原文标题:Power video semantic search with Amazon Nova Multimodal Embeddings
原文链接:https://aws.amazon.com/blogs/machine-learning/power-video-semantic-search-with-amazon-nova-multimodal-embeddings/

视频语义搜索正在各行各业释放新的价值。视频优先体验的需求正在重塑组织交付内容的方式,用户希望能够快速、准确地访问视频中的特定时刻。例如,体育广播公司需要在球员得分的精确时刻提取精彩片段,即时推送给球迷;影视公司需要在数千小时的存档内容中找出某位演员的所有场景,以制作个性化预告片和宣传内容;新闻机构需要按情绪、地点或事件检索素材,以比竞争对手更快地发布突发新闻。目标始终如一:快速将视频内容推送给终端用户,抓住时机,实现商业变现。
视频本质上比文字或图片等其他模态更为复杂,因为它融合了多种非结构化信号:屏幕上展现的视觉场景、环境音频和音效、对话语音、时序信息,以及描述资产的结构化元数据。用户搜索”伴随警报声的紧张追车场景”时,是在同时查询视觉事件和音频事件。用户搜索某位特定运动员的姓名时,可能是在寻找屏幕上显眼出现、但从未被口头提及的人物。
当今主流方案将所有视频信号转化为文本——无论是通过转录、手工标注还是自动生成字幕——再应用文本嵌入进行搜索。虽然这对对话密集型内容有效,但将视频转化为文本不可避免地会丢失关键信息:时序理解消失了,视频和音频质量问题带来的转录错误也随之而来。如果有一个模型能直接处理所有模态,并在不丢失细节的情况下将它们映射到单一可搜索表示中,会怎样?Amazon Nova多模态嵌入是一个统一的嵌入模型,能原生处理文本、文档、图像、视频和音频,并将它们映射到共享的语义向量空间。它提供领先的检索准确率和成本效益。
本文将介绍如何在Amazon Bedrock上使用Nova多模态嵌入构建视频语义搜索解决方案,该方案能智能理解用户意图,并同时在所有信号类型中检索出准确的视频结果。我们还将分享一个您可以部署并用自己内容探索的参考实现。
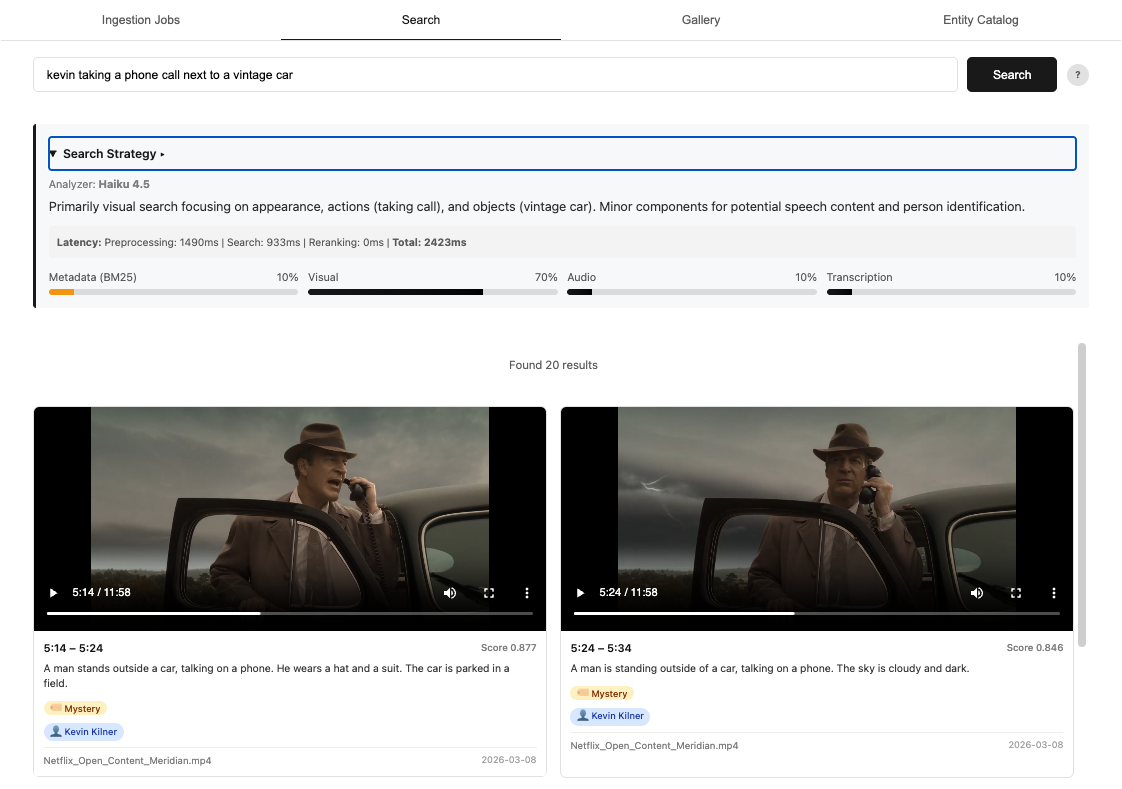
图1:最终搜索解决方案的示例截图
解决方案概述
