原文标题:Best practices to run inference on Amazon SageMaker HyperPod
原文链接:https://aws.amazon.com/blogs/machine-learning/best-practices-to-run-inference-on-amazon-sagemaker-hyperpod/
为组织部署和扩展基础模型进行生成式 AI 推理面临重重挑战。团队往往在复杂的基础设施配置上举步维艰,流量的不可预测性导致资源过度供给或性能瓶颈,同时高效管理 GPU 资源的运维负担也不堪重负。这些痛点造成产品上市时间延迟、模型性能不达预期,以及不断攀升的成本——这些因素叠加在一起,可能使 AI 计划在规模化阶段难以为继。
本文探讨 Amazon SageMaker HyperPod 如何通过提供一套完整的推理工作负载解决方案来应对上述挑战。我们将带您深入了解该平台在动态扩缩容、简化部署和智能资源管理方面的核心能力。读完本文,您将掌握如何利用 HyperPod 的自动化基础设施、成本优化功能和性能增强特性,在将总体拥有成本降低最高 40% 的同时,加速您的生成式 AI 部署从概念走向生产。
集群创建——一键部署
要使用 Amazon Elastic Kubernetes Service(Amazon EKS)编排创建 HyperPod 集群,请在 Amazon SageMaker AI 控制台中导航至 SageMaker HyperPod 集群页面。
步骤 1:
选择创建 HyperPod 集群,然后选择由 Amazon EKS 编排选项。
步骤 2
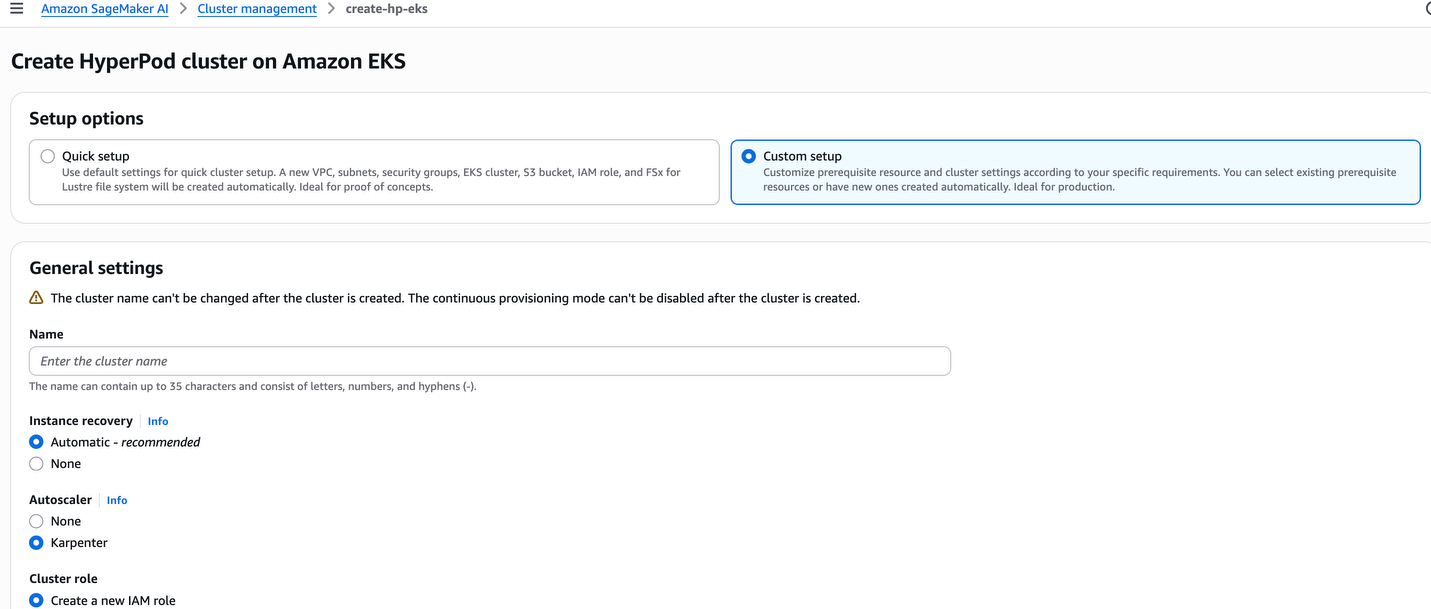
选择快速设置或自定义设置选项。快速设置选项会创建默认资源,而自定义设置选项则允许您与现有资源集成,或根据特定需求自定义配置。
步骤 3
