原文标题:Nova Forge SDK series part 2: Practical guide to fine-tune Nova models using data mixing capabilities
原文链接:https://aws.amazon.com/blogs/machine-learning/nova-forge-sdk-series-part-2-practical-guide-to-fine-tune-nova-models-using-data-mixing-capabilities/

本实操指南将带领您完成使用Amazon Nova Forge SDK对Amazon Nova模型进行微调的每一个步骤,从数据准备、使用数据混合进行训练,到最终评估,为您提供一套可复用、可适配到自身业务场景的完整操作手册。这是Nova Forge SDK系列的第二部分,在SDK介绍及第一部分(介绍如何启动定制化实验)的基础上进一步深入。
本文重点介绍数据混合——这一技术可让您在领域特定数据上进行微调,同时不损失模型的通用能力。在上一篇文章中,我们阐明了为什么这一点如此重要:将客户数据与Amazon精选数据集混合后,在覆盖1,420个叶子类别的客户之声(VOC)分类任务上实现了F1分数12个百分点的提升,同时MMLU(大规模多任务语言理解)分数几乎保持在基准水平。相比之下,仅在客户数据上微调一个开源模型,会导致通用能力几乎完全丧失。现在,我们将向您展示如何亲自实践这一过程。
解决方案概述
整个工作流分为五个阶段:
- 环境配置 – 安装Nova Forge SDK并配置AWS资源
- 数据准备 – 加载、清洗、转换、验证并拆分训练数据
- 训练配置 – 配置Amazon SageMaker HyperPod运行时、MLflow追踪及数据混合比例
- 模型训练 – 使用低秩适配(LoRA)启动并监控监督微调任务
- 模型评估 – 对微调后的检查点运行公共基准测试和领域特定评估
前提条件
开始之前,请确保您具备以下条件:
- 具备Amazon Nova Forge访问权限的AWS账号
- 配备GPU实例的SageMaker HyperPod集群。本指南使用
ml.p5.48xlarge实例。搭建HyperPod集群需要配置Amazon Elastic Kubernetes Service(Amazon EKS)集群、供应计算节点并创建执行角色。详细说明请参阅SageMaker HyperPod入门指南 - 用于实验追踪的Amazon SageMaker MLflow应用
- 具备SageMaker、Amazon Simple Storage Service(Amazon S3)和Amazon CloudWatch权限的IAM角色
- SageMaker Studio笔记本或类似的Jupyter环境
费用说明: 本指南在训练和评估阶段均使用4台ml.p5.48xlarge实例,这些是高端GPU实例。建议先以短周期测试运行(max_steps=5)验证配置,再进行完整训练。当前费率请参阅Amazon SageMaker定价页面。
第1步:安装Nova Forge SDK及依赖
SDK需要SageMaker HyperPod CLI工具。可从Nova Forge S3分发存储桶(在Nova Forge入网时提供)下载并安装,或使用以下便捷安装脚本,该脚本会从私有S3存储桶安装依赖并设置虚拟环境。
# 从Github下载HyperPod CLI安装程序(仅适用于Forge)
curl –O https://github.com/aws-samples/amazon-nova-samples/blob/main/customization/nova-forge-hyperpod-cli-installation/install_hp_cli.sh
# 运行安装程序
bash install_hp_cli.sh接下来,在同一虚拟环境中安装Nova Forge SDK(nova-forge-sdk),该SDK提供用于数据准备、训练和评估的高级API。
pip install --upgrade botocore awscli
pip install amzn-nova-forge
pip install datasets huggingface_hub pandas pyarrow安装所有依赖后,激活虚拟环境并将其设置为Jupyter笔记本环境的内核。
source ~/hyperpod-cli-venv/bin/activate
pip install ipykernel
python -m ipykernel install --user --name=hyperpod-cli-venv --
display-name="Forge (hyperpod-cli-venv)"
jupyter kernelspec list验证安装:
from amzn_nova_forge import *
print("SDK imported successfully")第2步:配置AWS资源
为训练数据和模型输出创建S3存储桶,然后授予HyperPod执行角色访问权限。
import boto3
import time
import json
TIMESTAMP = int(time.time())
S3_BUCKET = f"nova-forge-customisation-{TIMESTAMP}"
S3_DATA_PATH = f"s3://{S3_BUCKET}/demo/input"
S3_OUTPUT_PATH = f"s3://{S3_BUCKET}/demo/output"
