原文标题:How to build effective reward functions with AWS Lambda for Amazon Nova model customization
原文链接:https://aws.amazon.com/blogs/machine-learning/how-to-build-effective-reward-functions-with-aws-lambda-for-amazon-nova-model-customization/
作者:Manoj Gupta、Bharathan Balaji、Brian Hu、Sarthak Khanna 发表于:2026 年 4 月 13 日

构建有效的奖励函数可以帮助你根据特定需求定制 Amazon Nova 模型,而 AWS Lambda 则提供了可扩展、高性价比的基础。Lambda 的无服务器架构让你专注于定义质量标准,同时由它来处理计算基础设施。
Amazon Nova 提供了多种定制方法,其中强化微调(RFT)因其通过迭代反馈来教导模型期望行为的能力而脱颖而出。与需要数千个带有标注推理路径的标记示例的监督微调(SFT)不同,RFT 从最终输出的评估信号中学习。RFT 的核心是奖励函数——一种引导模型走向更好响应的评分机制。
本文演示了 Lambda 如何为 Amazon Nova 定制实现可扩展、高性价比的奖励函数。你将学会在 RLVR(通过可验证奖励的强化学习)(适用于客观可验证任务)和 RLAIF(通过 AI 反馈的强化学习)(适用于主观评估)之间进行选择,设计多维奖励系统以防止奖励黑客行为,针对训练规模优化 Lambda 函数,并使用 Amazon CloudWatch 监控奖励分布。文中包含可运行的代码示例和部署指南,帮助你开始实验。
使用 AWS Lambda 构建基于代码的奖励
你有多种途径来定制基础模型,每种途径适合不同的场景。当你有明确的输入-输出示例并想要教导特定的响应模式时,SFT 表现出色——它对于分类、命名实体识别或使模型适应特定领域的术语和格式规范等任务特别有效。当期望的行为可以通过示例来展示时,SFT 效果很好,非常适合教导一致的风格、结构或事实知识迁移。然而,一些定制挑战需要不同的方法。当应用程序需要模型同时平衡多个质量维度——例如必须同时准确、有同理心、简洁且符合品牌形象的客户服务响应——或者当创建数千个带标注推理路径的示例变得不切实际时,基于强化的方法提供了更好的替代方案。RFT 通过从评估信号中学习来解决这些场景,而不需要正确推理过程的详尽标记示范。
