器(约 1.56 GB)启用。
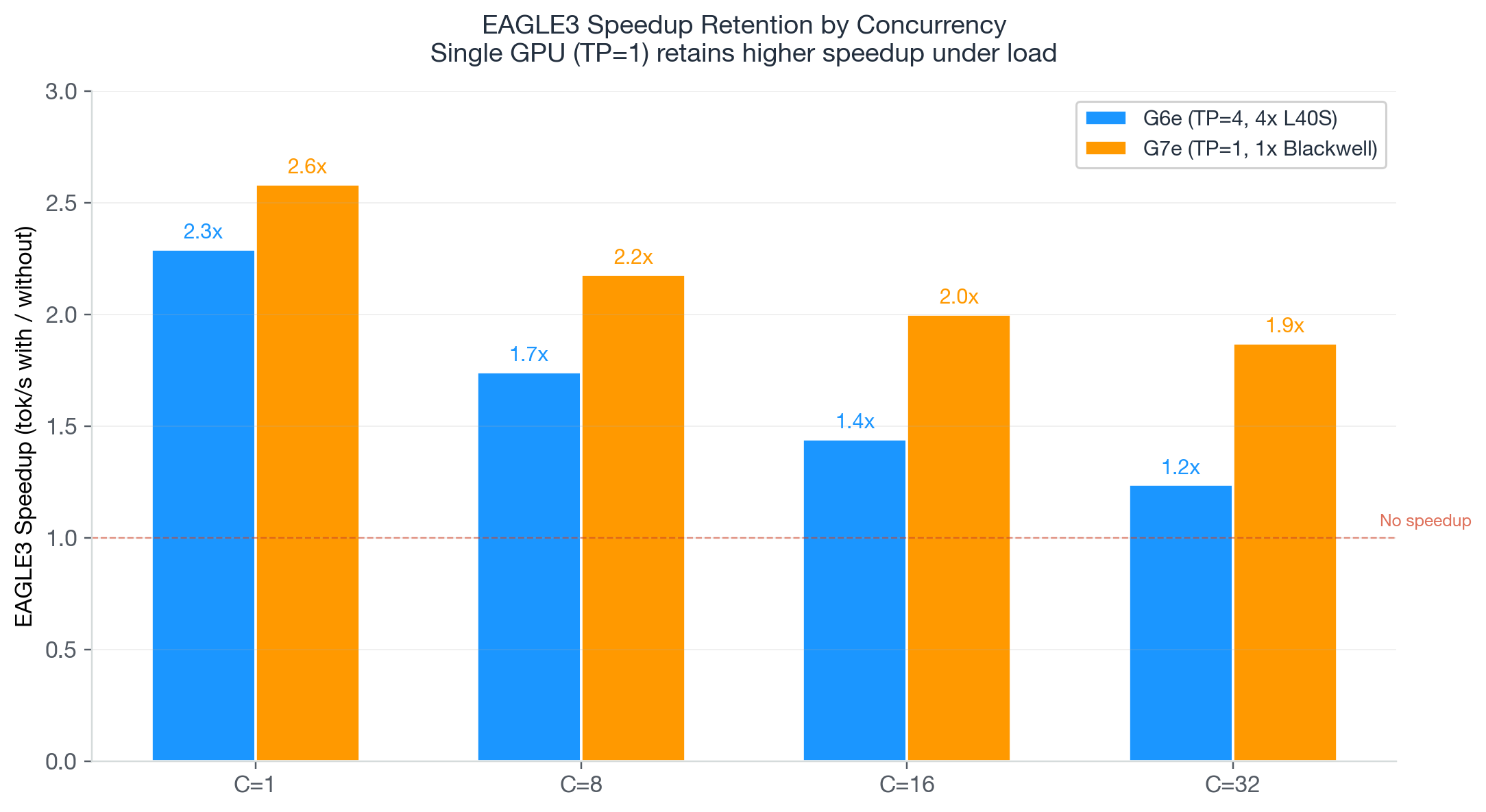
G7e + EAGLE3 相比上一代基准实现了 2.4 倍的吞吐量提升和 75% 的成本降低。在每百万输出 Token 成本 $0.41 的情况下,其成本也是 G6e + EAGLE3($1.72)的 4 倍,同时提供了更高的吞吐量。
启用 EAGLE3
对于使用微调模型的生产部署,SageMaker AI 的 EAGLE 优化工具包可以在您自己的数据上训练自定义 EAGLE 头,进一步提高推测接受率和吞吐量,超越社区推测器所能提供的水平。
定价
Amazon SageMaker AI 上的 G7e 实例按所选实例类型和使用时长的标准 SageMaker AI 推理定价计费。在 G7e 上服务不收取额外的每 Token 或每请求费用。
EAGLE 优化作业在 SageMaker AI 训练实例上运行,按作业时长的标准 SageMaker 训练实例费率计费。生成的改进模型 Artifact 存储在 Amazon Simple Storage Service(Amazon S3) 中,按标准存储费率计费。改进后的模型部署后,EAGLE 加速推理不收取额外费用。您只需支付标准端点实例成本。
下表显示了美国东部(弗吉尼亚州北部)主要 G7e、G6e 和 G5 实例规格的按需定价供参考。G7e 行已高亮显示。
| 实例 | GPU | GPU 显存 | 典型用例 |
|---|---|---|---|
| ml.g5.2xlarge | 1 | 24 GB | 小型 LLM(≤7B FP16);开发和测试 |
| ml.g5.48xlarge | 8 | 192 GB | G5 上的大型多 GPU LLM 服务 |
| ml.g6e.2xlarge | 1 | 48 GB | 中型 LLM(≤14B FP16) |
| ml.g6e.12xlarge | 2 | 96 GB | 大型 LLM(≤36B FP16);上一代基准 |
