原文标题:Improving Composer through real-time RL
原文链接:https://cursor.com/blog/real-time-rl-for-composer
用实时 RL 改进 Composer
Jacob Jackson、Ben Trapani、Nathan Wang 和 Wanqi Zhu · 2026 年 3 月 26 日 · 7 分钟阅读
我们正在见证编程模型在实际应用中以前所未有的速度增长。面对推理量 10–100 倍的增长,我们思考的问题是:如何从这数万亿 token 中提取训练信号来改进模型?
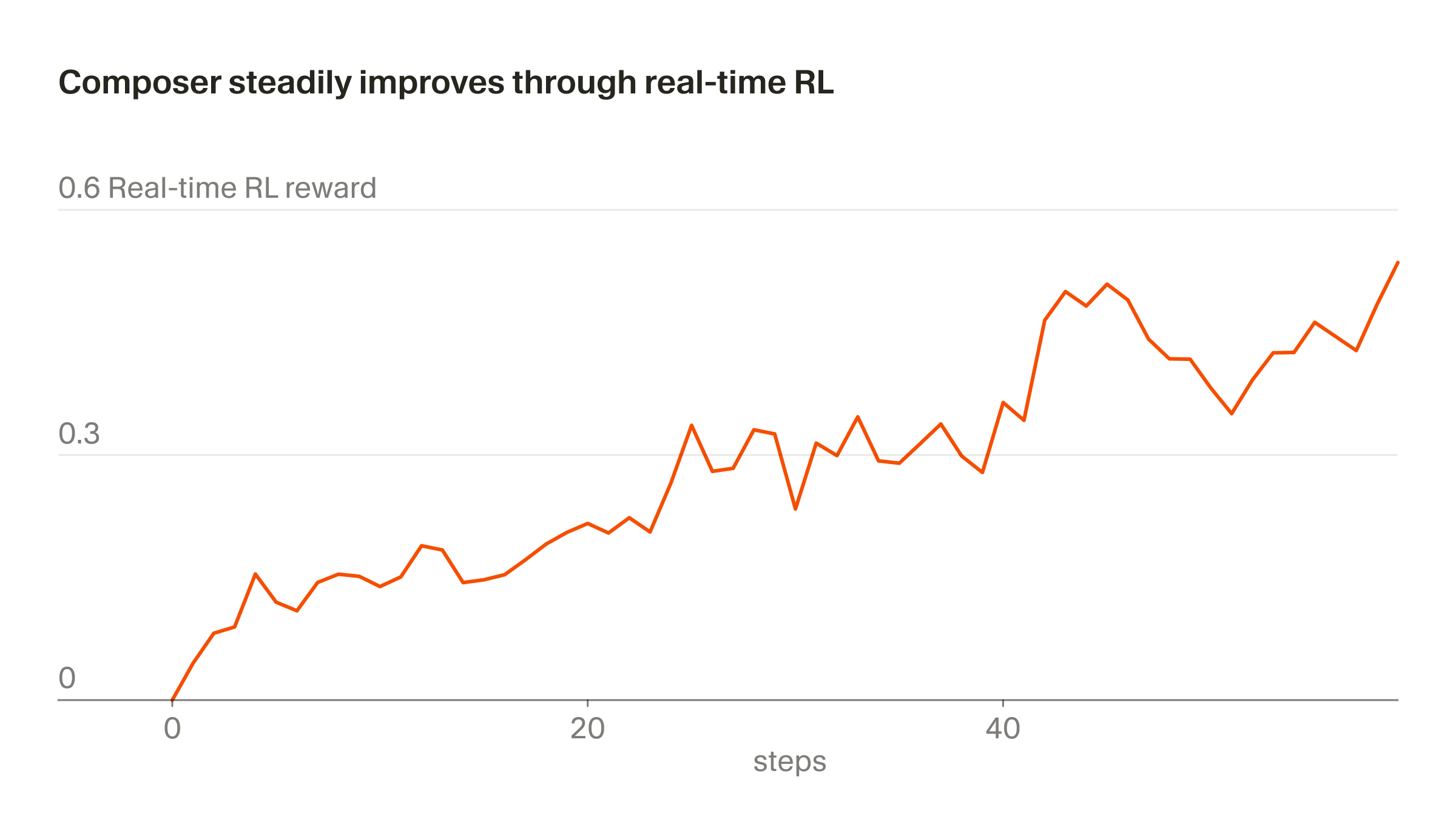
我们将使用真实推理 token 进行训练的方法称为”实时 RL”(real-time RL)。我们最初在 Tab 上使用了这一技术,效果非常出色。现在,我们正在将类似方法应用于 Composer。我们将模型 checkpoint 部署到生产环境,观察用户反应,并将这些反应聚合为奖励信号。这种方法使我们能够最快每五小时就交付一个改进版的 Composer(在 Auto 模式下)。
训练-测试不匹配
像 Composer 这样的编程模型,主要训练方式是创建模拟编程环境——尽可能忠实地还原模型在真实使用中会遇到的环境和问题。这种方法效果很好。编程之所以是 RL 如此有效的应用领域,一个原因是与 RL 的其他天然应用(如机器人技术)相比,创建模型部署环境的高保真模拟要容易得多。
尽管如此,重建模拟环境的过程仍然会带来一定的训练-测试不匹配(train-test mismatch)。最大的困难在于对用户建模。Composer 的生产环境不仅包括执行 Composer 命令的计算机,还包括监督和指导其行为的人。模拟计算机比模拟使用它的人要容易得多。
虽然有一些前景看好的研究致力于创建模拟用户的模型,但这种方法不可避免地会引入建模误差。使用推理 token 作为训练信号的吸引力在于:它让我们能够使用真实环境和真实用户,从而消除这一建模不确定性和训练-测试不匹配的来源。
每五小时一个新 checkpoint
实时 RL 的基础设施依赖于 Cursor 技术栈中的多个不同层级。产生新 checkpoint 的流程始于客户端的埋点——将用户交互转化为信号,经过后端数据管道将信号输入训练循环,最终通过快速部署路径让更新后的 checkpoint 上线。