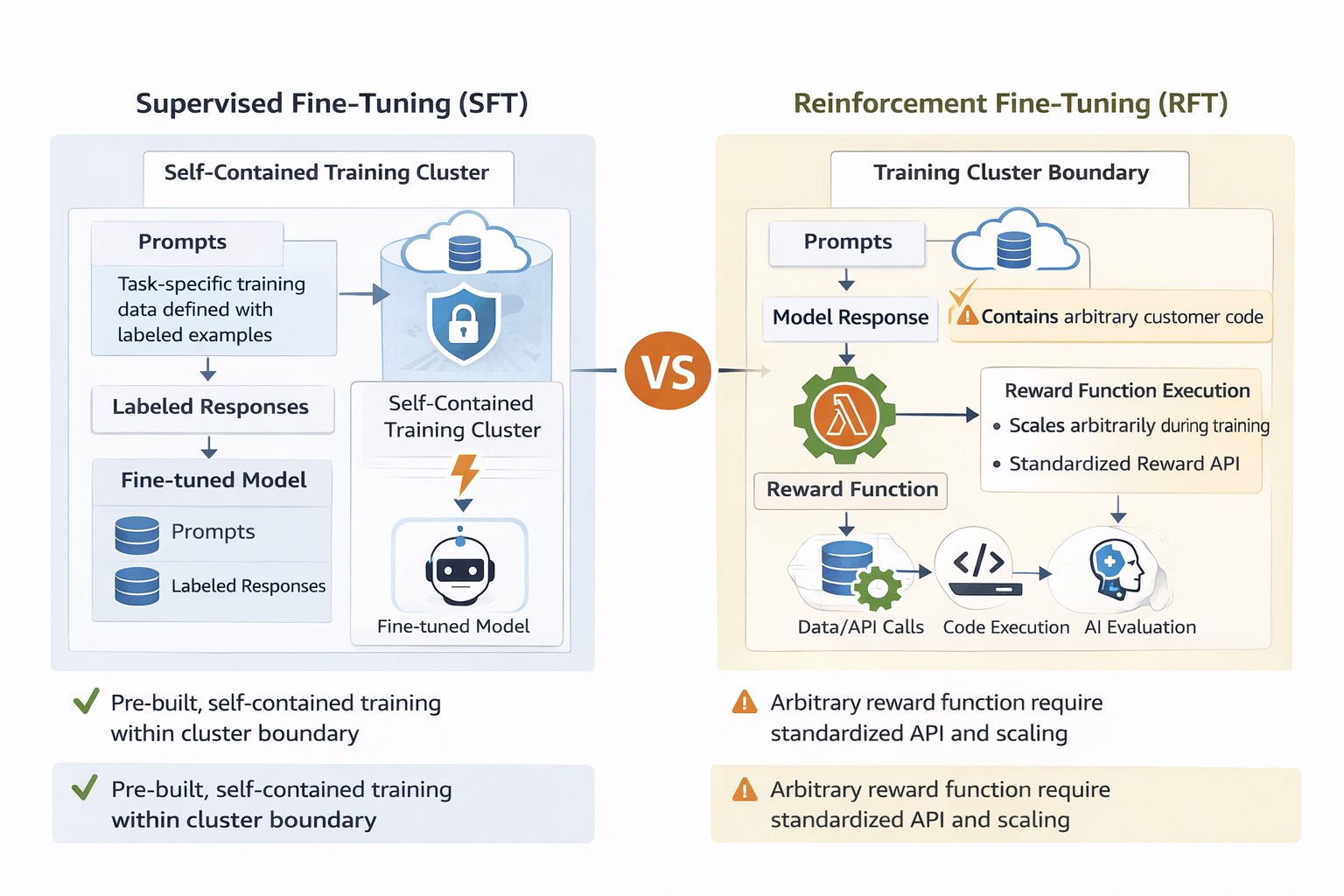
基于 AWS Lambda 的奖励函数通过基于反馈的学习简化了这一过程。你无需向模型展示数千个有效示例,而是提供提示并定义评估逻辑来对响应评分——然后模型通过迭代反馈学习改进。这种方法需要更少的标记示例,同时让你对期望行为有精确的控制。多维评分捕捉细微的质量标准,防止模型利用捷径,而 Lambda 的无服务器架构在无需基础设施管理的情况下处理可变的训练工作负载。其结果是 Nova 定制对没有深厚机器学习专业知识的开发者来说也可以访问,同时对复杂的生产用例来说也足够灵活。
AWS Lambda 奖励如何工作
RFT 架构使用 AWS Lambda 作为无服务器奖励评估器,与 Amazon Nova 训练流程集成,创建一个引导模型学习的反馈循环。该过程从你的训练作业为每个训练提示从 Nova 模型生成候选响应开始。这些响应流向你的 Lambda 函数,该函数从正确性、安全性、格式和简洁性等维度评估其质量。然后该函数返回标量数值分数——作为最佳实践,通常在 -1 到 1 的范围内。更高的分数引导模型强化产生这些分数的行为,而更低的分数则引导它远离导致不良响应的模式。这个循环在整个训练过程中重复数千次,逐步塑造模型走向持续获得更高奖励的响应。
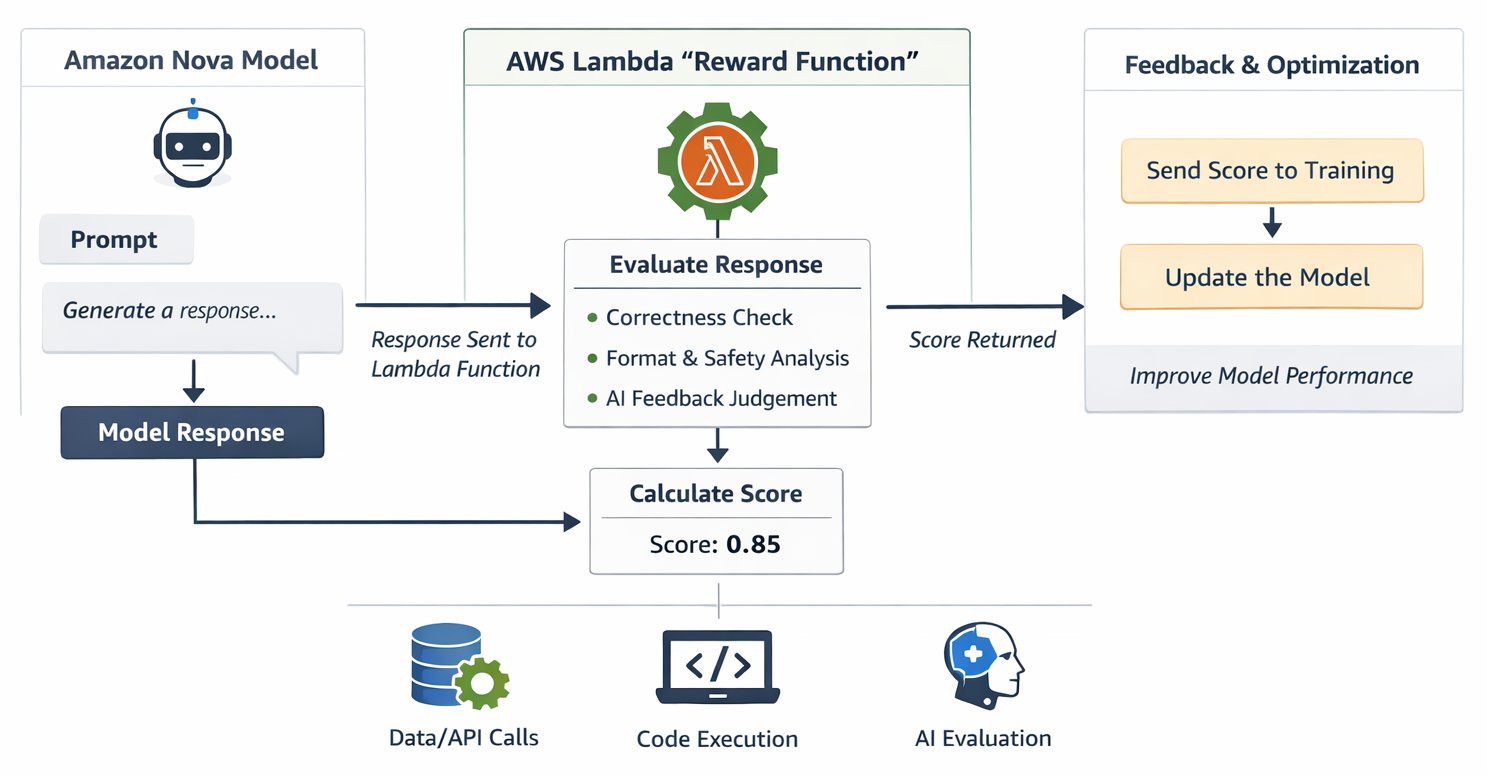
该架构将多个 AWS 服务整合到一个有机的定制解决方案中。Lambda 以自动扩展执行你的奖励评估逻辑,无需你配置或管理基础设施即可处理可变的训练需求。Amazon Bedrock 通过集成 Lambda 支持提供完全托管的 RFT 体验,通过简单的应用程序接口(API)为 RLAIF 实现提供 AI 评判模型。对于需要高级训练控制的团队,Amazon SageMaker AI 通过 Amazon SageMaker AI 训练作业和 Amazon SageMaker AI HyperPod 提供选项,两者都支持相同的基于 Lambda 的奖励函数。Amazon CloudWatch 实时监控 Lambda 性能,记录有关奖励分布和训练进度的详细调试信息,并在出现问题时触发警报。在基础层面,Amazon Nova 本身——具有针对各种用例优化定制配方的模型,有效地响应你的奖励函数提供的反馈信号。