我们的解决方案基于Nova多模态嵌入,结合融合了语义和词法信号的智能混合搜索架构,跨所有视频模态进行检索。词法搜索匹配精确的关键词和短语,而语义搜索则理解含义和上下文。我们将在后续章节详细说明选择这种混合方法的原因及其性能优势。
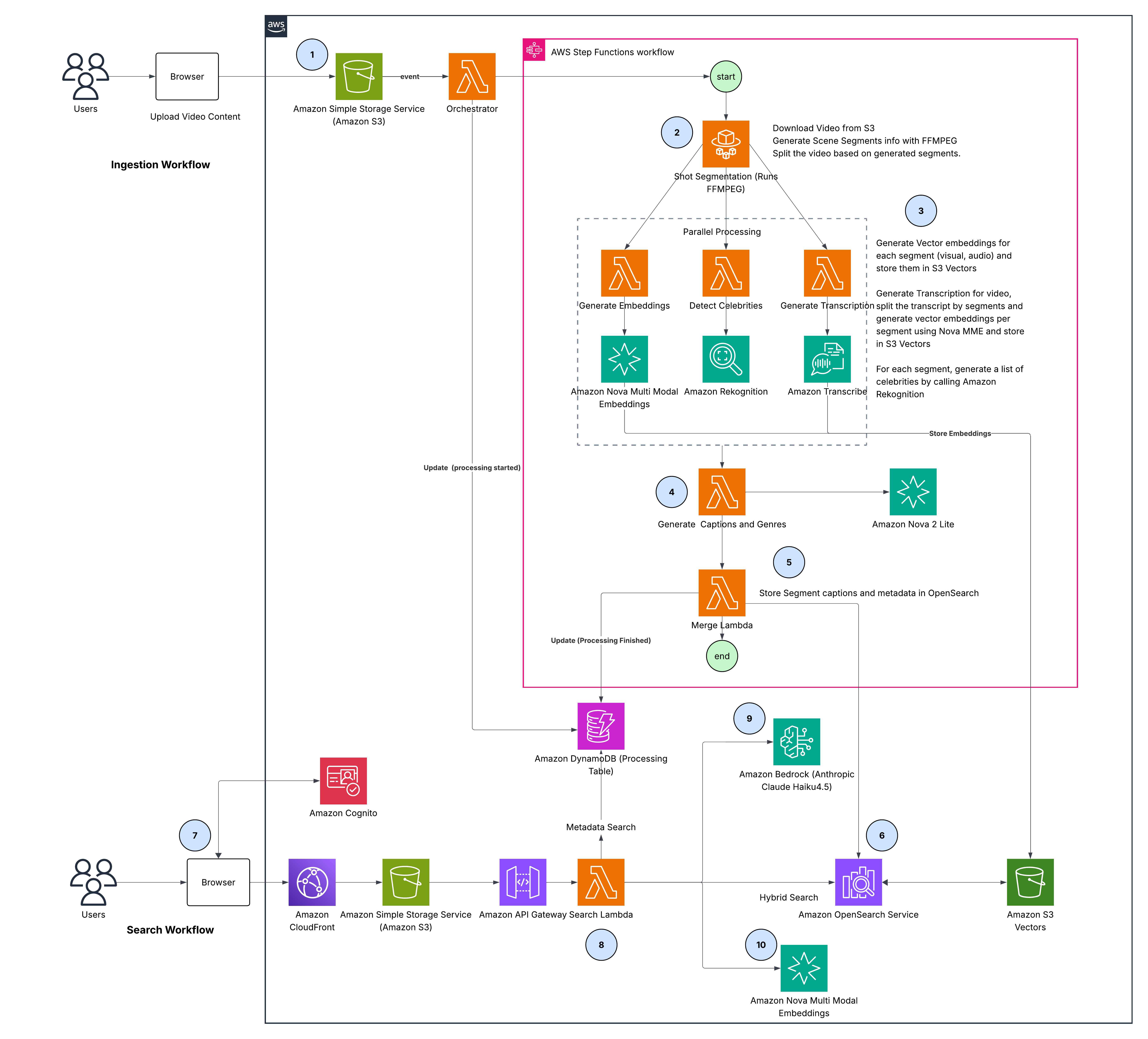
图2:端到端解决方案架构
该架构由两个阶段组成:摄入管线(步骤1-6)将视频处理为可搜索的嵌入,搜索管线(步骤7-10)跨这些表示智能路由用户查询,并将结果合并为排序列表。以下是每个步骤的详细说明:
- 上传 – 通过浏览器上传的视频存储在Amazon Simple Storage Service(Amazon S3)中,触发编排器AWS Lambda更新Amazon DynamoDB状态并启动AWS Step Functions管线
- 镜头分割 – AWS Fargate使用FFmpeg场景检测将视频分割为语义连贯的片段
- 并行处理 – 三个并发分支处理每个片段: a. 嵌入: Nova多模态嵌入为视觉和音频生成1024维向量,存储在Amazon S3 Vectors中 b. 转录: Amazon Transcribe将语音转换为文本,与片段对齐;Amazon Nova多模态嵌入生成存储在Amazon S3 Vectors中的文本嵌入 c. 名人检测: Amazon Rekognition识别已知人物,按时间戳映射到片段
- 字幕与类型生成 – Amazon Nova 2 Lite根据视觉内容和转录文本合成片段级别的字幕和类型标签
- 合并 – AWS Lambda汇整所有元数据(字幕、转录文本、名人、类型),并从Amazon S3 Vectors中获取嵌入
- 索引 – 将包含元数据和向量的完整片段文档批量索引到Amazon OpenSearch Service
- 身份验证 – 用户通过Amazon Cognito进行身份验证,并通过Amazon CloudFront访问前端
- 查询处理 – Amazon API Gateway将请求路由到搜索Lambda,后者并行执行意图分析和查询嵌入两个操作
- 意图分析 – Amazon Bedrock(使用Anthropic Claude Haiku)为视觉、音频、转录和元数据模态分配相关性权重(0.0-1.0)
- 查询嵌入 – Nova多模态嵌入对查询进行三次嵌入,分别用于视觉、音频和转录的相似性搜索