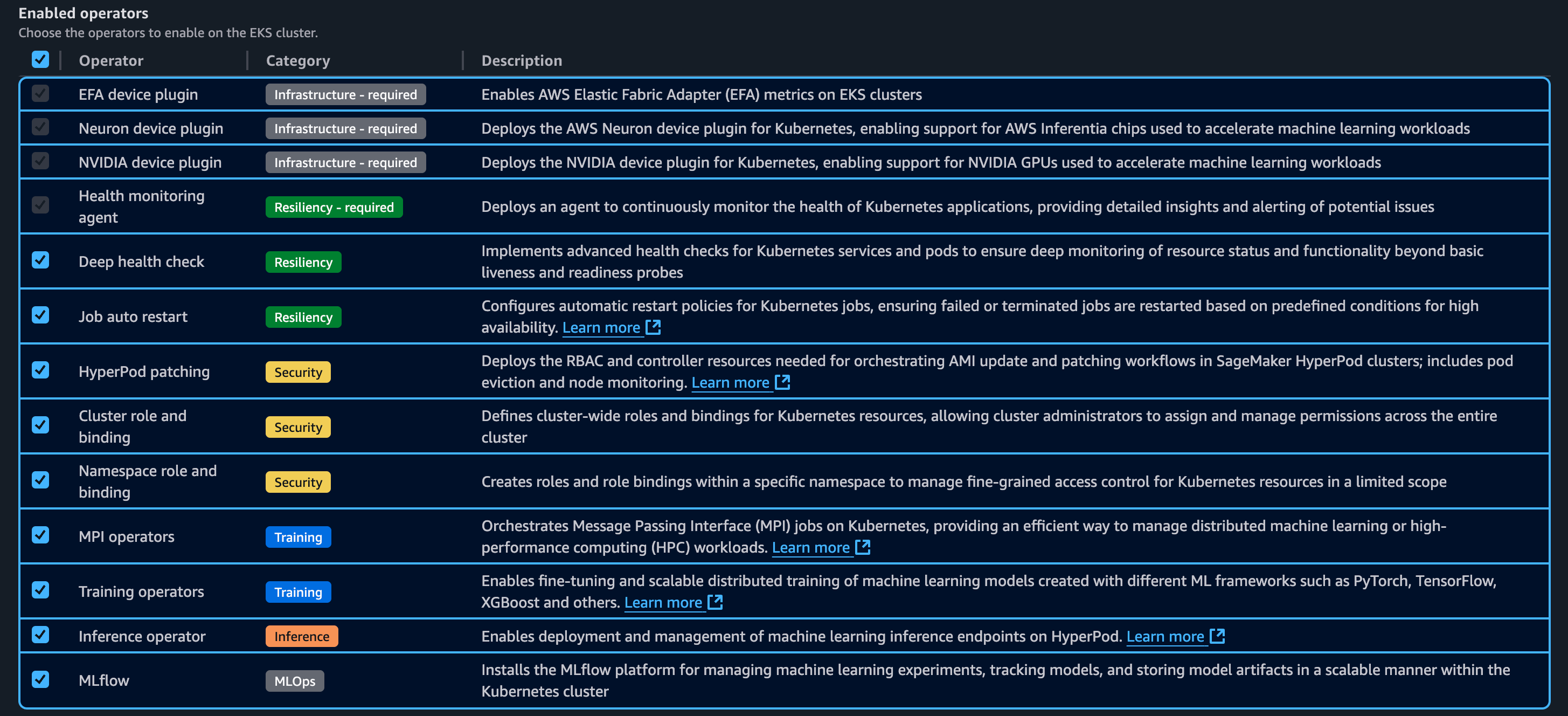
以下是 Kubernetes 控制器和附加组件。这些控制器和附加组件可以按需启用或禁用。
步骤 4
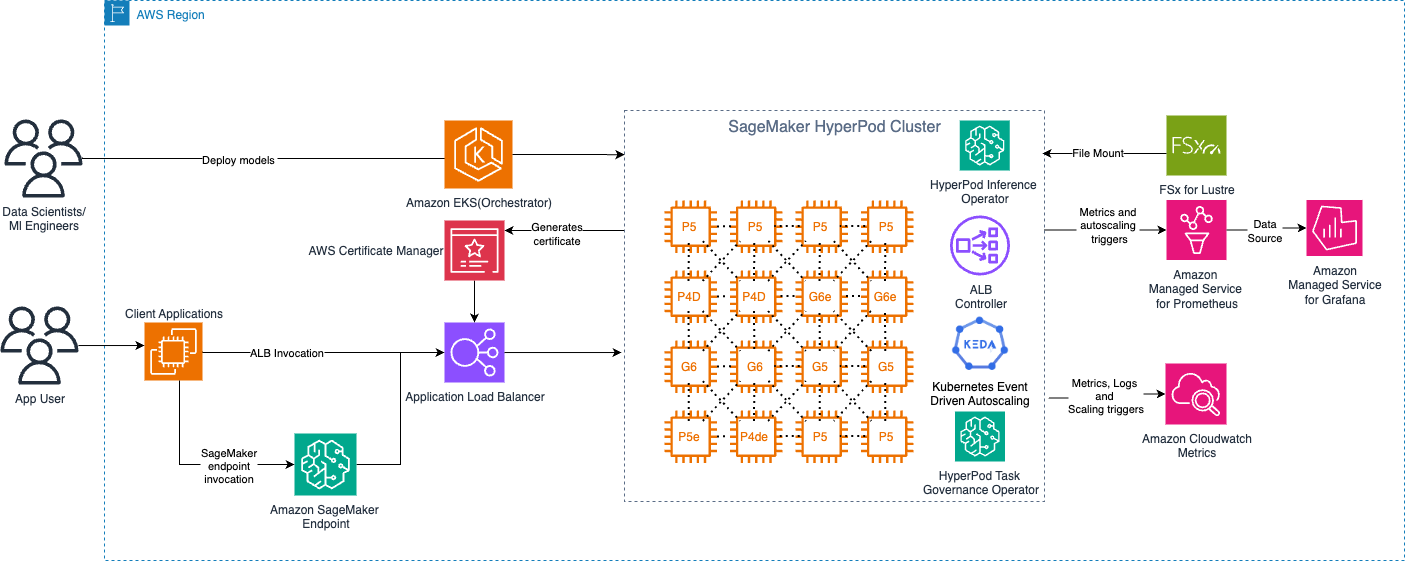
下图展示了使用 Amazon EKS 编排控制平面的 SageMaker HyperPod 高层架构。
部署选项
Amazon SageMaker HyperPod 现已提供完整的推理平台,将 Kubernetes 的灵活性与 AWS 托管服务融为一体。您可以在整个模型生命周期内,以生产级可靠性完成机器学习模型的部署、扩缩容和优化。该平台提供灵活的部署接口、高级自动扩缩容功能和全面的监控特性。借助推理部署算子,您无需编写代码即可从 S3 存储桶、FSx for Lustre 和 JumpStart 部署模型。
- 从 SageMaker JumpStart 部署(示例代码 Notebook)
- 部署
InferenceEndpointConfig模型 - 从 S3 部署自定义或微调模型(示例代码 Notebook)
- 从 FSx Lustre 部署自定义或微调模型(示例代码 Notebook)
使用 Karpenter 进行自动扩缩容
Amazon SageMaker HyperPod 提供了一套自动扩缩容架构,将 KEDA(Kubernetes 事件驱动自动扩缩容)用于 Pod 级别的扩缩容,将 Karpenter 用于节点级别的扩缩容。这种双层架构实现了动态、高性价比的基础设施,能够根据实时需求从零扩展至生产工作负载。
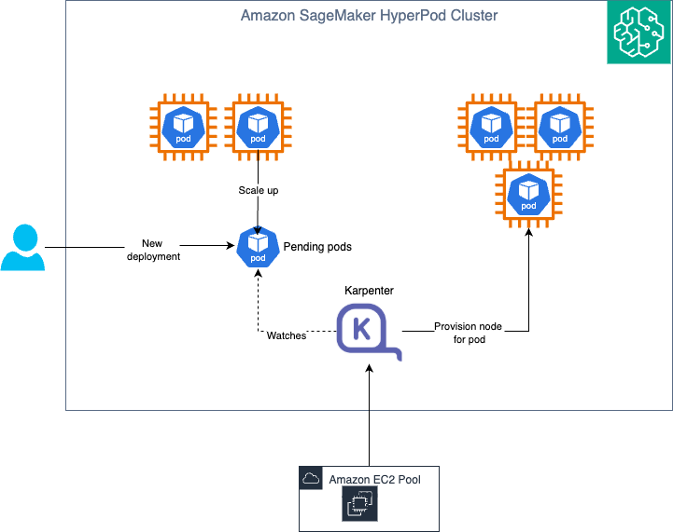
使用 KEDA 和 Karpenter 的精细化自动扩缩容
了解自动扩缩容架构