这种无服务器方式使 Nova 定制具有成本效益。Lambda 自动从初始实验阶段每秒处理 10 个并发评估扩展到生产训练期间的 400+ 个评估,无需基础设施调整或容量规划。你的单个 Lambda 函数可以同时评估多个质量标准,提供防止模型利用简单化评分捷径的细致多维反馈。该架构通过 RLVR 支持客观验证——对代码运行测试用例或验证结构化输出——以及通过 RLAIF 支持主观判断,其中 AI 模型评估语气和帮助性等质量。你只需为评估期间的实际计算时间付费,按毫秒计费,使实验成本低廉,同时保持生产成本与训练强度成正比。对于迭代开发来说最有价值的是,Lambda 函数作为可重用的”评估器”资产保存在 Amazon SageMaker AI Studio 中,使你能够在多次训练运行中优化定制策略时保持一致的质量测量。
选择正确的奖励机制
成功 RFT 的基础是选择正确的反馈机制。两种互补的方法服务于不同的用例:RLVR 和 RLAIF 是用于在初始训练后对大型语言模型(LLM)进行微调的两种技术。它们的主要区别在于如何向模型提供反馈。
RLVR(通过可验证奖励的强化学习)
RLVR 使用确定性代码来验证客观正确性。RLVR 专为可以数学或逻辑上验证”正确”答案的领域设计,例如解决数学问题。RLVR 使用确定性函数对输出进行评分,而不是使用已学习的奖励模型。RLVR 对于没有绝对标准答案的任务(如创意写作或品牌声音)是不适用的。
- 最适合: 代码生成、数学推理、结构化输出任务
- 示例: 对测试用例运行生成的代码、验证 API 响应、检查计算准确性
- 优势: 可靠、可审计、确定性评分
RLVR 函数以编程方式针对标准答案验证正确性。以下是一个做情感分析的示例:
from typing import List
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Optional
def extract_answer_nova(solution_str: str) -> Optional[str]:
"""Extract sentiment polarity from Nova-formatted response for chABSA."""
# First try to extract from solution block
solution_match = re.search(r'<\|begin_of_solution\|>(.*?)<\|end_of_solution\|>', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# Look for boxed format in solution block
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# Fallback: look for boxed format anywhere
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# Last resort: look for sentiment keywords
solution_lower = solution_str.lower()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(answer: str) -> str:
"""Normalize answer for comparison."""
return answer.strip().lower()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
score: float = 1.0,
data_source: str = 'chabsa',
extra_info: Optional[dict] = None
) -> float:
"""chABSA scoring function with VeRL-compatible signature."""
answer = extract_answer_nova(solution_str)
if answer is None:
return 0.0
# Parse ground_truth JSON to get the answer
gt_answer = ground_truth.get("answer", ground_truth)
clean_answer = normalize_answer(answer)
clean_ground_truth = normalize_answer(gt_answer)
return score if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""Reward service."""