这种灵活的架构解决了大多数视频搜索系统忽视的四个关键设计决策:保持时序上下文、处理多模态查询、在大规模内容库中扩展,以及优化检索准确率。GitHub上提供了完整的参考实现,我们鼓励您跟随以下详解,了解每个决策如何为跨所有信号类型的准确、可扩展搜索做出贡献。
分割策略与上下文连续性
在生成任何嵌入之前,您需要将视频分割成可搜索的单元,而您划定的边界会直接影响搜索准确率。每个片段成为检索的原子单位。如果片段太短,就会失去赋予某个时刻意义的周围上下文;如果太长,则会融合多个主题或场景,稀释相关性,使搜索系统难以找到合适的时刻。为简便起见,可以从固定长度的块开始。Nova多模态嵌入支持每次嵌入最多30秒,让您灵活捕捉完整场景。但请注意,固定边界可能会在动作进行到一半时任意截断场景,或将一个句子从中间断开,破坏使某个时刻可被检索的语义含义,如下图所示。

图3:视频分割策略
目标是语义连续性:每个片段应代表一个连贯的意义单位,而不是任意的时间切片。固定10秒的块虽然容易生成,但忽略了内容的自然结构。片段中途出现的场景切换会将一个视觉概念分割到两个块中,降低检索精度和嵌入质量。
为解决这个问题,我们使用FFmpeg的场景检测来识别视觉内容实际发生变化的位置。FFmpeg是一个广泛用于视频处理、格式转换和分析的开源多媒体框架。以下_detect_scenes函数对视频运行ffprobe(FFmpeg的媒体检查工具)并返回时间戳列表,每个时间戳标记一个场景边界:
def _detect_scenes(video_path):
result = subprocess.run(
['ffprobe', '-v', 'quiet', '-show_entries', 'frame=pts_time', '-of', 'csv=p=0',
'-f', 'lavfi', f"movie={video_path},select='gt(scene\\,{SCENE_THRESHOLD})'"],
capture_output=True, text=True
)输出是一个简单的时间戳列表,如12.345、28.901、45.678,每个时间戳标记场景发生自然转换的位置。
有了这些边界,分割算法会将每个切割点对齐到可接受范围内最近的场景变化,目标约10秒,最小5秒,最大15秒(从当前起始点算起)。如果该范围内没有场景变化,则回退到目标时长处的硬切。结果是一组自然的片段:8.3秒、11.1秒、9.8秒、12.4秒、7.6秒,每个片段都对齐到真实的场景边界,而不是固定的时钟。