Pod 扩缩容(KEDA): KEDA(Kubernetes 事件驱动自动扩缩容)是一个开源的云原生计算基金会(CNCF)项目,它为 Kubernetes 扩展了事件驱动的自动扩缩容能力。KEDA 作为 HyperPod 推理算子的一部分自动安装,无需单独安装或配置即可提供开箱即用的 Pod 自动扩缩容。KEDA 根据请求队列长度、Amazon CloudWatch 指标(如 SageMaker 端点调用次数)、延迟或自定义 Prometheus 指标等度量标准来扩缩推理 Pod 的数量。在没有流量时,它可以将部署缩减至零个 Pod,消除闲置期间的费用。
节点扩缩容(Karpenter): Karpenter 是一个 Kubernetes 集群自动扩缩容器,它根据待调度 Pod 的需求来配置或移除计算节点。Karpenter 运行在 Amazon EKS 控制平面中,这意味着运行自动扩缩容器本身无需额外的计算费用。这种控制平面部署模式实现了真正的缩减至零能力。当 KEDA 因无流量而将 Pod 缩减至零时,Karpenter 可以移除所有工作节点,确保在闲置期间不产生任何基础设施费用。
KEDA 与 Karpenter 如何协同工作
KEDA 与 Karpenter 的集成创造了一种高效的自动扩缩容体验。ADOT(AWS OpenTelemetry 发行版)收集器从推理 Pod 抓取指标,并将其推送至 Amazon Managed Service for Prometheus 或 CloudWatch。KEDA 算子(随推理算子一同安装)会定期轮询这些指标,并与您在 JumpStartModel 或 InferenceEndpointConfig YAML 中定义的触发阈值进行比对。当指标超过阈值时,KEDA 触发水平 Pod 自动扩缩容器(HPA)创建新的推理 Pod;若这些 Pod 因节点容量不足而处于待调度状态,运行在控制平面中的 Karpenter 会检测到这一情况,并配置具有合适实例类型和 GPU 配置的新节点。Kubernetes 调度器随后将待调度的 Pod 部署到新配置的节点上,在扩展后的基础设施间分发推理流量。