id: str
aggregate_reward_score: float
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
for sample in samples:
# Extract the ground truth key. In the current dataset it's answer
print("Sample: ", json.dumps(sample, indent=2))
ground_truth = sample["reference_answer"]
idx = "no id"
# print(sample)
if not "id" in sample:
print(f"ID is None/empty for sample: {sample}")
else:
idx = sample["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
if not "messages" in sample:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Extract answer from ground truth dict
if ground_truth is None:
print(f"No answer found in ground truth for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Get completion from last message (assistant message)
last_message = sample["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Last message is not from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
if not "content" in last_message:
print(f"Completion text is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]你的 RLVR 函数应该包含三个关键设计元素以实现有效训练。首先,通过奖励部分积分来创建平滑的奖励景观——例如,即使最终答案不正确,也为正确的响应结构提供 format_score 积分。这防止了使学习变得困难的二元评分断崖。其次,实现具有多种解析策略的良好提取逻辑,优雅地处理各种响应格式。第三,在每个步骤使用防御性编码实践来验证输入,防止因格式错误的输入而崩溃。
RLAIF(通过 AI 反馈的强化学习)
RLAIF 使用 AI 模型作为评判者进行主观评估。RLAIF 达到与 RLHF(通过人类反馈的强化学习)相当的性能,同时速度明显更快、成本更低。以下是一个用于情感分类的 RLAIF Lambda 函数示例代码。
- 最适合: 创意写作、摘要、品牌声音一致性、帮助性
- 示例: 评估响应语气、评估内容质量、判断用户意图对齐
- 优势: 可扩展的类人判断,无需手动标注成本
RLAIF 函数将判断委托给有能力的 AI 模型,如以下示例代码所示:
import json
import re
import time
import boto3
from typing import List, Dict, Any, Optional
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
JUDGE_MODEL_ID = "<jude_model_id>" #Replace with judge model id of your interest
SYSTEM_PROMPT = "You must output ONLY a number between 0.0 and 1.0. No explanations, no text, just the number."
JUDGE_PROMPT_TEMPLATE = """Compare the following two responses and rate how similar they are on a scale of 0.0 to 1.0, where:
- 1.0 means the responses are semantically equivalent (same meaning, even if worded differently)
- 0.5 means the responses are partially similar
- 0.0 means the responses are completely different or contradictory
Response A: {response_a}
Response B: {response_b}
Output ONLY a number between 0.0 and 1.0. No explanations."""
def extract_solution_nova(solution_str: str, method: str = "strict") -> Optional[str]:
"""Extract solution from Nova-formatted response."""
assert method in ["strict", "flexible"]
if method == "strict":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].replace(",", "").replace("$", "")
return final_answer
return None
elif method == "flexible":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
numbers = re.findall(r"(\\-?[0-9\\.\\,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].replace(",", "").replace("$", "")
answer = re.findall(r"(\\-?[0-9\\.\\,]+)", solution_str)
if len(answer) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(answer):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Call Bedrock to compare responses and return similarity score."""
prompt = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for attempt in range(max_retries):
try:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
score = float(output)
return max(0.0, min(1.0, score))
except Exception as e:
if "ThrottlingException" in str(e) and attempt < max_retries - 1:
time.sleep(2 ** attempt)
else:
return 0.0
return 0.0
def compute_score(id: str, solution_str: str, ground_truth: str) -> float:
"""Compute score for train.jsonl format."""
answer = extract_solution_nova(solution_str=solution_str, method="flexible")
if answer is None:
return 0.0
clean_answer = str(answer)
clean_ground_truth = str(ground_truth)
score = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return score
def lambda_grader(samples: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
Process samples from train.jsonl format and return scores.