sts = boto3.client("sts")
s3 = boto3.client("s3")
ACCOUNT_ID = sts.get_caller_identity()["Account"]
REGION = boto3.session.Session().region_name
# 创建S3存储桶
if REGION == "us-east-1":
s3.create_bucket(Bucket=S3_BUCKET)
else:
s3.create_bucket(
Bucket=S3_BUCKET,
CreateBucketConfiguration={"LocationConstraint": REGION}
)
# 授予HyperPod执行角色访问权限
HYPERPOD_ROLE_ARN = f"arn:aws:iam::{ACCOUNT_ID}:role/<your-hyperpod-execution-role>"
bucket_policy = {
"Version": "2012-10-17",
"Statement": [{
"Sid": "AllowHyperPodAccess",
"Effect": "Allow",
"Principal": {"AWS": HYPERPOD_ROLE_ARN},
"Action": ["s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucket"],
"Resource": [
f"arn:aws:s3:::{S3_BUCKET}",
f"arn:aws:s3:::{S3_BUCKET}/*"
]
}]
}
s3.put_bucket_policy(Bucket=S3_BUCKET, Policy=json.dumps(bucket_policy))第3步:准备训练数据集
Nova Forge SDK支持JSONL、JSON和CSV输入格式。本指南使用Hugging Face上公开的MedReason数据集,其中包含约32,700个医学推理问答对,用于演示针对特定领域的微调。
下载并清洗数据
Nova Forge SDK会对训练数据进行词元级别的验证。某些词元会与模型内部的对话模板产生冲突,具体来说是Nova用于在训练过程中分隔系统、用户和助手轮次的特殊分隔符。如果数据中包含System:或Assistant:等字面字符串,模型可能会将其误认为轮次边界,从而破坏训练信号。下面的清洗步骤在冒号前插入一个空格(如System: → System :)以打破模式匹配,同时保持可读性,并去除在模型词汇表中具有保留含义的特殊词元(如[EOS]和<image>)。
from huggingface_hub import hf_hub_download
import pandas as pd
import json
import re
# 下载数据集
jsonl_path = hf_hub_download(
repo_id="UCSC-VLAA/MedReason",
filename="ours_quality_33000.jsonl",
repo_type="dataset",
local_dir="."
)
df = pd.read_json(jsonl_path, lines=True)
# 与模型对话模板冲突的词元
INVALID_TOKENS = [
"System:", "SYSTEM:", "User:", "USER:", "Bot:", "BOT:",
"Assistant:", "ASSISTANT:", "Thought:", "[EOS]",
"<image>", "<video>", "<unk>",
]
def sanitize_text(text):
for token in INVALID_TOKENS:
if ":" in token:
word = token[:-1]
text = re.sub(rf'\b{word}:', f'{word} :', text, flags=re.IGNORECASE)
else:
text = text.replace(token, "")
return text.strip()
# 写入清洗后的JSONL
with open("training_data.jsonl", "w") as f:
for _, row in df.iterrows():
f.write(json.dumps({
"question": sanitize_text(row["question"]),
"answer": sanitize_text(row["answer"]),
}) + "\n")
print(f"Dataset saved: training_data.jsonl ({len(df)} examples)")如需验证数据中是否含有保留关键词,请运行此脚本。
使用SDK加载、转换并验证
SDK提供了JSONLDatasetLoader,可将原始数据格式转换为Nova模型所需的结构。调用transform()时,SDK会将每个问答对封装为Nova对话模板格式,即Nova模型在训练期间所期望的结构化多轮对话格式。您的原始数据将从简单的问答对转换为带有相应角色标签和分隔符的完整多轮对话。
转换前(原始JSONL):
{
"question": "What are the causes of chest pain in a 45-year-old patient?",
"answer": "Chest pain in a 45-year-old can result from cardiac causes such as..."