这种简单的基于镜头的分割确保片段边界与自然视觉转换对齐,而不是任意切割。目标片段时长应根据内容类型和使用场景进行校准:动作密集、剪切频繁的内容可能得益于这种视觉分割,而纪录片或访谈类内容中较长的镜头则可能更适合更长的、基于主题的分割。有关更高级的分割技术,包括基于音频的主题分割和视觉与音频相结合的方法,建议阅读Media2Cloud on AWS Guidance: Scene and Ad-Break Detection and Contextual Understanding for Advertising Using Generative AI。
为视觉、音频和转录信号分别生成嵌入
确定好片段后,嵌入模型的选择是方法之间质量差距最大的地方。当今主流方案在生成嵌入之前将所有视频信号转化为文本,但正如我们前面所说,视频承载的意义远超任何转录或字幕所能表达的范围。视觉动作、环境声音、屏幕上的文字和实体上下文要么完全丢失,要么通过不精确的描述来近似呈现。
Nova多模态嵌入从根本上改变了这一状况,因为它是一个可以以两种模式生成嵌入的视频原生模型。联合模式将视觉和音频信号融合为统一的表示,同时捕获最重要的信号。这种方式通过每个片段只需一个嵌入来降低存储成本和检索延迟。另外,AUDIO_VIDEO_SEPARATE模式生成独立的视觉和音频嵌入。这种方式在特定模态的嵌入中提供了最大的表示能力,并让您更好地控制何时搜索视觉内容与音频内容。
在我们的实现中,我们甚至添加了第三个语音嵌入,该嵌入来源于Amazon Transcribe。这个嵌入通过将完整句子转录文本对齐到嵌入片段的前后时间戳来创建,保留了口语的语义完整性,确保完整的思想永远不会被分割到两个嵌入中。
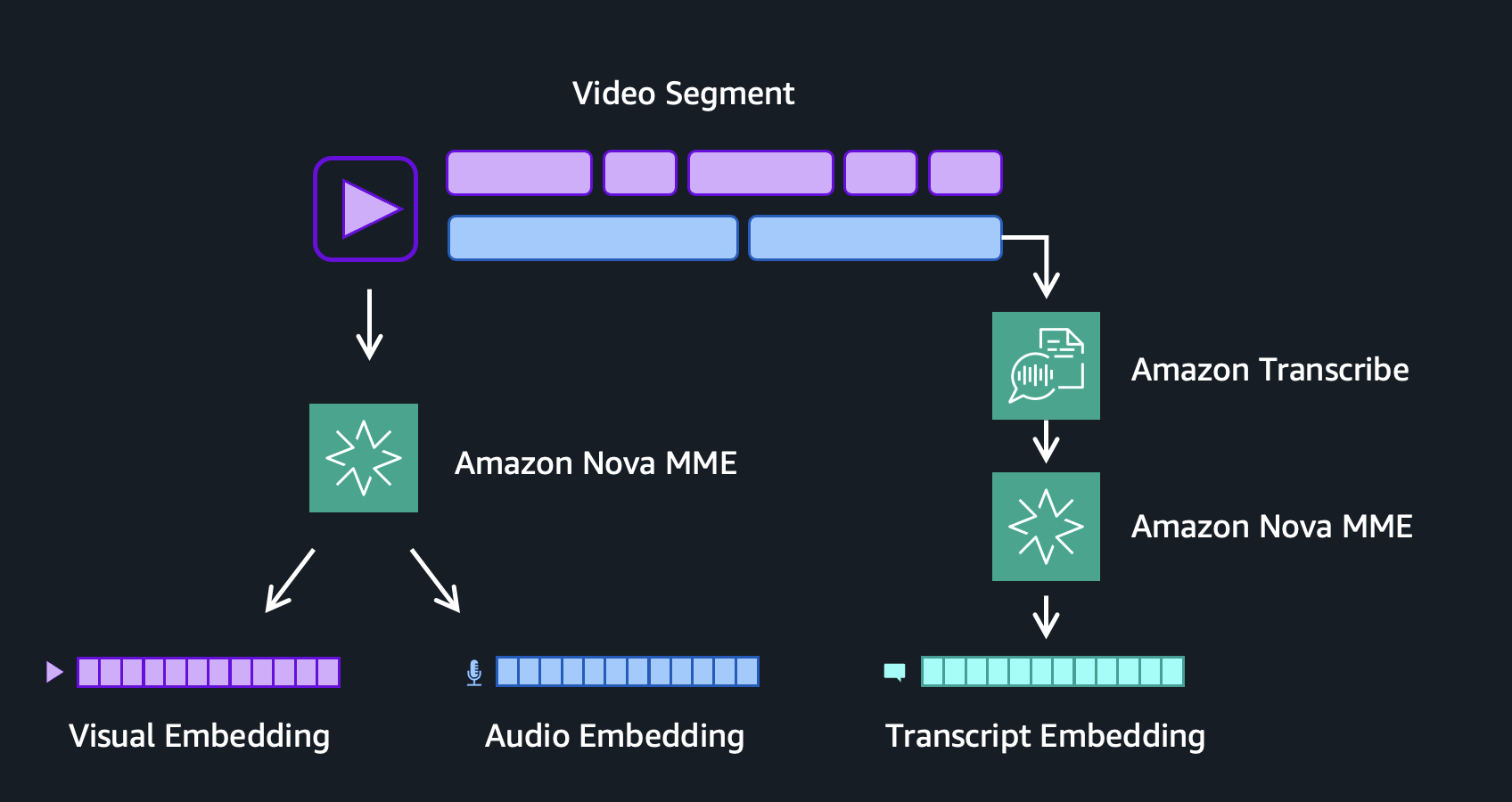
图4:每个视频片段的视觉、音频和语音嵌入生成
这三个嵌入共同覆盖了视频片段的完整信号空间。视觉嵌入捕获摄像机所看到的:物体、场景、动作、颜色和空间构图。音频嵌入捕获麦克风所听到的:音乐、音效、环境噪声和场景的声学质感。转录嵌入捕获人们所说的话,表示口语对话和叙述的语义含义。将这三个信号合并到一个联合嵌入中,会将不同模态压缩到一个向量中。这模糊了所见、所听和所说之间的边界,失去了每个信号独立时所具有的精细细节。保持它们分离让您能够精确控制,根据查询意图上调或下调每个模态的权重,使搜索管线能够与最可能包含答案的模态进行匹配。
