原文标题:Accelerating decode-heavy LLM inference with speculative decoding on AWS Trainium and vLLM
原文链接:https://aws.amazon.com/blogs/machine-learning/accelerating-decode-heavy-llm-inference-with-speculative-decoding-on-aws-trainium-and-vllm/

作者:Yahav Biran 和 Truong Pham
实用基准测试展示了使用 vLLM、Kubernetes 和 AWS AI 芯片部署 Qwen3 模型时更快的 token 间延迟。
在 AWS Trainium 上使用推测解码,可以将解码密集型工作负载的 token 生成加速高达 3 倍,有助于在不牺牲输出质量的情况下降低每个输出 token 的成本并提高吞吐量。如果你构建 AI 写作助手、编码 Agent 或其他生成式 AI 应用,你的工作负载产生的 token 可能远多于消耗的 token,使解码阶段成为推理的主要成本。在自回归解码过程中,token 是顺序生成的,导致硬件加速器受内存带宽限制且利用率不足。这推高了每个生成 token 的成本。推测解码通过让一个小型草稿模型一次提议多个 token,由目标模型在一次前向传递中验证,来解决这个瓶颈。更少的串行解码步骤意味着更低的延迟和更高的硬件利用率,有助于降低推理成本。
在本文中,你将学到:
- 推测解码的工作原理以及为什么它有助于在 AWS Trainium2 上降低每个生成 token 的成本
- 如何在 Trainium 上的 vLLM 中启用推测解码
- 我们用于评估性能的基准测试方法
- 如何针对你的工作负载调整草稿模型选择和推测 token 窗口大小
- 使用 Qwen3 重现结果的分步说明
什么是推测解码?
推测解码通过使用两个模型来加速自回归生成:
- 草稿模型快速提议 n 个候选 token。
- 目标模型在一次前向传递中验证它们。