}转换后(Nova对话模板格式):
{
"messages": [
{"role": "user", "content": "What are the causes of chest pain in a 45-year-old patient?"},
{"role": "assistant", "content": "Chest pain in a 45-year-old can result from cardiac causes such as..."}
]
} validate()方法随后会检查转换后的数据,验证对话模板结构是否正确、是否存在无效词元,以及数据是否符合所选模型和训练方法的要求。
# 初始化加载器,映射列名
loader = JSONLDatasetLoader(
question="question",
answer="answer",
)
loader.load("training_data.jsonl")
# 预览原始数据
loader.show(n=3)
# 转换为Nova所需的对话模板格式
loader.transform(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
# 预览转换后的数据以验证结构
loader.show(n=3)
# 验证——成功时打印"Validation completed"
loader.validate(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
train_path = loader.save(f"{S3_DATA_PATH}/train.jsonl")
print(f"Training data: {train_path}")第4步:配置并启动数据混合训练
启用数据混合后,Nova Forge会在微调过程中自动将您的领域特定训练数据与Amazon精选数据集混合,从而在学习您的领域知识的同时,防止模型遗忘其通用能力。
关于训练方法的说明:LoRA与全秩SFT
Nova Forge支持多种微调方法。本指南使用带LoRA的监督微调(SFT)(TrainingMethod.SFT_LORA),这是一种参数高效方法,仅更新一小部分低秩适配器权重,而非全部模型参数。LoRA训练速度更快、计算成本更低,是大多数场景的推荐起点。
Nova Forge还支持全秩SFT,该方法会更新所有模型参数,可以融入更多领域知识。但它需要更多算力,也更容易出现灾难性遗忘(因此数据混合就更加重要)。本系列的上一篇文章展示了全秩SFT的实验结果。当LoRA无法实现足够的领域适应性,或者您需要更深度的模型适配时,可以选择全秩SFT。
配置运行时和MLflow
from amzn_nova_customization_sdk.model.model_enums import Platform
cluster_name = "nova-forge-hyperpod"
instance_type = "ml.p5.48xlarge"
instance_count = 4
namespace = "kubeflow"
runtime = SMHPRuntimeManager(
instance_type=instance_type,
instance_count=instance_count,
cluster_name=cluster_name,
namespace=namespace,
)
MLFLOW_APP_ID = "<your-mlflow-app-id>" # 例如:"app-XXXXXXXXXXXX"
mlflow_app_arn = f"arn:aws:sagemaker:{REGION}:{ACCOUNT_ID}:mlflow-app/{MLFLOW_APP_ID}"
mlflow_monitor = MLflowMonitor(
tracking_uri=mlflow_app_arn,
experiment_name="nova-sft-datamix",
)创建启用数据混合的定制器
构造NovaModelCustomizer时传入data_mixing_enabled=True:
customizer = NovaModelCustomizer(
model=Model.NOVA_LITE_2,
method=TrainingMethod.SFT_LORA,
infra=runtime,
data_s3_path=f"{S3_DATA_PATH}/train.jsonl",