结合元数据和嵌入实现混合搜索
即使有三个独立的嵌入,分别覆盖视觉、音频和口语内容,系统仍然有一类查询无法很好地处理。嵌入是为捕获语义相似性而设计的。它们擅长找到”紧张的人群时刻”或”夕阳西沉水面”,因为这些概念具有丰富的视觉和音频含义。但当用户搜索特定姓名、产品型号、地理位置或特定日期时,嵌入可能会失败。这些是离散实体,本身几乎没有语义信号。这就是混合搜索发挥作用的地方。系统不是单独依赖嵌入,而是如下图所示并行运行两条检索路径:语义路径与您的视觉、音频和转录嵌入进行匹配以捕获概念相似性,词法路径则对结构化元数据执行精确的关键词和实体匹配。
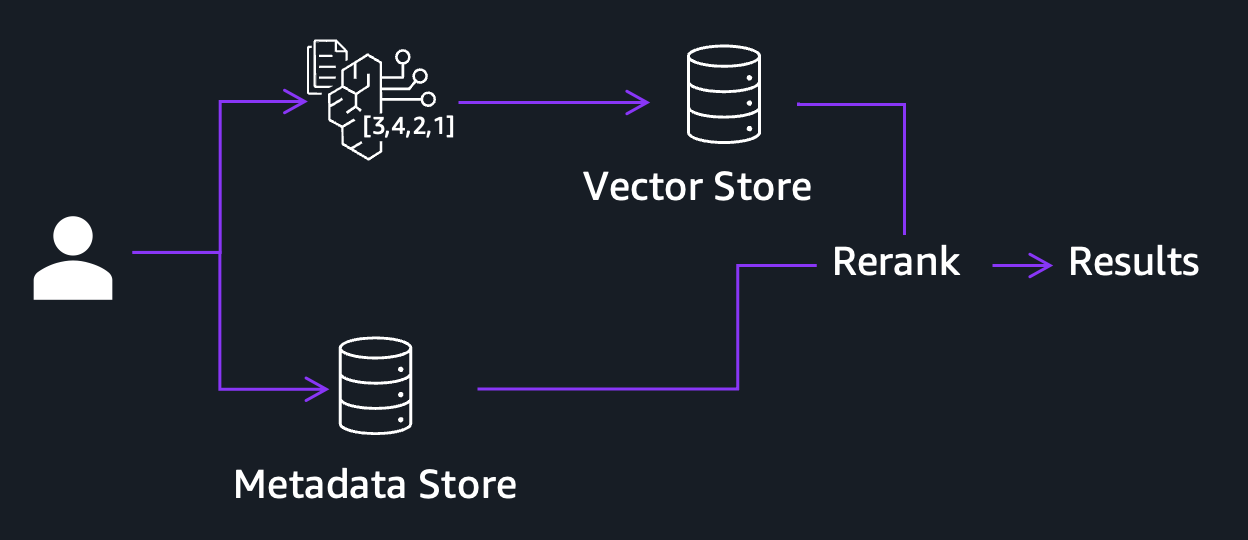
图5:结合语义和词法检索的混合搜索管线
您需要多少元数据?答案取决于您的内容类型、组织和使用场景,提前捕获所有内容是不现实的。为便于说明,我们选择了几类元数据,代表媒体和娱乐内容中常见的元数据类型。
首先,我们选择视频标题和日期时间来代表直接从内容目录或文件元数据中提取的技术元数据。然后添加片段字幕、类型和名人识别来代表上下文元数据,这些由Amazon Nova 2 Lite和Amazon Rekognition生成。字幕由每个片段的视频和转录文本生成,为模型提供视觉和口语两种上下文。类型从所有片段的完整视频转录文本中预测,这比重新发送所有视频片段更便宜、更可靠。名人识别由Amazon Rekognition处理,无需自定义训练即可识别出现在屏幕上的已知公众人物。
以下是字幕生成和类型分类使用的示例提示:
# 字幕生成
Describe this video clip in 3-5 sentences. Include:
- What is happening, who is visible, actions, setting, and environment
- Any text on screen: titles, subtitles, signs, logos, watermarks, or credits
- If the screen is mostly black or blank, state "Black frame" or "Blank screen"
Transcription: {segment_transcript}
Return ONLY the descriptive caption, nothing else.