Args:
samples: List of dictionaries with messages and metadata
Returns:
List of dictionaries with reward scores
"""
results = []
for sample in samples:
sample_id = sample.get("id", "unknown")
# Extract reference answer from metadata or top level
metadata = sample.get("metadata", {})
reference_answer = metadata.get("reference_answer", sample.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("answer", "")
else:
ground_truth = str(reference_answer)
# Get assistant response from messages
messages = sample.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("role") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content", "")
break
if not assistant_response or not ground_truth:
results.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
continue
# Compute score
score = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
results.append({
"id": sample_id,
"aggregate_reward_score": score,
"metrics_list": [
{
"name": "semantic_similarity",
"value": score,
"type": "Reward"
}
]
})
return results
def lambda_handler(event, context):
return lambda_grader(event)在实现 RLAIF 函数时,考虑使用全局变量进行客户端初始化以减少整体调用延迟。优雅地处理限流异常以避免训练中断。使用温度 0.0 来获得确定性的评判分数,这有助于模型一致性。提供清晰的评分标准,有助于评判者提供经过校准的分数。
编写好的奖励函数的注意事项
要为 RFT 编写好的奖励函数,从简单开始,创建平滑的奖励景观(而非二元断崖),确保奖励与真实目标对齐(避免黑客行为),对复杂任务使用密集/塑形奖励,提供清晰的信号,并使其可验证且一致。
- 明确定义目标: 清楚了解你的模型成功意味着什么。
- 平滑的奖励景观: 不要使用简单的通过/失败(0 或 1),而要使用平滑、密集的奖励信号,为”走在正确轨道上”提供部分积分。这种细粒度的反馈有助于模型从渐进改进中学习,而不是等待完美的响应。对于复杂的多步骤任务,为中间进度提供奖励(塑形),而不仅仅是最终结果(稀疏)。
- 使奖励多维化: 单一的标量奖励太容易被黑客攻击。奖励应该从多个维度评估模型性能:例如正确性、对输入的忠实度、安全性/策略对齐、格式和简洁性等。
- 防止奖励黑客行为: 确保模型无法通过捷径获得高奖励(例如,幸运猜测、重复操作);使任务难以猜测。
- 使用可验证的评分标准: 对于代码生成或数学等客观任务,使用自动评分器执行代码或解析特定答案标记(例如
<answer>)来验证正确性,无需人工参与。 - 为主观任务实现 LLM 评判者: 当程序代码无法判断答案时(例如摘要),使用单独的、有能力的模型作为”LLM 评判者”。你必须首先评估这个评判者,以确保其评分稳定且与人类偏好一致。
在训练循环中优化你的奖励函数执行
一旦你的奖励函数正确工作,优化可以帮助你更快地训练同时控制成本。本节涵盖你的工作负载需要考虑的技术。优化技术在影响上是复合的——一个配置良好的 Lambda 函数,具有适当的批次大小、并发设置、冷启动缓解和错误处理,可以比简单实现快十倍地评估响应,成本显著降低,并提供更好的训练可靠性。在定制过程早期进行优化投入,通过减少迭代时间、降低计算成本和在需要昂贵重新训练之前捕获问题,在整个训练过程中获得回报。
-
在开始训练之前确保 IAM 权限配置正确
依赖管理和权限:
- 如何添加依赖:你可以直接将它们与你的代码打包在部署包(.zip 文件)中,或者使用 Lambda 层单独管理依赖,与你的核心逻辑分离。
- 用于 RLAIF 的 Amazon Bedrock 访问:Lambda 函数的执行角色应该有权访问 Amazon Bedrock 进行 LLM API 调用。
对跨多个函数共享的依赖使用层。对特定于函数的逻辑使用部署包。将 AWS 身份和访问管理(IAM)权限附加到 Lambda 执行角色以用于 RLAIF 实现。遵循最小权限原则,将资源 ARN 的范围限定为你用作评判者的特定基础模型,而不是使用通配符:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream" ], "Resource": "arn:aws:bedrock:<region>:<account-id>:foundation-model/<model-id>" } ] } -