output_s3_path=f"{S3_OUTPUT_PATH}/",
mlflow_monitor=mlflow_monitor,
data_mixing_enabled=True,
)理解并调整数据混合配置
数据混合控制训练批次的组成方式。customer_data_percent参数决定每个批次中来自您领域数据的比例。剩余部分由Nova精选数据集填充,每个nova_*_percent参数控制该能力类别在Nova部分中的相对权重。
例如,使用以下配置时:
- 每个训练批次的**50%**来自您的领域数据
- **50%**来自Nova精选数据,按各能力类别的相对权重分配
Nova侧的百分比之和必须为100。每个值代表该类别在批次Nova精选部分中所占的份额。
# 查看默认混合比例
customizer.get_data_mixing_config() 您可以根据优先级覆盖这些比例:
customizer.set_data_mixing_config({
"customer_data_percent": 50,
"nova_agents_percent": 1,
"nova_baseline_percent": 10,
"nova_chat_percent": 0.5,
"nova_factuality_percent": 0.1,
"nova_identity_percent": 1,
"nova_long-context_percent": 1,
"nova_math_percent": 2,
"nova_rai_percent": 1,
"nova_instruction-following_percent": 13,
"nova_stem_percent": 10.5,
"nova_planning_percent": 10,
"nova_reasoning-chat_percent": 0.5,
"nova_reasoning-code_percent": 0.5,
"nova_reasoning-factuality_percent": 0.5,
"nova_reasoning-instruction-following_percent": 45,
"nova_reasoning-math_percent": 0.5,
"nova_reasoning-planning_percent": 0.5,
"nova_reasoning-rag_percent": 0.4,
"nova_reasoning-rai_percent": 0.5,
"nova_reasoning-stem_percent": 0.4,
"nova_rag_percent": 1,
"nova_translation_percent": 0.1,
})如何思考混合比例的调整
| 参数 | 控制内容 | 调整建议 |
|---|---|---|
customer_data_percent | 每个训练批次中领域数据的占比 | 较高值会带来更强的领域专业化,但会增加遗忘风险。50%是平衡的起点 |
nova_instruction-following_percent | Nova部分中指令遵循示例的权重 | 若生产环境中模型需要遵循结构化提示或输出格式,请保持较高值 |
nova_reasoning-*_percent | 各推理能力的权重(数学、代码、规划等) | 若下游任务需要多步骤推理,请增加这些值 |
nova_rai_percent | 负责任AI对齐数据 | 始终保持非零值,以保留安全行为 |
nova_baseline_percent | 核心事实知识 | 有助于保留广泛的世界知识 |
提示: 从默认值开始,运行一次训练任务,分别在领域任务和MMLU上进行评估,然后迭代调整。Building specialized AI without sacrificing intelligence一文表明,即使是75/25的客户数据与Nova数据混合比例,也能保持接近基准的MMLU分数(0.74 vs. 基准0.75),同时在复杂分类任务上实现F1分数12个百分点的提升。
启动训练任务
overrides参数可控制关键训练超参数:
| 参数 | 描述 | 调整建议 |
|---|---|---|
lr | 学习率 | 1e-5是LoRA微调的合理默认值 |
warmup_steps | 从0线性增加学习率的步数 | 通常为总步数的5-10%,与max_steps成比例设置 |
global_batch_size | 所有GPU上每次梯度更新的样本数 | 较大批次梯度更稳定,但内存消耗更多 |