# 类型分类
Based on all the video segments described below, classify the overall video
into exactly ONE genre from this list: Sports, News, Entertainment,
Documentary, Education, Music, Gaming, Cooking, Travel, Technology,
Business, Lifestyle, Sci-Fi, Mystery, Other
Segment descriptions:
{all_captions}
Return ONLY the genre name, nothing else.这一概念自然可以扩展到其他元数据类型。技术元数据可能包括分辨率或文件大小,而上下文元数据则可能包括地点、情绪或品牌。正确的平衡取决于您的搜索使用场景。此外,在检索过程中叠加元数据过滤可以通过在语义匹配之前缩小搜索空间来进一步提升搜索的可扩展性和准确率。
通过意图感知查询路由优化搜索相关性
现在您拥有三个嵌入和元数据,共四个可搜索维度。但您如何知道对于给定的查询应该使用哪个?意图至关重要。为解决这个问题,我们构建了一个智能意图分析路由器,使用Haiku模型分析每个传入查询,并为每个模态通道(视觉、音频、转录和元数据)分配权重。请参见以下示例搜索查询:
“Kevin standing next to a vintage car and taking a phone call”(Kevin站在一辆老爷车旁接电话)
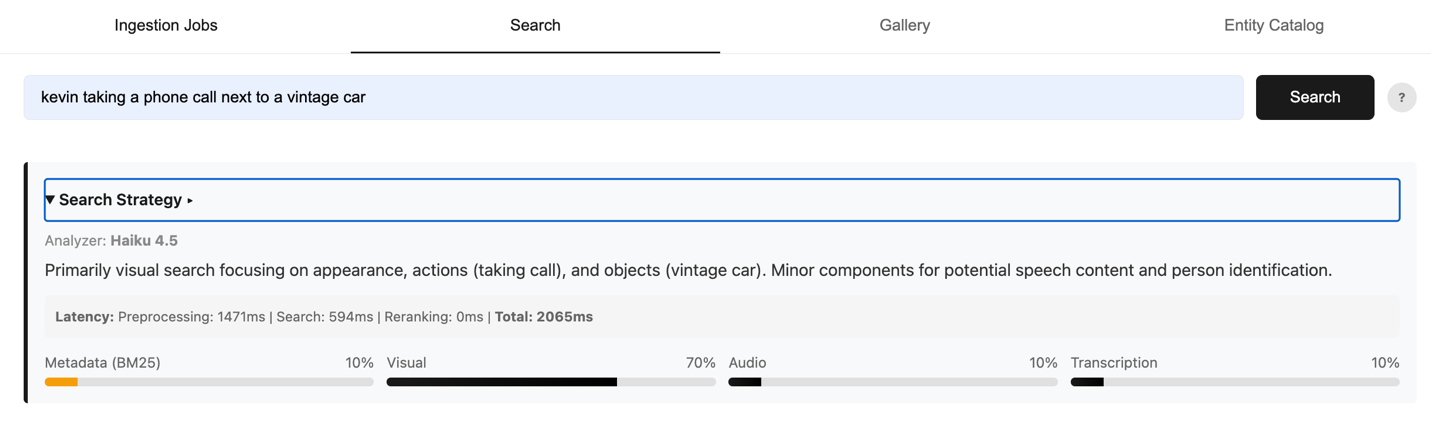
图6:根据搜索意图分配智能权重的查询示例
Haiku模型收到提示后,返回一个JSON对象,其中包含总和为1.0的权重,以及解释分配逻辑的简短推理跟踪。以下是提示示例:
Analyze this video search query and assign weights (0.0–1.0) for four modalities.