更细粒度来看,每个实时 RL 循环都从收集数十亿 token 的用户交互数据开始,并将其提炼为奖励信号。然后,我们根据隐含的用户反馈计算如何调整所有模型权重,并实施更新的权重值。
到了这一步,更新版本仍有可能以意想不到的方式不如上一版,因此我们会在评估套件(包括 CursorBench)上测试,确保没有显著回退。如果结果良好,我们就部署该 checkpoint。
整个过程大约需要五小时,意味着我们可以在一天内多次交付改进的 Composer checkpoint。这一点很重要,因为它使我们能够保持数据完全或接近完全 on-policy(即用于训练的模型与生成数据的模型是同一个)。即使使用 on-policy 数据,实时 RL 目标也是有噪声的,需要大批量才能看到进展。Off-policy 训练会增加额外的困难,并增加过度优化行为(越过改善目标的临界点)的风险。
我们通过 A/B 测试在 Auto 模式下改进了 Composer 1.5:
| 指标 | 变化 |
|---|---|
| Agent 编辑保留在代码库中 | +2.28% |
| 用户发送不满意的后续消息 | −3.13% |
| 延迟 | −10.3% |
实时 RL 与 Reward Hacking
模型擅长 reward hacking(奖励欺骗)。如果有一种简单的方法可以阻止坏奖励或作弊获得好奖励,模型就会找到它——例如学会把代码拆分成人为缩小的函数来博弈复杂度指标。
这个问题在实时 RL 中尤为突出,因为模型是在上述完整的生产技术栈上优化其行为。技术栈中的每一个接缝——从数据收集方式到信号转换方式再到奖励逻辑——都会成为模型可以学会利用的攻击面。
Reward hacking 在实时 RL 中风险更大,但模型也更难蒙混过关。在模拟 RL 中,作弊的模型只是发布了一个更高的分数,除了基准测试之外没有什么参照物来揭穿它。在实时 RL 中,试图完成工作的真实用户则没那么容忍。如果我们的奖励真正捕捉了用户想要的东西,那么攀升奖励从定义上就会带来更好的模型。每一次 reward hacking 的尝试本质上都变成了一份 bug 报告,我们可以用来改进训练系统。