要深入了解底层机制,包括 token 接受和拒绝、基于 EAGLE 的推测以及一般推测解码概念,请参阅 AWS Inferentia2 博客文章、SageMaker EAGLE 演练以及这篇入门文章。在本文中,我们重点介绍你在实践中控制的两个旋钮:草稿模型和 num_speculative_tokens。
草稿模型和目标模型必须共享相同的分词器和词汇表,因为推测解码对目标模型直接验证的 token ID 进行操作。我们建议从同一架构系列中选择模型,因为它们的下一个 token 预测更频繁地一致。如果草稿模型和目标模型共享分词器,可以配对不同架构的模型,但草稿模型和目标模型之间较低的一致性会降低接受率并消除大部分性能增益。
当目标模型接受草稿 token 时,这些 token 会被提交,而不会产生串行解码步骤的全部成本。你控制的主要参数是 num_speculative_tokens,它设置草稿模型一次提议的 token 数量。增加此值可以让你在每次验证传递中跳过更多串行解码步骤,当接受率高时直接降低 token 间延迟。
性能增益来自两个效果。首先,推测解码减少了目标模型解码步骤的数量,从而降低了 KV 缓存内存往返次数。(KV 缓存存储先前计算的键和值张量,以便模型不需要为过去的 token 重新计算注意力。每个解码步骤都从内存中读取完整缓存,使解码受内存带宽限制。)其次,推测解码改善了解码期间的硬件利用率。在标准自回归解码中,每个解码步骤只产生一个新 token:加速器启动昂贵的矩阵乘法内核来产生仅一个 token 的工作,使处理元素引擎大部分处于未充分利用状态。在验证期间,目标模型一次处理 n 个 token,摊销内存访问并将一系列小型低效的单 token 计算转化为更密集的计算工作负载。将 num_speculative_tokens 设置得太低会限制速度增益。
将其设置得太高会增加早期拒绝的可能性,浪费草稿计算并提高目标模型验证成本。你可以通过根据观察到的接受率平衡草稿计算与验证成本来调整此值。
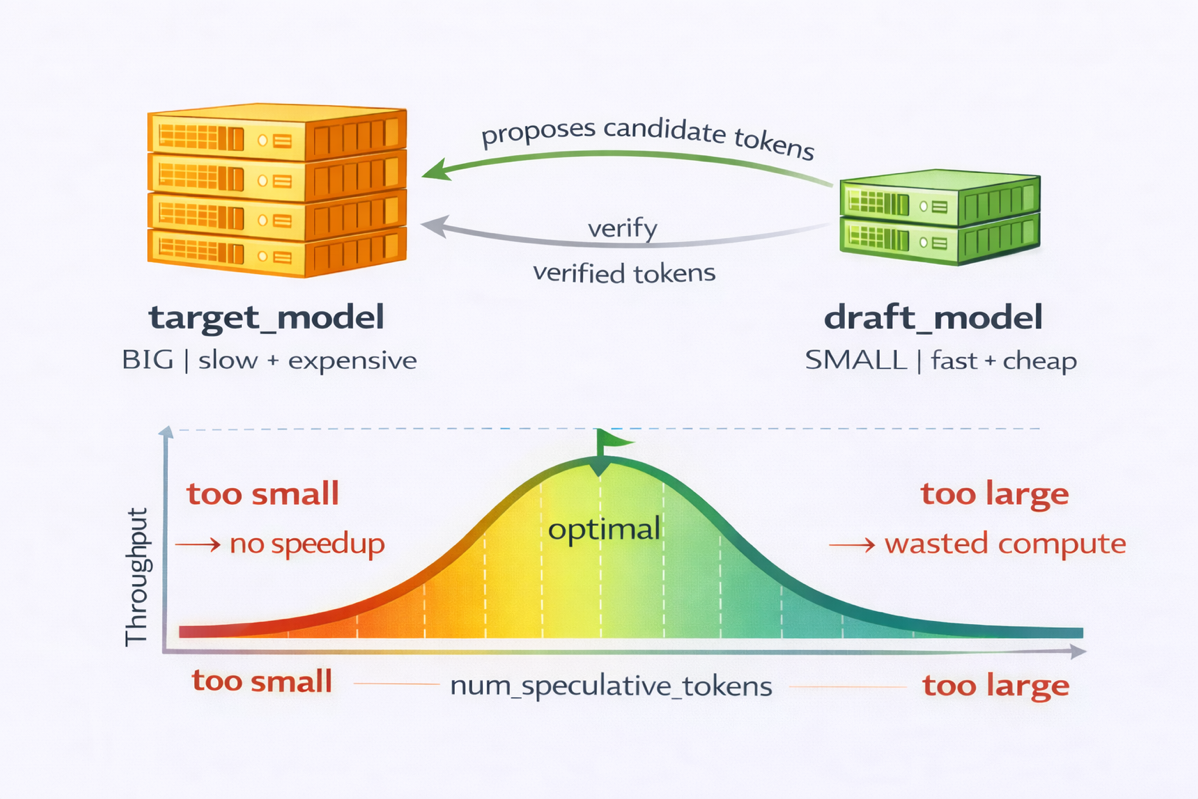
图 1:推测解码配置权衡