Weights must sum to 1.0.
Return ONLY valid JSON in this exact format:
{"visual": 0.0, "audio": 0.0, "transcription": 0.0, "metadata": 0.0, "reasoning": "..."}
Guidelines:
- visual: appearance, colors, objects, actions, scenes
- audio: sounds, music, noise, non-speech audio
- transcription: spoken words, dialogue, narration
- metadata: person names, genre, captions, factual attributes
Examples:
- "red car driving" → visual=0.9, metadata=0.1
- "person saying hello" → transcription=0.5, visual=0.2, audio=0.2, metadata=0.1
- "dog barking loudly" → audio=0.6, visual=0.3, metadata=0.1权重直接控制执行哪些子查询。任何权重低于5%阈值的模态将完全跳过,从而消除不必要的嵌入API调用,在不牺牲准确率的情况下降低搜索延迟。其余通道并行执行,各自独立搜索自己的索引。来自所有活跃通道的结果随后使用加权算术平均进行评分。BM25分数(基于词频和文档长度的词法相关性度量)和余弦相似度分数(衡量两个嵌入向量指向同一方向程度的几何度量)处于截然不同的尺度范围。为解决这个问题,每个子查询的分数首先归一化到0-1范围,然后使用路由器的意图权重进行合并:
final_score = w₁ × norm_bm25 + w₂ × norm_visual + w₃ × norm_audio + w₄ × norm_transcription我们选择加权算术平均作为重排序技术,因为它通过路由器权重直接融入查询意图。与倒数排名融合(RRF)不同——RRF无论意图如何都对所有活跃通道一视同仁——加权平均会放大路由器认为与给定查询最相关的通道。根据我们的测试,这在搜索任务上产生了更准确的结果。
为向量和元数据选择正确的存储策略
最后一个设计决策是将所有内容存储在哪里、如何存储。每个视频片段最多产生三个嵌入和一组元数据字段,存储方式决定了大规模下的搜索性能和成本。我们将其分布在两个具有互补作用的服务中:用于向量存储的Amazon S3 Vectors,以及用于混合搜索的Amazon OpenSearch Service。
S3 Vectors为每个项目存储三个向量索引,每种嵌入类型各一个:
nova-visual-{project_id}# 视觉嵌入nova-audio-{project_id}# 音频嵌入nova-transcription-{project_id}# 转录嵌入
OpenSearch为每个项目保存一个索引,其中每个文档代表单个视频片段,包含用于BM25搜索的文本字段和用于k近邻(kNN)搜索的向量字段:
{
"_id": "f953ceba_seg_0012",
"start_sec": 118.45,
"end_sec": 128.72,
"caption": "A presenter walks through a rice paddy in rural Jakarta, discussing how rice cultivation has shaped local civilization for thousands of years.",
"people": ["presenter_name"],
"genre": "Documentary",
"visual_vector": [0.023, -0.118, 0.045, ...],
"audio_vector": [0.045, 0.091, -0.033, ...],
"transcription_vector": [-0.067, 0.134, 0.012, ...]
}我们选择S3 Vectors是因为其成本性能优势。Amazon S3 Vectors与其他替代专业解决方案相比,向量存储和查询的成本降低了高达90%。如果搜索延迟对您的使用场景不是关键因素,S3 Vectors是一个强力的默认选择。如果您需要最低可能的延迟,我们建议使用OpenSearch的内存中Hierarchical Navigable Small World(HNSW)引擎来存储向量。