| ml.g6e.48xlarge | 8 | 384 GB | 超大型 LLM(≤90B FP16) |
| ml.g7e.2xlarge | 1 | 96 GB | 单 GPU 上的大型 LLM(≤70B FP8) |
| ml.g7e.24xlarge | 4 | 384 GB | 超大型 LLM;高吞吐量服务 |
| ml.g7e.48xlarge | 8 | 768 GB | 最高吞吐量;最大模型 |
您还可以通过 Amazon SageMaker Savings Plans 降低推理成本,该计划承诺一定的一致使用量,可提供高达 64% 的折扣。这非常适合具有可预测流量的生产推理端点。
清理
在完成测试后,为避免产生不必要的费用,请删除演练过程中创建的 SageMaker 端点。您可以通过 SageMaker AI 控制台或使用 Amazon SageMaker AI 开发者指南中所示的 Python SDK 来完成此操作。
如果您运行了 EAGLE 优化作业,还应从 Amazon S3 中删除输出 Artifact,以避免持续的存储费用。
结论
Amazon SageMaker AI 上的 G7e 实例代表了经济高效的生成式 AI 推理的下一个重大飞跃。Blackwell GPU 架构每 GPU 提供 2 倍的显存、1.85 倍的显存带宽,以及比 G6e 高达 2.3 倍的推理性能。这使得以前需要多 GPU 的工作负载能够在单 GPU 上高效运行,并提高了每种 GPU 配置的吞吐量上限。与 SageMaker AI 的 EAGLE 推测性解码相结合后,改进效果进一步复合。EAGLE 的显存带宽受限加速直接受益于 G7e 的更高带宽,而 G7e 更大的显存容量使 EAGLE 草稿头能够与更大的模型共存,而不会产生显存压力。硬件和软件的共同改进带来了吞吐量提升,直接转化为规模化情境下更低的每输出 Token 成本。
从 G5 到 G6e 再到 G7e 的演进,叠加 EAGLE 优化,代表了一条近乎持续的硬件-软件协同优化路径——随着模型演进,以及生产流量数据被捕获并反馈到 EAGLE 再训练中,这条路径将不断改进。