max_length | 最大序列长度(词元数) | 根据数据设置。65536支持长上下文场景;对于较短的数据可减小该值,以节省内存并加快训练速度 |
max_steps | 总训练步数 | 从小值(5-10)开始验证设置,然后增大。对于约23,000个训练样本、批次大小32,一个完整epoch约720步 |
training_config = {
"lr": 1e-5,
"warmup_steps": 2,
"global_batch_size": 32,
"max_length": 65536,
"max_steps": 5, # 从小值开始验证;生产运行时增大
}
training_result = customizer.train(
job_name="nova-forge-sft-datamix",
overrides=training_config,
)
training_result.dump("training_result.json")
print("Training result saved")监控训练进度
可以通过SDK或CloudWatch监控任务:
# 查看任务状态
print(training_result.get_job_status())
# 流式查看最新日志
customizer.get_logs(limit=50, start_from_head=False)
# 或使用CloudWatch监控器
monitor = CloudWatchLogMonitor.from_job_result(training_result)
monitor.show_logs(limit=10)
# 轮询直至完成
import time
while training_result.get_job_status()[1] == "Running":
time.sleep(60) 训练指标(损失曲线、学习率计划表)也可在MLflow实验中查看,便于可视化和跨运行对比。
第5步:评估微调后的模型
使用数据混合时,评估至关重要,因为您需要同时衡量两方面:模型在领域任务上是否有所改进,以及是否保留了通用能力。如果只评估一个维度,就无法判断混合是否有效。训练完成后,从输出清单中获取模型检查点位置:
from amzn_nova_forge.util.checkpoint_util import extract_checkpoint_path_from_job_output
checkpoint_path = extract_checkpoint_path_from_job_output(
output_s3_path=training_result.model_artifacts.output_s3_path,
job_result=training_result,
)配置评估基础设施
评估仅需一台GPU实例(相比训练的4台):
eval_infra = SMHPRuntimeManager(
instance_type=instance_type,
instance_count=1,
cluster_name=cluster_name,
namespace=namespace,
)
eval_mlflow = MLflowMonitor(
tracking_uri=mlflow_app_arn,
experiment_name="nova-forge-eval",
)
evaluator = NovaModelCustomizer(
model=Model.NOVA_LITE_2,
method=TrainingMethod.EVALUATION,
infra=eval_infra,
output_s3_path=f"s3://{S3_BUCKET}/demo/eval-outputs/",
mlflow_monitor=eval_mlflow,
)运行评估
Nova Forge支持三种互补的评估方法:
1. 公共基准测试(用于衡量通用能力的保留情况)
这些测试能告诉您数据混合是否发挥作用。若MMLU相比基准显著下降,则需要在混合中加入更多Nova数据;若IFEval下降,则需要提高指令遵循权重。
# MMLU——覆盖57个学科的广泛知识与推理能力
mmlu_result = evaluator.evaluate(
job_name="eval-mmlu",
eval_task=EvaluationTask.MMLU,
model_path=checkpoint_path,
)