最后,值得指出的是,某些使用场景需要在语义密集度较高的较长视频片段中进行搜索,例如完整访谈、多分钟纪录片场景或延伸的产品演示。大多数多模态嵌入模型(包括Nova多模态嵌入)的最大输入时长为30秒,这意味着3分钟的片段无法作为单一单元进行嵌入。尝试这样做要么会失败,要么会被迫进行失去更广泛上下文的分块处理。
OpenSearch中的嵌套向量支持通过允许单个文档包含多个子片段嵌入来解决这个问题:
{
"_id": "f953ceba_scene_003",
"start_sec": 118.45,
"end_sec": 298.10,
"sub_segments": [
{ "start_sec": 118.45, "end_sec": 128.72, "visual_vector": [...] },
{ "start_sec": 128.72, "end_sec": 139.10, "visual_vector": [...] },
{ "start_sec": 139.10, "end_sec": 150.30, "visual_vector": [...] }
]
}在查询时,OpenSearch根据最佳匹配的子片段(而非单一平均表示)对文档进行评分,因此一个长场景可以匹配其中的特定视觉时刻,同时仍作为一个连贯的结果返回。
性能结果:优化方案如何优于基准
为验证我们的设计决策,我们使用10个内部长视频(5-20分钟)和20个涵盖视觉、音频、转录和元数据重点搜索的查询,对优化后的混合搜索与Nova多模态嵌入基准AUDIO_VIDEO_COMBINED模式进行了基准测试。基准使用每个10秒片段的单一统一向量、一个索引和一个kNN查询。我们的优化方案生成独立的视觉、音频和转录嵌入,用结构化元数据丰富片段,并应用根据查询意图动态加权模态通道的意图感知路由。下图展示了四个标准检索指标的结果:
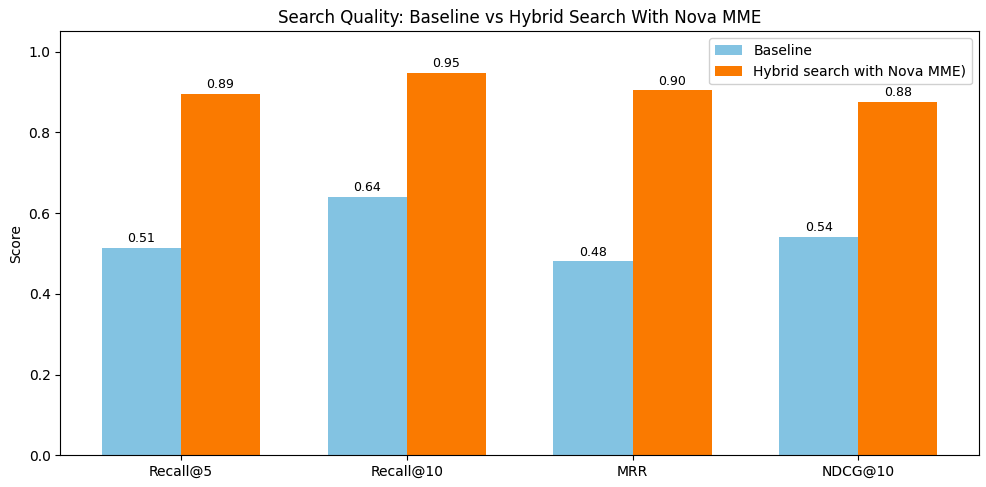
图7:混合搜索与Nova多模态嵌入 vs. 基准的各检索指标性能对比
以下表格记录了关键指标:
| Recall@5 | Recall@10 | MRR | NDCG@10 | |
|---|---|---|---|---|
| 混合搜索 + Nova多模态嵌入 | 90% | 95% | 90% | 88% |
| 基准 | 51% | 64% | 48% | 54% |
关键指标解释:
- Recall@5:在所有相关片段中,有多少比例出现在前5个结果中?这衡量的是搜索结果的覆盖范围。
- Recall@10:在所有相关片段中,有多少比例出现在前10个结果中?这衡量的是搜索结果的覆盖范围。
- MRR(平均倒数排名):第一个相关结果排名的倒数,在所有查询上取平均值。这衡量您找到相关内容的速度。
- NDCG@10:归一化折损累积增益,奖励排名更高的相关结果,惩罚排名更低的。这是一个标准的排名质量指标。
结果显示所有指标均有显著提升。优化后的混合搜索在Recall@5和Recall@10上分别达到90%以上,而基准为51%和64%(覆盖准确率提升约40%)。MRR从48%跃升至90%,NDCG@10从54%上升至88%。这30-40个百分点的提升验证了我们的核心架构决策:语义分割保持了内容连续性,独立嵌入提供了精确的搜索控制,元数据丰富捕获了事实实体,意图感知路由确保了每个查询都由正确的信号驱动。通过将每个模态独立处理,同时根据查询意图智能组合,系统能够适应多样化的搜索模式,并随着视频档案规模的扩大持续提供相关的搜索结果。
清理资源
为避免产生额外费用,请通过删除AWS CloudFormation堆栈来删除本解决方案中使用的资源。详细命令请参阅GitHub仓库。
结论
本文介绍了如何在AWS上使用Nova多模态嵌入构建视频语义搜索解决方案,涵盖四个关键设计决策:保持语义连续性的分割、独立捕获视觉、音频和语音信号的多模态嵌入、填补实体特定查询精度空缺的元数据,以及组织一切以实现大规模高效检索的数据结构。这些决策与智能意图分析路由器和加权重排序相结合,将一组分散的信号转变为统一的、能够理解视频的准确搜索体验。还可以进行更多优化来进一步提升搜索准确率,包括针对意图路由层的模型定制。请阅读第2部分深入了解这些技术。有关在大规模生产中实现这种视频搜索和元数据管理技术的完整实现,请参阅AWS媒体湖指南。