为了说明这些权衡,我们比较了 Qwen3-0.6B 和 Qwen3-1.7B 草稿模型。较小的 0.6B 模型运行速度更快,但其接受率低约 60%,足以抵消计算节省。Qwen3-1.7B 在速度和接受率之间取得了更好的平衡。
对于 num_speculative_tokens,我们评估了从 5 到 15 的值。较小的设置(例如 5)提供的加速有限。较大的窗口(例如 15)增加了拒绝次数并降低了性能。最佳配置在很大程度上取决于提示结构。我们测试了结构化提示(例如重复、数字序列和简单代码)和开放式自然语言。最佳平衡来自 Qwen3-1.7B 配合 7 个推测 token。有关完整调整细节,请参阅经验教训部分。
NeuronX 分布式推理(NxD Inference)支持的功能
AWS Neuron 是 AWS AI 芯片的 SDK。NeuronX 分布式推理(NxDI)是其用于 Trainium 和 Inferentia 上可扩展高性能 LLM 推理的库。NxDI 在 Trainium 上跨四种模式提供对推测解码的原生支持:
- 普通推测解码——草稿和目标模型分别独立编译。这是最简单的入门方式。
- 融合推测——草稿和目标模型一起编译以提升性能。这是我们在本文中使用的模式。
- EAGLE 推测——草稿模型利用来自目标模型的隐藏状态上下文来提高接受率。
- Medusa 推测——多个小型预测头并行运行以提议 token,减少草稿模型开销。
有关完整文档,请参阅推测解码指南和 EAGLE 推测解码指南。本文使用融合推测,其中草稿模型(Qwen3-1.7B)和目标模型(Qwen3-32B)使用 enable_fused_speculation=true 一起编译,以在 Neuron 上获得最佳性能。
在 AWS Trainium 上开始使用推测解码
我们在同一 Amazon Elastic Kubernetes Service(Amazon EKS)集群中的 Trainium 实例上部署两个 vLLM 推理服务,除解码方法外保持其他所有配置相同,以隔离性能影响。基线服务(qwen-vllm)使用标准解码为 Qwen3-32B 提供服务。推测服务(qwen-sd-vllm)为相同的 Qwen3-32B 目标模型提供服务,同时添加一个 Qwen3-1.7B 草稿模型,num_speculative_tokens=7。