了解平台差异以及哪个平台可能更适合你的需求
优化基于 Lambda 的奖励函数需要了解不同的训练环境如何与无服务器评估交互,以及架构选择如何影响吞吐量、延迟和成本。同步和异步处理模型之间的优化格局存在实质性差异,使得特定于环境的调整对于生产规模的定制至关重要。
Amazon SageMaker AI 训练作业采用同步处理,先生成 rollout,然后在并行批次中评估它们。这种架构围绕批次大小和并发管理创造了独特的优化机会。
lambda_batch_size参数(默认为 64)决定 Lambda 在单次调用中评估多少个样本——对于在毫秒内完成的快速奖励函数调高此值,但对于接近超时阈值的复杂评估则降低它。lambda_concurrency参数控制并行执行,默认的 12 个并发调用对于生产工作负载来说通常过于保守。快速奖励函数受益于显著更高的并发,有时达到 50 个或更多同时执行,但你必须监控限制你区域内函数总并发执行数的账户级 Lambda 并发限制。Amazon SageMaker AI HyperPod 通过异步处理采取根本不同的方法,逐个样本而不是大批次地生成和评估样本。这种逐样本架构自然支持更高的吞吐量,默认配置无需特殊调整即可通过 Lambda 处理每秒 400 个事务。超过此基线进行扩展需要协调调整 HyperPod 配方参数——特别是控制工作节点并行性的
proc_num和rollout_worker_replicas。在积极扩展工作节点时,考虑按比例增加generation_replicas以防止生成成为瓶颈,而评估容量闲置。 -
使用 Lambda 并发优化奖励函数
Lambda 配置直接影响训练速度和可靠性:
- 超时配置:将超时设置为 60 秒(默认只有 3 秒),这为 RLAIF 评判调用或复杂的 RLVR 逻辑提供了余量。
- 内存分配:将内存设置为 512 MB(默认是 128 MB),加速的 CPU 改善响应时间性能。
-
冷启动缓解
冷启动缓解防止可能减慢训练速度并增加成本的延迟峰值。将部署包保持在 50MB 以下以最小化初始化时间——这通常意味着排除不必要的依赖并为大型共享库使用 Lambda 层。通过在全局范围内初始化客户端(如 Amazon Bedrock 运行时客户端)而不是在处理函数内部初始化,跨调用重用连接,允许 Lambda 执行环境在调用之间维护这些连接。使用 Lambda Insights 对你的函数进行性能分析以识别性能瓶颈。在全局范围内缓存频繁访问的数据,如评估标准、验证规则或配置参数,这样 Lambda 每个容器只加载一次而不是每次调用都加载。这种全局初始化与处理器级执行的模式对于处理训练期间数千次评估的 Lambda 函数特别有效。
# Keep deployment package under 50MB # Reuse connections across invocations bedrock_client = boto3.client('bedrock-runtime') # Global scope # Cache frequently accessed data EVALUATION_RUBRICS = {...} # Load once def lambda_handler(event, context): # Clients and cached data persist across invocations return evaluate_responses(event, bedrock_client, EVALUATION_RUBRICS) -
优化 RLAIF 评判模型
对于使用 Amazon Bedrock 模型作为评判者的 RLAIF 实现,需要考虑一个重要的权衡。更大的模型提供更可靠的判断但吞吐量较低,而较小的模型提供更好的吞吐量但能力可能较弱——选择对你的任务来说足够小的评判模型以最大化吞吐量。在扩展到完整训练之前,对评判者一致性进行性能分析。
吞吐量管理:
- 在区域级别监控 Amazon Bedrock 限流限制
- 考虑使用 Amazon SageMaker AI 端点作为评判模型。它提供更高的吞吐量,但目前仅限于开放权重和 Nova 模型
- 尽可能在每个 API 调用中批量多个评估
- 考虑共享 Amazon Bedrock 配额的并发训练作业
-
确保你的 Lambda 奖励函数具有容错性和纠错性
现实世界的系统会遭遇故障——网络故障、临时服务不可用或偶尔的 Lambda 超时。我们构建了健壮的重试机制,自动处理超时、Lambda 故障和瞬态错误,而不是让单个故障破坏整个训练作业。该系统以指数退避智能地重试失败的奖励计算,给临时问题时间解决。如果调用在三次重试后仍然失败,你将收到一条清晰的、可操作的错误消息,指出具体问题——无论是超时、权限问题还是你的奖励逻辑中的 bug。这种透明度让你能够快速识别和修复问题,而无需筛查神秘的日志。
