原文标题:Long-running Claude for scientific computing
原文链接:https://www.anthropic.com/research/long-running-Claude
作者:Siddharth Mishra-Sharma(Discovery 团队研究员) 发布时间:2026 年 3 月 23 日
长时间运行的 Claude 用于科学计算
科学家通常以对话方式管理 AI Agent,逐步控制每个环节。随着模型在长周期任务能力上的持续提升,一种全新的工作流成为可能:只需指定高层目标,然后让一组 Agent 自主工作。这种方式特别适合那些范围明确、有清晰成功标准的科学任务,比如重新实现数值求解器、现代化遗留代码,或对照参考实现进行调试。
Anthropic 的 C 编译器项目在约 2,000 个会话中展示了这种模式。本文将描述如何在学术实验室环境下,使用 Claude Code 对科学计算任务进行类似的编排。我们以实现一个可微分的宇宙学 Boltzmann 求解器为例——这是一段数值代码,通过演化光子、重子、中微子和暗物质的耦合方程来预测宇宙微波背景(CMB)的性质。
像 CLASS 和 CAMB 这样的 Boltzmann 求解器构成了宇宙学的核心基础设施。可微分版本可以实现基于梯度的推断,从而大幅加速参数估计。JAX 实现提供了自动微分和 GPU 兼容性。这项任务超出了作者的领域专长,而拥有这种专长的研究组通常需要”数月乃至数年的研究时间”来完成类似工作。

起草计划并在本地迭代
有效的自主研究需要在项目根目录的 CLAUDE.md 文件中投入精力撰写清晰的指令。Claude 会特殊对待这个文件,在上下文中持续维护它,并允许随着工作推进进行迭代优化。经过最初的几次尝试后,作者与 Claude 反复迭代,直到建立了合理的规格说明:实现与 CLASS 完全功能对等,同时保持完全可微分性,主要交付物对照 CLASS 的精度目标为 0.1%——这与标准 Boltzmann 代码之间的典型一致性水平相当。
跨会话记忆
CHANGELOG.md 进度文件充当了可移植的长期记忆,记录类似实验笔记的内容。有效的进度追踪应包括:当前状态、已完成任务、失败方法及其原因、精度检查点和已知限制。记录失败的方法可以防止后续会话重复尝试已经证明行不通的路线。示例条目:“尝试对扰动 ODE 使用 Tsit5,系统刚性太强。改用 Kvaerno5。“
Test Oracle(测试基准)
长时间运行的自主科学工作需要让 Agent 有机制来评估自身进展。对于科学代码来说,这意味着参考实现、可量化的目标或现有的测试套件。在本例中,作者指示 Claude 使用 CLASS 的 C 源代码作为参考实现来构建和持续运行单元测试。
Git 作为协调工具
Git 能够实现免手动的进度监控和协调。Agent 应该在完成有意义的工作单元后提交并推送代码,这既提供了可恢复的历史记录,也能防止计算资源配额在会话中途过期时丢失进度。指令可以这样指定:
“在每个有意义的工作单元完成后提交并推送。每次提交前运行
pytest tests/ -x -q。永远不要提交会破坏现有通过测试的代码。”
仍然可以通过 SSH 进入集群或通过本地 Claude Code 实例执行远程命令来进行手动引导。
执行循环