当需求下降时,KEDA 根据相同的指标缩减 Pod,Karpenter 则整合工作负载并移除利用率不足的节点以降低基础设施成本。在无流量期间,KEDA 可以将 Pod 缩减至零,Karpenter 移除所有工作节点,实现零计算费用,同时保持在流量恢复时快速扩容的能力。这套架构确保您只需为推理请求被主动服务时消耗的计算资源付费,而自动扩缩容基础设施本身不产生额外费用,因为 Karpenter 运行在托管控制平面中。
确认集群执行角色具备以下策略:"sagemaker:BatchAddClusterNodes"、"sagemaker:BatchDeleteClusterNodes"、"sagemaker:BatchPutMetrics",作用于以下资源:"arn:aws:sagemaker:us-east-1:actxxxxxxxx:cluster/*"、"arn:aws:sagemaker:us-east-1:actxxxxxxx:cluster/sagemaker-ml-cluster-e3cb1e31-eks"
启用 Karpenter——运行以下命令:
aws sagemaker update-cluster \
--cluster-name 'ml-cluster' \
--auto-scaling '{ "Mode": "Enable", "AutoScalerType": "Karpenter" }' \
--cluster-role 'arn:aws:iam::XXXXXXXXXXXX:role/sagemaker-ml-cluster-e3cb1e31ExecRole' \
--region us-east-1以下是成功的输出示例:
{
"ClusterArn": "arn:aws:sagemaker:us-east-1:XXXXXXXXXXXX:cluster/4dehnrxxettz"