两个服务在 Trn2(trn2.48xlarge)上以相同配置运行,具有相同的加速器分配、张量并行性(将模型权重分布在多个 NeuronCore 上以适应大型模型)、序列长度、批处理限制和 Neuron DLC 镜像。唯一的区别是为推测服务添加了 Qwen3-1.7B 草稿模型和 num_speculative_tokens=7。有关完整的设置细节,请参见图 2。
为了在相同负载下比较两种配置,我们使用 llmperf 对两个端点生成相同的流量模式。我们使用 CloudWatch Container Insights 捕获基础设施遥测数据,并将请求级自定义指标(TTFT、token 间延迟和端到端延迟)发布到 CloudWatch 仪表板进行并排分析。
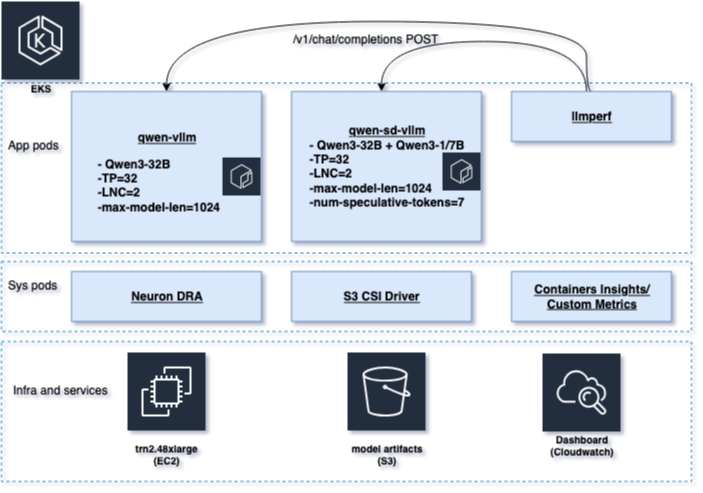
图 2:系统架构
基准测试设置
我们使用 LLMPerf 对基线和推测解码部署运行结构化的解码密集型测试用例。基准测试在 Kubernetes Pod(qwen-llmperf-pod.yaml)内运行,向两个端点发出并发请求并记录 token 级延迟指标。我们的测试用例从高度结构化的提示(重复序列、数字延续、简单代码模式)到开放式自然语言补全,涵盖了推测解码的最佳和最差情况行为。完整的提示集可在示例代码库中找到。
为了清晰起见,我们将分析重点放在两种代表性提示类型上:高度结构化的确定性提示(重复文本生成)和开放式提示。这两种情况说明了推测解码的最佳和最差情况行为。
Pod 以受控的输入和输出长度以及 temperature=0.0 运行 llmperf,以强调确定性解码路径。我们记录并将包括 token 间延迟、TTFT、吞吐量和端到端延迟在内的指标发布到 CloudWatch。
结果
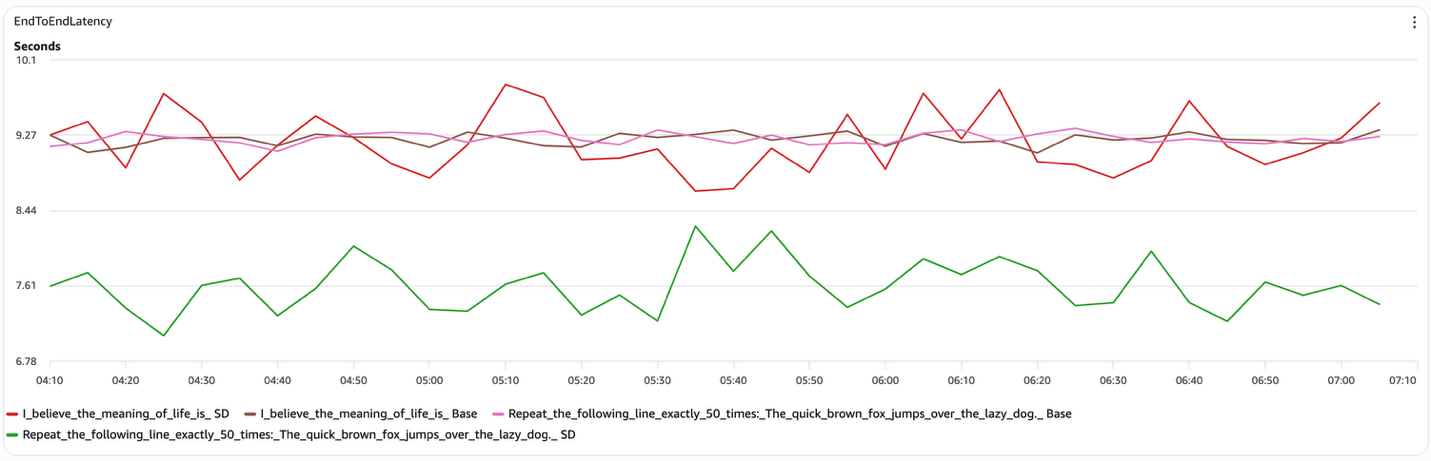
图 3:推测解码端到端延迟
推测解码有选择性地降低延迟:其有效性在很大程度上取决于提示结构,这种依赖性在测量指标中持续出现。以下是每种提示类型的预期效果:
- 结构化提示(例如,“准确重复以下行 50 次”)。推测解码在端到端延迟方面提供了可测量的降低。当草稿模型可靠地预测目标模型会生成什么时,系统跳过了相当一部分目标模型解码步骤。在我们的测试中,token 间延迟降至约 15 毫秒每 token(相比开放式提示约 45 毫秒),推测解码曲线在整个运行过程中始终低于基线。
- 开放式提示(例如,“我认为生命的意义是”)。推测解码没有提供一致的好处。草稿模型经常与目标模型发生偏离,导致 token 拒绝,抵消了潜在的收益。推测解码和基线的端到端延迟曲线基本重叠,两种配置的 token 间延迟都保持在约 45 毫秒每 token 附近。
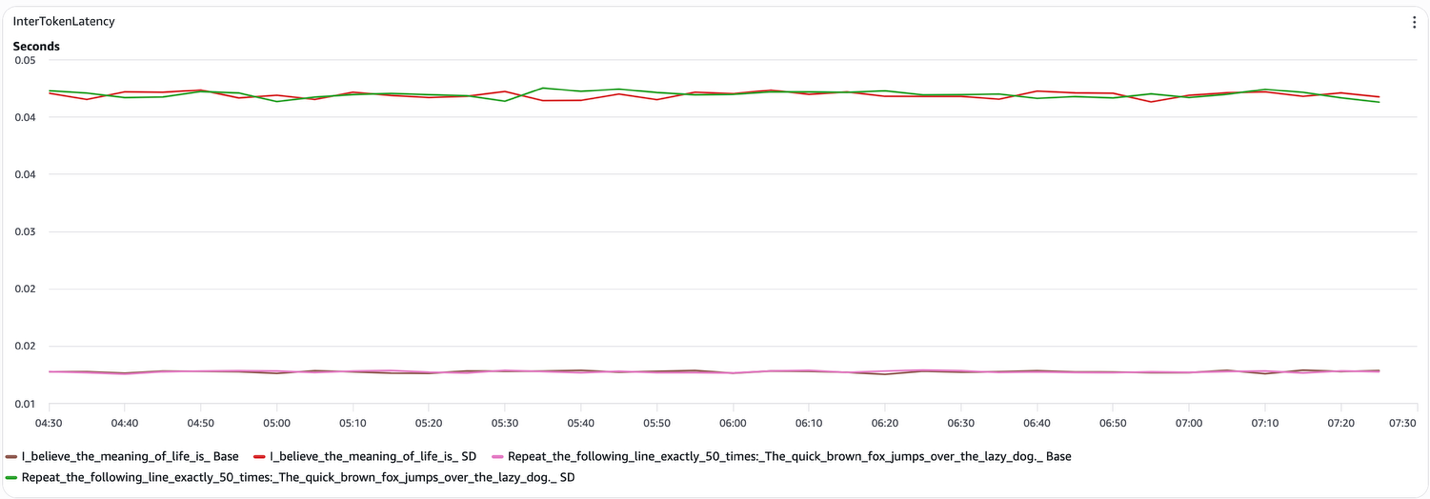
图 4:推测解码 token 间延迟(解码)
TTFT(首个 Token 时间)在各配置中实际保持不变(图 5)。TTFT 主要由预填充阶段决定,即模型编码输入上下文的阶段。推测解码不改变此阶段,因此预填充延迟既不会改善也不会降级。
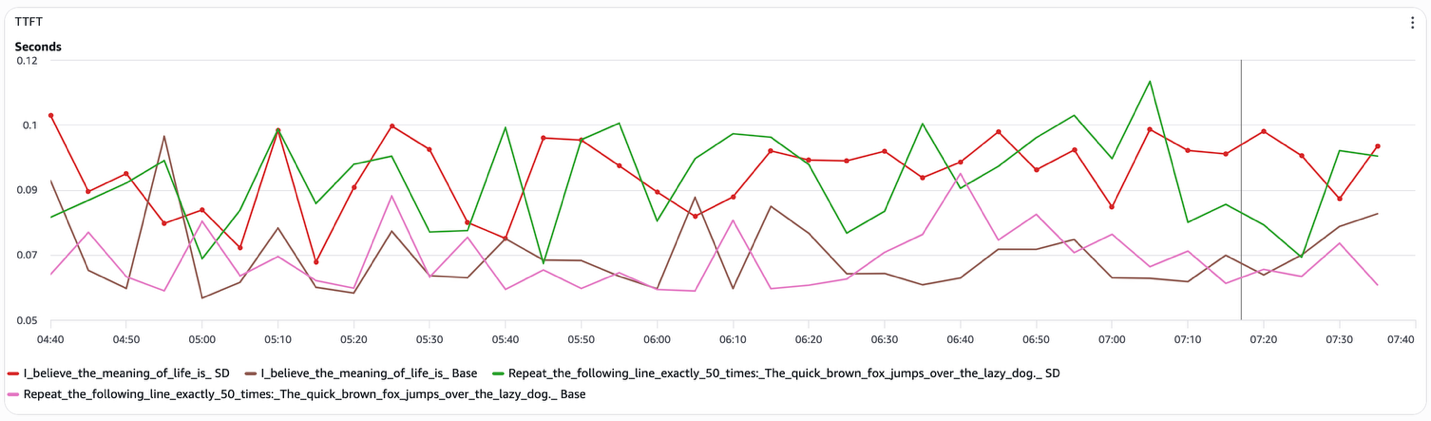
图 5:推测解码 TTFT(预填充)
综合来看,这些结果表明,推测解码通过减少执行的目标模型解码步骤数量来改善总延迟,而不是通过加速解码步骤本身或预填充阶段。这解释了为什么增益出现在结构化提示的端到端延迟中,但在 token 间延迟和 TTFT 中不存在,以及为什么推测解码对开放式生成恢复到基线行为。
重现结果
我们在 AWS Neuron EKS 示例代码库中提供了端到端代码示例和 Kubernetes 配置。该代码库包含:
- 在 Trn2 上部署基线 vLLM 和推测解码 vLLM 服务的 Kubernetes 清单
- 用于在 vLLM 中启用融合推测解码的示例配置标志
- 用于生成负载和收集指标的示例
llmperf基准测试脚本 - 通过 S3 CSI Driver 挂载模型检查点和编译产物的说明
- 配置 Neuron DRA、张量并行和 NeuronCore 放置的指导
这些示例让你能够重现本文中使用的相同实验设置,从模型部署到基准测试和指标收集。
结论