在本地迭代完成后,在计算节点上通过终端复用器(如 tmux)启动 Claude Code。示例 SLURM 作业脚本:
#!/bin/bash
#SBATCH --job-name=claude-agent
#SBATCH --partition=GPU-shared
#SBATCH --gres=gpu:h100-32:1
#SBATCH --time=48:00:00
#SBATCH --output=agent_%j.log
cd $PROJECT/my-solver
source .venv/bin/activate
export TERM=xterm-256color
tmux new-session -d -s claude "claude; exec bash"
tmux wait-for claude重新接入:
srun --jobid=JOBID --overlap --pty tmux attach -t claudeRalph Loop
模型可能会表现出”Agent 惰性”——找借口在完成多部分任务之前停下来。Ralph Loop 编排模式会迭代地重新提示声称已完成的 Agent,询问它是否”真的完成了”。其他模式还包括 GSD 和特定领域的变体,以及 Claude Code 原生的 /loop 命令。
通过 /plugin 安装 Ralph 后,可以这样调用:
/ralph-loop:ralph-loop "Please keep working on the task until the
success criterion of 0.1% accuracy across the entire parameter range
is achieved." --max-iterations 20 --completion-promise "DONE"成果
Claude 在数天内开发了该项目,在各项输出上实现了与 CLASS 的亚百分比一致性。重建的精度图展示了向亚百分比精度逐步推进的轨迹,并标注了各开发里程碑。
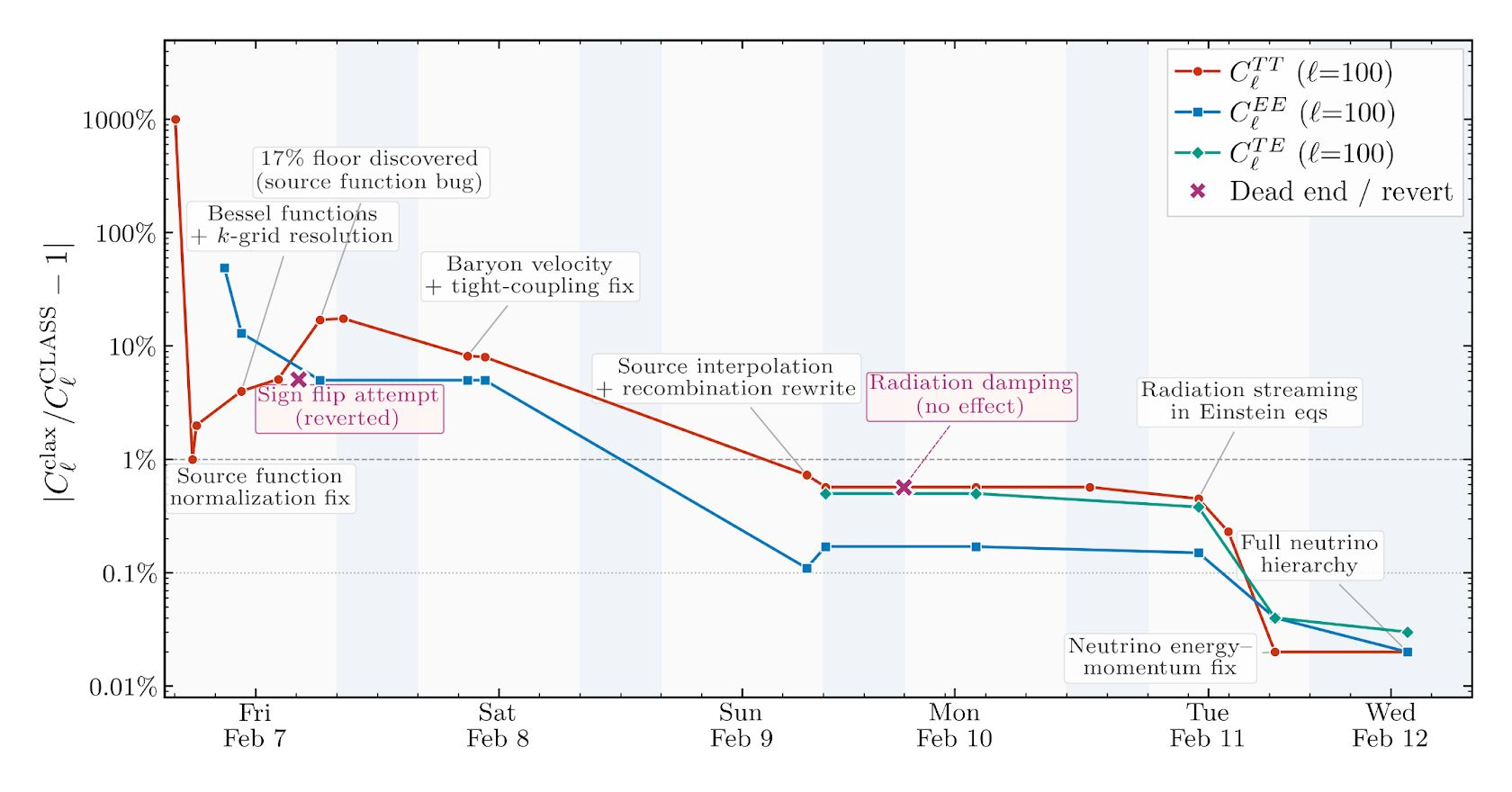
开发轨迹存在不完美之处——最初只在单个参数点进行测试,犯了一些基本错误,在领域专家能快速识别的问题上花了好几个小时。尽管如此,“它持续朝着亚百分比精度的既定目标稳步推进。”
作者通过观察提交历史来学习 Boltzmann 求解器的物理学,跟踪 Claude 的增量进展并研究不熟悉的概念。提交日志读起来像是”一位快速而超级忠实的博士后的实验笔记”。
虽然该求解器尚未达到生产级质量,但它表明”Agent 驱动的开发可以将数月甚至数年的研究工作压缩到数天内完成。“
结论
这种压缩改变了空闲时间的经济学。当项目拥有明确的成功标准和可用的计算资源时,每一个没有让 Agent 运行的夜晚都意味着”被搁置的潜在进展”。
致谢
感谢 Eric Kauderer-Abrams 的同行评审,以及 Xander Balwit、Ethan Dyer 和 Rebecca Hiscott 的反馈。
引用
- 原文:Long-running Claude for scientific computing(Anthropic Research,2026-03-23)
- Anthropic Science Blog