原文标题:Vector Drift in Azure AI Search: Three Hidden Reasons Your RAG Accuracy Degrades After Deployment
原文链接:https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/vector-drift-in-azure-ai-search-three-hidden-reasons-your-rag-accuracy-degrades-/4493031
博客文章

微软基础设施博客 3分钟阅读
Azure AI搜索中的向量漂移:您的RAG准确性在部署后下降的三个隐藏原因

微软 2026年4月4日
使用Azure AI搜索和Azure OpenAI构建的检索增强生成(RAG)解决方案通常在初始测试和早期生产推出期间表现良好。
然而,许多团队注意到检索质量会随着时间逐渐下降——即使没有代码更改、没有基础设施问题,也没有服务中断。 一个常见的根本原因是向量漂移。
本文解释了什么是向量漂移、为什么它会出现在生产RAG系统中,以及如何使用Azure原生模式设计抗漂移架构。
什么是向量漂移?
向量漂移发生在向量索引中存储的嵌入不再准确代表传入查询的语义意图时。
由于向量相似性搜索依赖于相对的语义位置,模型、数据分布或预处理逻辑中的即使很小的变化也会随着时间显著影响检索质量。
与模式漂移或数据损坏不同,向量漂移是微妙的:
- 系统继续运行
- 查询返回结果
- 但相关性逐渐下降
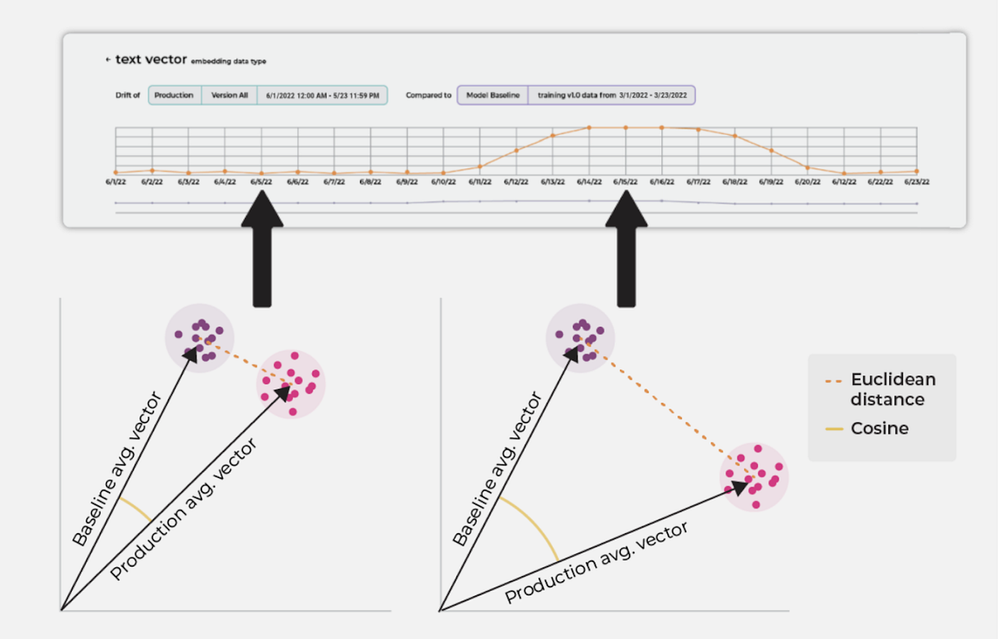
原因1:嵌入模型版本不匹配
发生了什么
文档使用一个嵌入模型进行索引,而查询嵌入使用另一个模型生成。这通常由以下原因导致:
- 模型升级
- 多个团队共享Azure OpenAI资源
- 环境之间的配置不一致
为什么这很重要
由不同模型生成的嵌入:
- 存在于不同的向量空间中
- 在数学上不可比较
- 产生误导性的相似性评分
因此,以前相关的文档可能不再正确排名。
建议实践
单个向量索引应该在其整个生命周期内绑定到一个嵌入模型和一个维度大小。
如果嵌入模型更改,索引必须完全重新嵌入并重建。
原因2:增量内容更新但未重新嵌入
发生了什么
新文档不断被添加到索引中,而现有嵌入保持不变。随着时间推移,新内容引入:
- 更新的术语
- 政策更改
- 新的产品或领域概念
由于语义含义是相对的,向量空间会发生移动——但较旧的向量不会。
可观察的影响
- 最近索引的文档占据检索结果的主导地位
- 较旧但仍然有效的内容变得更难检索
- 没有明显的系统错误,召回率下降
实用指导
将嵌入视为活跃资产,而不是静态工件:
- 为稳定的语料库安排定期重新嵌入
- 重新嵌入高影响力或频繁访问的文档
- 当领域词汇发生有意义的变化时触发重新嵌入
相似性评分下降或引用覆盖范围减少通常是漂移的早期信号。
原因3:不一致的分块策略

发生了什么
分块大小、重叠或解析逻辑随着时间调整,但之前索引的内容没有更新。索引最终包含使用不同策略创建的块。
为什么这会导致漂移
不同的分块策略产生:
- 不同的语义密度
- 不同的上下文边界
- 不同的检索行为
这种不一致性降低了排名稳定性,使检索结果不可预测。
治理建议
分块策略应该被视为索引合同的一部分:
- 每个索引使用一个分块策略
- 存储分块元数据(例如,chunk_version)
- 当分块逻辑更改时重建索引
设计原则
- 版本化的嵌入部署
- 计划或事件驱动的重新嵌入管道
- 标准化的分块策略
- 检索质量可观测性
- 提示和响应评估
关键要点
- 向量漂移是架构问题,而不是服务缺陷
- 它从模型更改、数据演变和预处理不一致中出现
- 长期存在的RAG系统需要嵌入生命周期管理
- Azure AI搜索提供了有效缓解漂移所需的控制措施
结论
向量漂移是生产RAG系统的预期特性。主动管理嵌入模型、分块策略和检索可观测性的团队可以在数据和使用方式演变时保持可靠的相关性。识别和解决向量漂移对于在Azure上构建和运营强大的AI解决方案至关重要。
进一步阅读
以下Microsoft资源提供了有关Azure上向量搜索、嵌入和生产级RAG架构的额外指导。
- Azure AI搜索 – 向量搜索概述 - https://learn.microsoft.com/azure/search/vector-search-overview
- Azure OpenAI – 嵌入概念 - https://learn.microsoft.com/en-us/azure/ai-foundry/openai/how-to/embeddings?view=foundry-classic&tabs=csharp
- Azure上的检索增强生成(RAG)模式 - https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview?tabs=videos
- Azure Monitor – 可观测性概述 - https://learn.microsoft.com/azure/azure-monitor/overview