}运行此命令并更新集群后,您可以通过运行 DescribeCluster API 验证 Karpenter 是否已启用:
aws sagemaker describe-cluster \
--cluster-name ml-cluster \
--query AutoScaling \
--region us-east-1{
"Mode": "Enable",
"AutoScalerType": "Karpenter",
"Status": "InService",
"FailureMessage": ""
}KV 缓存与智能路由
Amazon SageMaker HyperPod 现在支持托管分层 KV 缓存和智能路由,以优化大型语言模型(LLM)推理性能,尤其适用于长上下文提示和多轮对话场景。
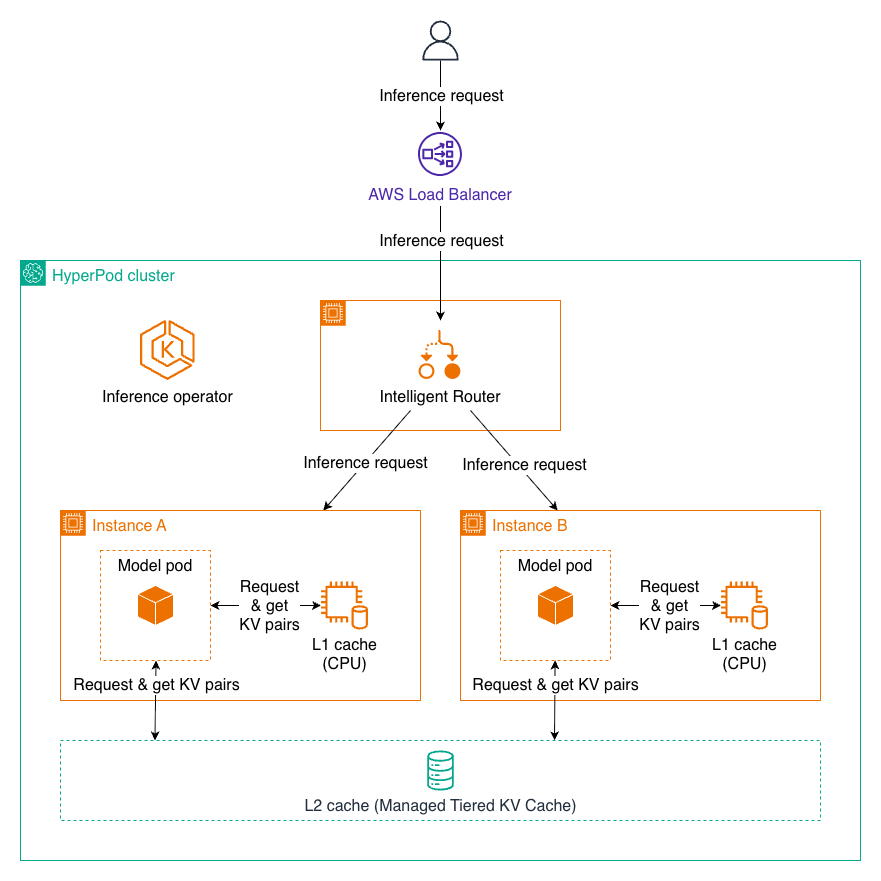
使用 L1 和 L2 KV 缓存的推理请求示意图
托管分层 KV 缓存
托管分层 KV 缓存功能通过实现多层缓存策略来解决推理过程中的内存限制问题。键值(KV)缓存对于 LLM 推理效率至关重要——它存储来自前序 token 的中间注意力计算结果,避免冗余的重新计算,从而显著降低延迟。
通过跨多个存储层管理缓存,HyperPod 实现了以下能力:
- 降低 GPU 资源的内存压力
- 支持更长的 Context Window 而不影响性能
- 自动缓存管理,无需人工干预
智能路由
智能路由通过将具有共享提示前缀的请求定向到同一推理实例来优化推理效率,最大化 KV 缓存的复用。这种方式能够:
- 策略性地路由请求到已处理过相似前缀的实例
- 通过复用缓存的 KV 数据加速处理
- 降低延迟,适用于多轮对话和具有公共上下文的批量请求
性能收益
这些能力综合起来可带来显著的性能改善:
- 推理请求延迟最高降低 40%
- 请求处理吞吐量提升 25%