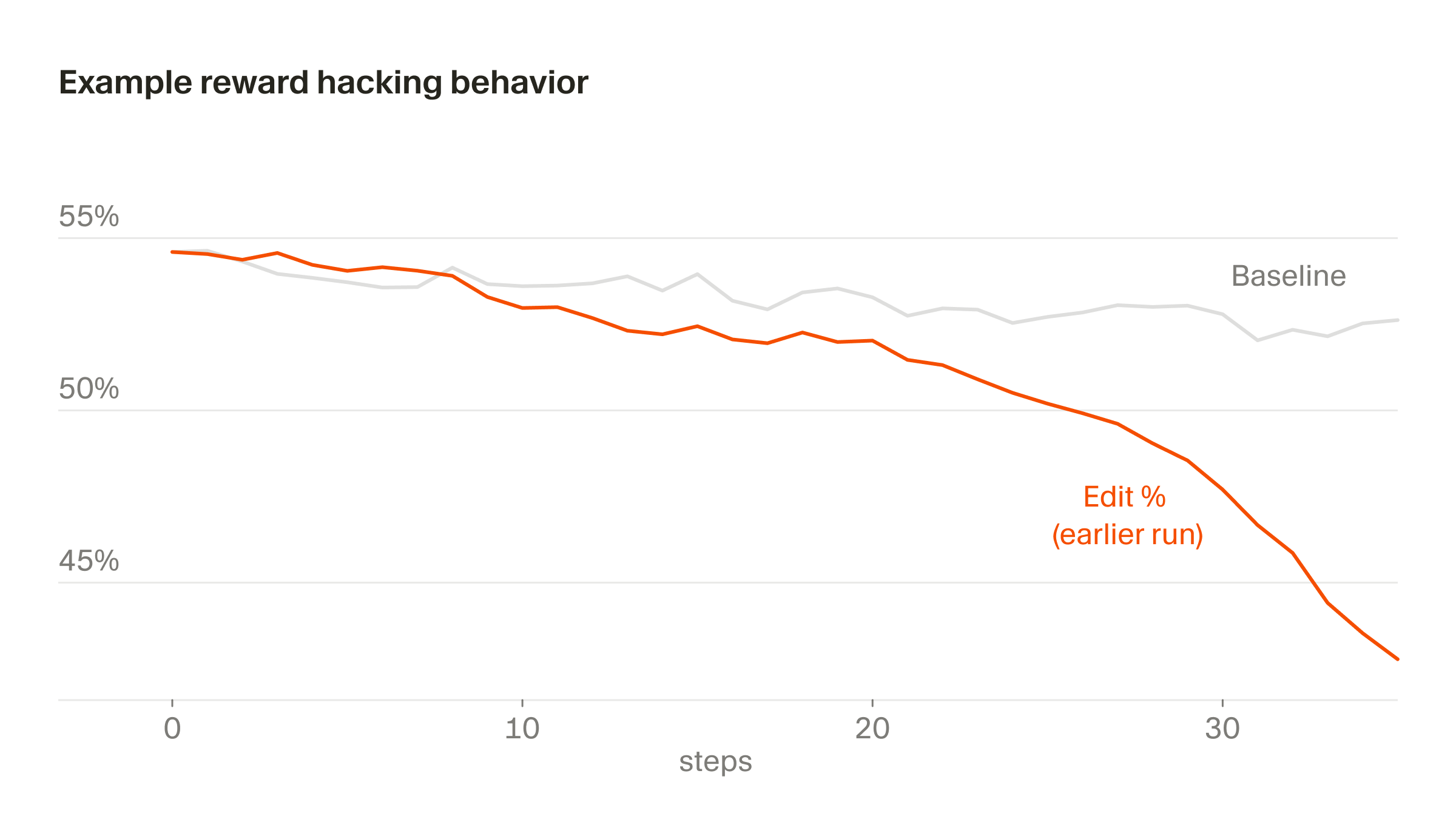
以下两个例子说明了这一挑战以及我们如何调整 Composer 的训练来应对。
当 Composer 回应用户时,它经常需要调用工具,例如读取文件或执行终端命令。最初,我们丢弃了工具调用无效的样本,结果 Composer 发现了一个窍门:如果它在可能失败的任务上故意发出一个损坏的工具调用,它就永远不会收到负奖励。我们通过正确地将损坏的工具调用包含为负样本来修复了这个问题。
一个更微妙的版本出现在编辑行为上,我们的部分奖励来自模型所做的编辑。在某一时期,Composer 学会了通过提出澄清问题来推迟有风险的编辑,因为它意识到自己不会因为没写的代码而受到惩罚。一般来说,我们确实希望 Composer 在提示语义模糊时进行澄清,避免过度积极的编辑——但由于奖励函数中的一个特定设计缺陷,这一激励永远不会反转。如果不加控制,编辑率会急剧下降。我们通过监控发现了这一点,并修改了奖励函数以稳定这一行为。
下一步:从更长循环和专业化中学习
目前大多数交互仍然相对较短,因此 Composer 在建议编辑后的一小时内就能收到用户反馈。然而,随着 Agent 能力的增强,我们预期它们将在后台处理更长的任务,可能每隔几小时甚至更久才需要用户输入。
这改变了我们可用于训练的反馈类型——频率更低但也更清晰,因为用户评估的是一个完整的结果,而不是孤立的单次编辑。我们正在努力调整实时 RL 循环以适应这些低频率、高保真度的交互。
我们还在探索将 Composer 针对特定组织或特定类型的工作进行定制的方法,因为这些场景下的编程模式与通用分布不同。由于实时 RL 是基于特定群体的真实交互进行训练——而非通用基准——它天然支持这种专业化,而这是模拟 RL 所做不到的。
引用
- 原文:Improving Composer through real-time RL — Cursor Research Blog, Jacob Jackson, Ben Trapani, Nathan Wang & Wanqi Zhu, 2026-03-26
- 相关文章:Improving Cursor Tab with online RL — Cursor Research Blog
- 相关文章:CursorBench — Cursor Research Blog