解码密集型 LLM 工作负载受到自回归生成的串行性质的限制。推测解码通过减少产生完整输出所需的目标模型解码步骤数量来打破 AWS Trainium2 上的这一瓶颈,有效增加了每次前向传递生成的 token 数量。对于输出空间可预测的工作负载,例如代码生成、结构化数据提取、模板化报告生成或配置文件合成,这可以直接转化为更低的每个输出 token 成本和更高的吞吐量,而不牺牲质量。推测解码并非普适优化。其有效性取决于提示结构、草稿模型质量和推测参数调整。当应用于正确的工作负载时,它在基于 Trainium 的推理系统上提供了有意义的延迟和成本改善。
后续步骤
要在 AWS Trainium 上开始使用推测解码,请探索以下资源:
- AWS Trainium 产品页面 — 了解 Trainium 实例类型、功能和定价。
- NeuronX 分布式推理开发者指南 — NxDI 的完整文档,包括推测解码配置选项。
- NxDI 推测解码功能指南 — 启用普通、融合、EAGLE 和 Medusa 推测模式的参考文档。
- vLLM 文档 — 了解如何配置 vLLM 用于生产 LLM 服务。
- Amazon EKS 文档 — 在 AWS 上使用 Kubernetes 部署和扩展推理服务的入门指南。
- AWS Neuron EKS 示例代码库 — 重现本文基准测试的端到端代码示例。
- Amazon CloudWatch 文档 — 为监控推理端点设置仪表板和自定义指标。
关于作者
Yahav Biran 是 Amazon 的首席架构师,专注于大规模 AI 工作负载。他为开源项目做出贡献,并在 AWS 博客和学术期刊(包括 AWS 计算和 AI 博客以及《系统工程杂志》)上发表文章。他经常发表技术演讲,并与客户合作设计云应用。Yahav 拥有科罗拉多州立大学系统工程博士学位。
Truong Pham 是 Annapurna Labs(Amazon)的软件工程师。他专注于优化 AWS AI 加速器(如 AWS Inferentia 和 Trainium)上的大型语言模型推理性能,并为 AWS Neuron 软件栈设计对开发者友好的 API。Truong 拥有明尼苏达大学化学工程博士学位。