- 与未启用上述优化的基准配置相比,节省 25% 的成本
这些功能通过 HyperPod 推理算子提供,为生产 LLM 部署提供开箱即用的托管能力。有关此功能的更多详情,请参阅为 Amazon SageMaker HyperPod 配置托管分层 KV 缓存和智能路由。
多实例 GPU 支持(MIG)配置
SageMaker HyperPod 推理现在支持在已使用 NVIDIA MIG(多实例 GPU)技术进行分区的加速器上部署模型。在大型 GPU 上部署小型模型会造成 GPU 资源浪费。为了解决这一问题,SageMaker HyperPod 允许您使用相互隔离的 GPU 分片。如果 GPU 已经完成分区,您可以直接使用 SageMaker HyperPod 推理解决方案部署 JumpStart 模型或 InferenceEndpointConfig。
对于 JumpStartModel,您可以使用 spec.server.acceleratorPartitionType 字段来设置您选择的 MIG 配置文件。以下示例展示了对应的配置:
apiVersion: inference.sagemaker.aws.amazon.com/v1
kind: JumpStartModel
metadata:
name: deepseek
spec:
sageMakerEndpoint:
name: deepseek
model:
modelHubName: SageMakerPublicHub
modelId: deepseek-llm-r1-distill-qwen-1-5b
server:
acceleratorPartitionType: mig-7g.40gb