def robust_evaluation(sample, max_retries=3): """Evaluation with comprehensive error handling.""" for attempt in range(max_retries): try: score = compute_score(sample) return score except ValueError as e: # Parsing errors - return 0 and log print(f"Parse error for {sample['id']}: {str(e)}") return 0.0 except Exception as e: # Transient errors - retry with backoff if attempt < max_retries - 1: time.sleep(2 ** attempt) else: print(f"Failed after {max_retries} attempts: {str(e)}") return 0.0 return 0.0 -
迭代 CloudWatch 调试并尽早捕获任何错误迹象
对训练过程的可见性对于监控进度和排查问题都至关重要。我们自动记录训练流程每个阶段的全面信息到 CloudWatch:每个训练步骤的指标——包括逐步的训练奖励分数和每个流程组件的详细执行轨迹。这种细粒度的日志记录使得实时跟踪训练进度、验证你的奖励函数是否按预期对响应评分,以及在问题出现时快速诊断变得简单。例如,如果你注意到训练没有改善,你可以检查 CloudWatch 中的奖励分布,看看你的函数是否大多返回零值或信号不足。
CloudWatch 提供对奖励函数性能的全面可见性。以下是一些有用的 Amazon CloudWatch Insights 查询:
-- Find samples with zero rewards SOURCE '/aws/lambda/my-reward-function' | fields @timestamp, id, aggregate_reward_score | filter aggregate_reward_score = 0.0 | sort @timestamp desc -- Calculate reward distribution SOURCE '/aws/lambda/my-reward-function' | fields aggregate_reward_score | stats count() by bin(aggregate_reward_score, 0.1) -- Identify slow evaluations SOURCE '/aws/lambda/my-reward-function' | fields @duration, id | filter @duration > 5000 | sort @duration desc -- Track multi-dimensional metrics SOURCE '/aws/lambda/my-reward-function' | fields @timestamp, correctness, format, safety, conciseness | stats avg(correctness) as avg_correctness, avg(format) as avg_format, avg(safety) as avg_safety, avg(conciseness) as avg_conciseness by bin(5m)
结论
基于 Lambda 的奖励函数为需要精确行为控制而无需大量标记数据集和改进推理的组织解锁了 Amazon Nova 定制。这种方法通过灵活性、可扩展性和成本效益提供了显著优势,从而简化你的模型定制过程。该架构允许 RLVR 处理客观验证任务,而 RLAIF 则帮助进行主观判断以实现细致的质量评估。组织可以单独使用它们,也可以将它们结合起来进行综合评估,捕捉事实准确性和风格偏好。可扩展性自然从无服务器基础中涌现,自动处理从早期实验到生产规模定制的可变训练工作负载。成本效益直接来自这种设计——组织只为实际评估计算付费,由于优化的 Lambda 并发和高效的奖励计算,训练作业完成得更快。Amazon Nova 基础模型、Lambda 无服务器可扩展性和 Amazon Bedrock 托管定制基础设施的组合使强化微调对各种规模的组织都更加可访问。从本文中的示例代码开始实验,并开始定制能够精确提供你的应用程序所需行为的 Amazon Nova 模型。
致谢
特别感谢 Eric Grudzien 和 Anupam Dewan 对本文的审阅和贡献。
关于作者
Bharathan Balaji 是 Amazon Web Services 的高级应用科学家,从事强化学习和基础模型服务工作。他的工作专注于构建帮助客户转型业务的 AI 能力。
Manoj Gupta 是 AWS 驻旧金山的高级解决方案架构师。在 AWS 拥有超过 4 年的工作经验,他与客户密切合作,构建优化的 AI/ML 驱动解决方案和云基础设施。他的主要专注领域是数据、AI/ML 和安全,帮助组织实现技术栈现代化。工作之余,他喜欢与家人一起进行户外活动和旅行。
Brian Hu 是 AWS 的高级应用科学家,专注于监督和强化微调及其在各个领域的应用。他与客户密切合作,为增强性能和特定领域优化定制大型语言模型(LLM)。
Sarthak Khanna 是 Amazon AGI 的软件开发工程师,专注于强化微调和 Agentic AI 系统。他的工作专注于为大型语言模型构建可扩展的训练流程,利用强化学习实现多轮推理、工具使用和自主决策。