# IFEval——遵循结构化指令的能力
ifeval_result = evaluator.evaluate(
job_name="eval-ifeval",
eval_task=EvaluationTask.IFEVAL,
model_path=checkpoint_path,
)2. 自带数据(衡量领域特定性能)
使用保留的测试集衡量微调是否提升了实际任务的性能:
byod_result = evaluator.evaluate(
job_name="eval-byod",
eval_task=EvaluationTask.GEN_QA,
data_s3_path=f"s3://{S3_DATA_PATH}/eval/gen_qa.jsonl",
model_path=checkpoint_path,
overrides={"max_new_tokens": 2048},
)3. 大语言模型(LLM)作为评判者(对于自动化指标不足的领域,可使用另一个LLM来评估响应质量)
查看结果并获取输出
# 查看任务状态
print(mmlu_result.get_job_status())
print(ifeval_result.get_job_status())
print(byod_result.get_job_status())
# 获取包含详细评估结果的S3路径
print(mmlu_result.eval_output_path) 评估输出路径包含JSON格式的详细结果。下载并查看以获取实际分数。
此外,通过在创建任务时提供追踪服务器URI,可将指标发布到MLflow追踪服务器。通过这种方式,您可以记录并存储指标,用于跨实验对比。
解读结果
使用以下决策框架指导下一次迭代:
| 观察结果 | 含义 | 调整建议 |
|---|---|---|
| MMLU接近基准(如在0.01-0.02范围内) | 数据混合成功防止了灾难性遗忘 | 混合配置有效——聚焦于领域性能 |
| MMLU显著下降 | 模型正在遗忘通用能力 | 降低customer_data_percent或增加Nova数据权重 |
| 领域任务性能低于预期 | 模型从您的数据中学习不足 | 增加customer_data_percent、添加更多训练数据或增加max_steps |
| IFEval下降 | 模型正在失去指令遵循能力 | 增加nova_instruction-following_percent |
| MMLU和领域任务均有提升 | 理想结果 | 记录配置并推广到生产环境 |
作为参考,此文报告了Amazon Nova 2 Lite在VOC分类任务上的结果:
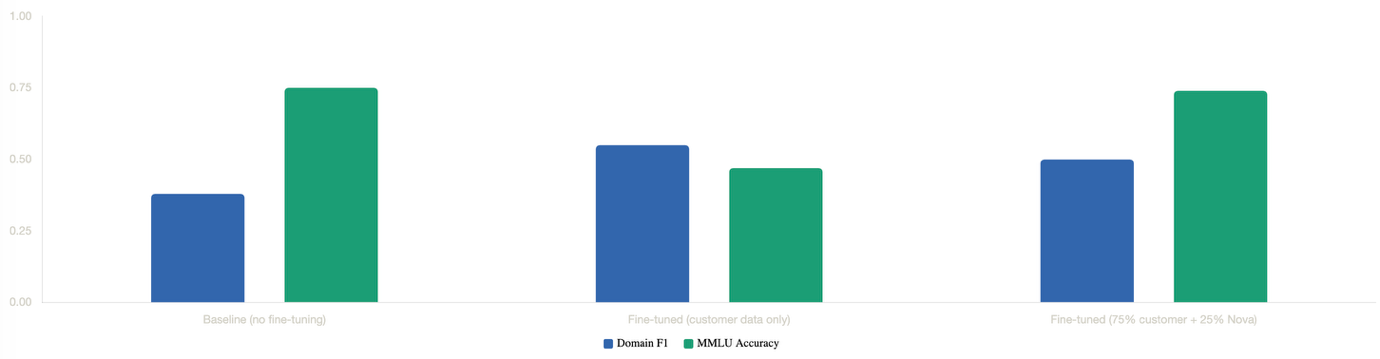
核心结论是:仅在客户数据上微调会提升领域F1分数,但会大幅降低通用智能(MMLU从0.75降至0.47);而混合方式(75%客户数据 + 25% Nova数据)则几乎恢复了全部MMLU准确率,同时仍能改善领域性能。
最佳实践
- 从默认混合比例开始。 默认值已针对平衡的权衡关系进行了调整。只有在有基准评估结果可供对比后,才进行自定义配置。
- 始终从两个维度进行评估。 至少运行一项公共基准测试(MMLU)与您的领域特定评估同步进行。没有两者的对比,就无法判断混合是否有效。
- 使用MLflow对比实验。 在迭代混合比例和超参数时,MLflow可以方便地并排对比运行结果,找出最佳配置。
- 迭代混合比例,而不仅仅是超参数。 如果模型正在遗忘通用能力,调整数据混合比例通常比调整学习率或批次大小更有效。
- 从LoRA开始,必要时再转向全秩。 LoRA更快更便宜。只有当LoRA无法为您的用例实现足够的领域适应时,才考虑全秩SFT。
清理资源
为避免持续产生费用,请清理本指南中创建的资源:
- 删除S3存储桶及其内容。
- 如果HyperPod集群是为本练习创建的,请停止或删除它。
- 如果不再需要MLflow应用,请将其删除。
结论
本文介绍了使用Nova Forge SDK和数据混合功能对Amazon Nova模型进行端到端微调的完整工作流。SDK负责处理数据准备、SageMaker HyperPod上的训练编排以及多维度评估,让您可以专注于数据和领域本身。数据混合是使微调在生产中切实可行的关键。您不必在领域专业知识和通用智能之间做出选择,而是可以两者兼得。关键在于将其视为一个迭代过程:训练、从两个维度评估、调整混合比例,不断重复,直到找到适合您用例的最佳平衡点。
如需入门,请参阅Nova Forge开发者指南获取详细文档,并探索Nova Forge SDK获取完整API参考。