instanceType: ml.p4d.24xlargeJumpStartModel 还会在模型部署前进行内部验证。您可以通过将 YAML 中的 spec.server.validations.acceleratorPartitionValidation 字段设置为 false 来关闭该验证。对于 InferenceEndpointConfig,您可以使用 spec.worker.resources.requests 和 spec.worker.resources.limits 字段来指定所选的 MIG 配置文件,从而将模型部署到对应的 MIG 配置上。以下示例展示了对应的配置:
apiVersion: inference.sagemaker.aws.amazon.com/v1
kind: InferenceEndpointConfig
….
spec:
worker:
resources:
requests:
cpu: 5600m
memory: 10Gi
nvidia.com/mig-4g.71gb: 1
limits:
nvidia.com/mig-4g.71gb: 1通过这些配置,您可以将 SageMaker HyperPod 推理所支持的其他技术与模型的 MIG 部署结合使用。如需了解更多信息,请参阅 HyperPod 现已支持多实例 GPU 以最大化生成式 AI 任务的 GPU 利用率。
可观测性
您可以通过 SageMaker HyperPod 可观测性功能监控 HyperPod 推理指标。
要启用 SageMaker HyperPod 可观测性功能,请按照通过 Amazon SageMaker HyperPod 中的一键式可观测性加速基础模型开发中的说明操作。
HyperPod 可观测性在 Grafana 中提供内置仪表板。例如,推理仪表板提供了对推理相关指标的可见性,包括传入请求数、延迟和首字节时间(TTFB)。
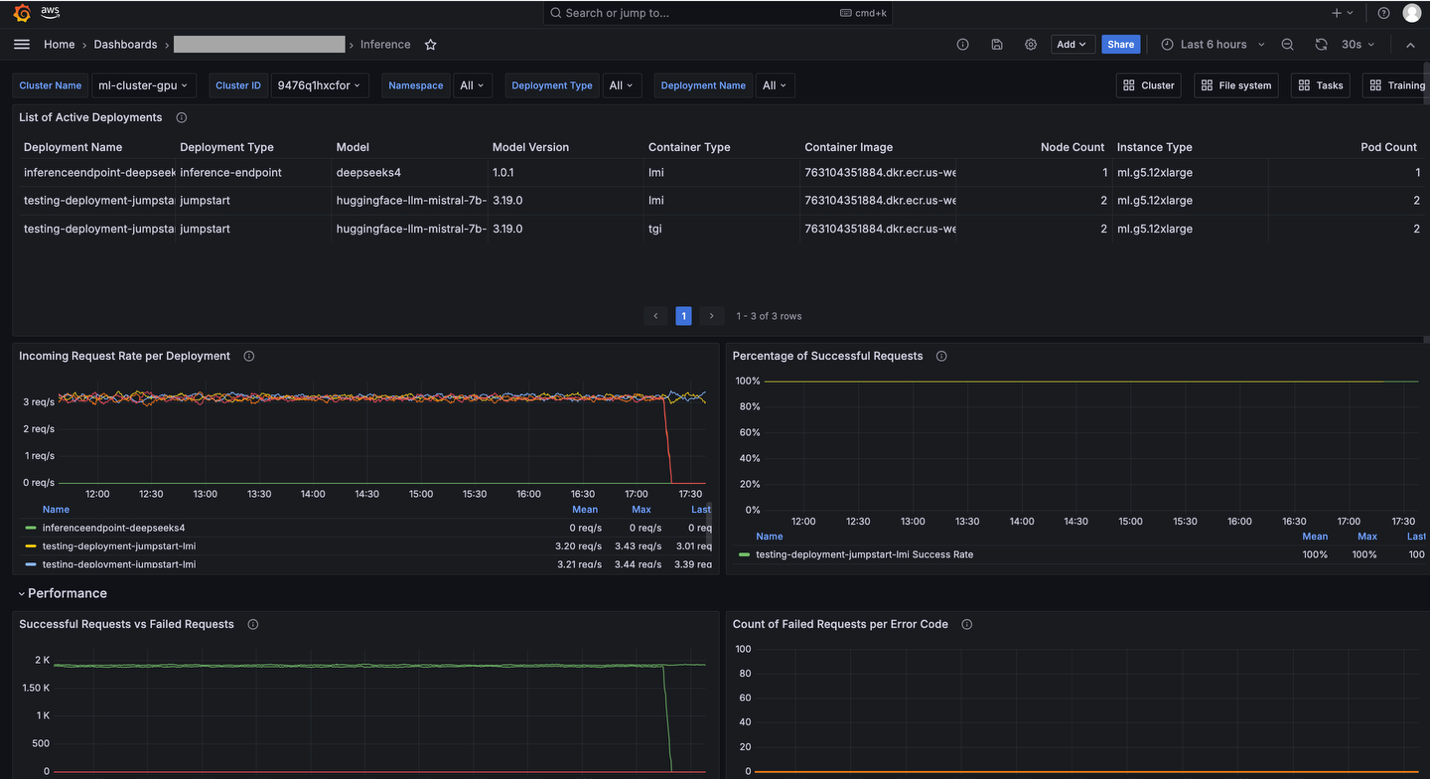
Grafana 仪表板示意图
运行 Notebook
使用 Amazon EKS 编排的 HyperPod 集群现已支持创建和管理 JupyterLab 及开源 Visual Studio Code 等交互式开发环境,通过为数据科学家提供熟悉工具的托管环境,从而简化机器学习开发生命周期。该功能引入了一个名为 Amazon SageMaker Spaces 的新附加组件,供 AI 开发者创建和管理用于运行 Notebook 的独立环境。现在,您可以在同一基础设施上同时运行交互式工作负载和训练作业,最大化 GPU 投入的价值,并通过支持 GPU 分片分配来提升成本效率。
在 HyperPod 控制台中部署 IDE 和 Notebook 附加组件:

Amazon SageMaker AI 正在为 SageMaker HyperPod EKS 集群引入一项新能力,允许 AI 开发者直接在 HyperPod EKS 集群上运行交互式机器学习工作负载。该功能引入了一个名为 Amazon SageMaker Spaces 的新附加组件,使 AI 开发者能够创建和管理用于运行 Notebook 的独立环境。
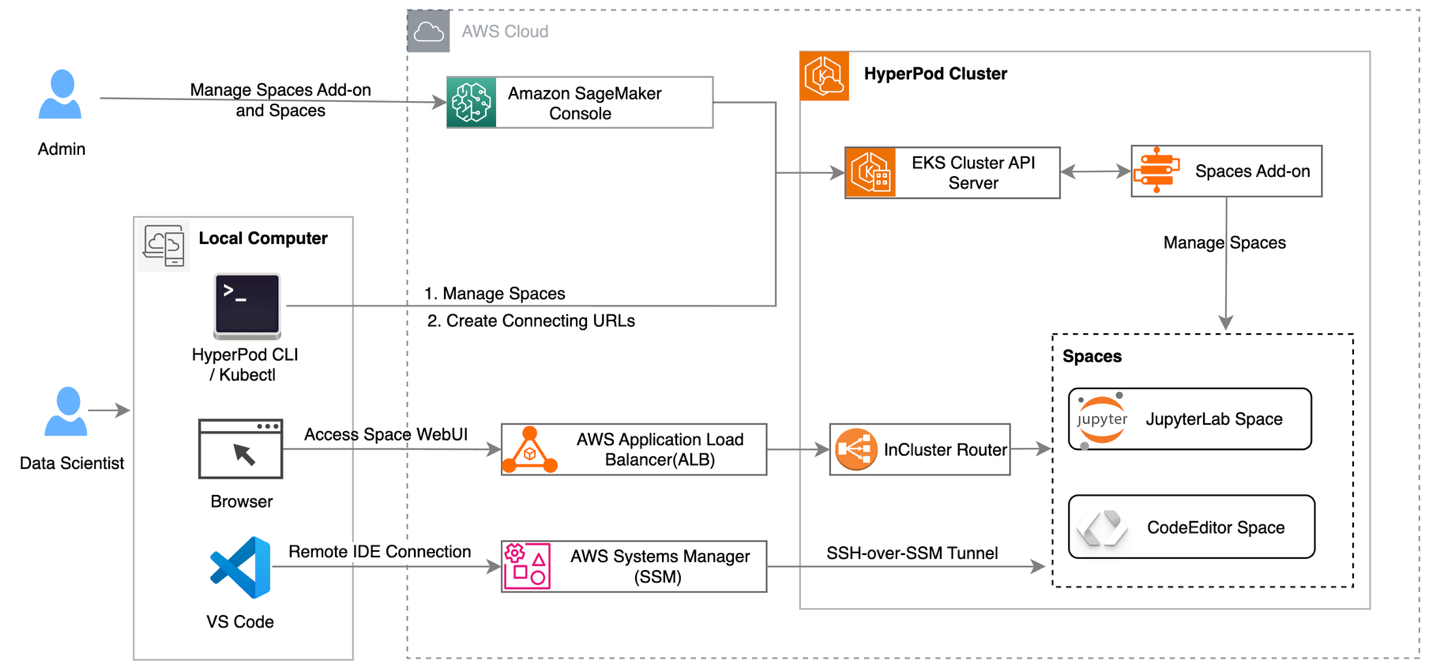
在 HyperPod 集群上运行 Jupyter Notebook 的高层架构图
总结
在本文中,我们探讨了 Amazon SageMaker HyperPod 如何为运行推理工作负载提供可扩展、高性价比的基础设施。通过遵循本文概述的最佳实践,您可以利用 HyperPod 的能力来部署基础模型——借助一键式 JumpStart、S3 和 FSx for Lustre 集成、托管 Karpenter 自动扩缩容,以及能够从零动态扩展至生产规模的统一基础设施。借助 KV 缓存、智能路由以及多实例 GPU 支持等功能,您可以优化推理工作负载,通过使用 Spot 实例降低延迟、提升吞吐量并降低成本。通过采纳这些最佳实践,您可以加速机器学习工作流程、提升模型性能,并实现显著的总体拥有成本降低,从而在生产环境中负责任、高效地扩展生成式 AI。