原文标题:How My Agents Self-Heal in Production
原文链接:https://blog.langchain.com/production-agents-self-heal/
我的 Agent 如何在生产环境中自我修复

作者:Vishnu Suresh,LangChain 软件工程师
“我为我们的 GTM Agent 构建了一条自愈式部署流水线。每次部署后,它会检测回归问题,判断变更是否是其根因,然后启动 Agent 提交修复 PR——在代码审查之前完全无需人工干预。”
发布代码本身并不是难点。真正困难的是之后的一切:弄清楚你的上次部署是否破坏了什么,判断这是否真的是你的问题,以及在用户察觉之前修复它。
自愈流程如何运作
GTM Agent 运行在 Deep Agents 上,并通过 LangSmith Deployments 进行部署。整个系统使用了一个名为 Open SWE 的内部编码 Agent——“一个开源的异步编码 Agent,能够研究代码库、编写修复并提交 PR。”
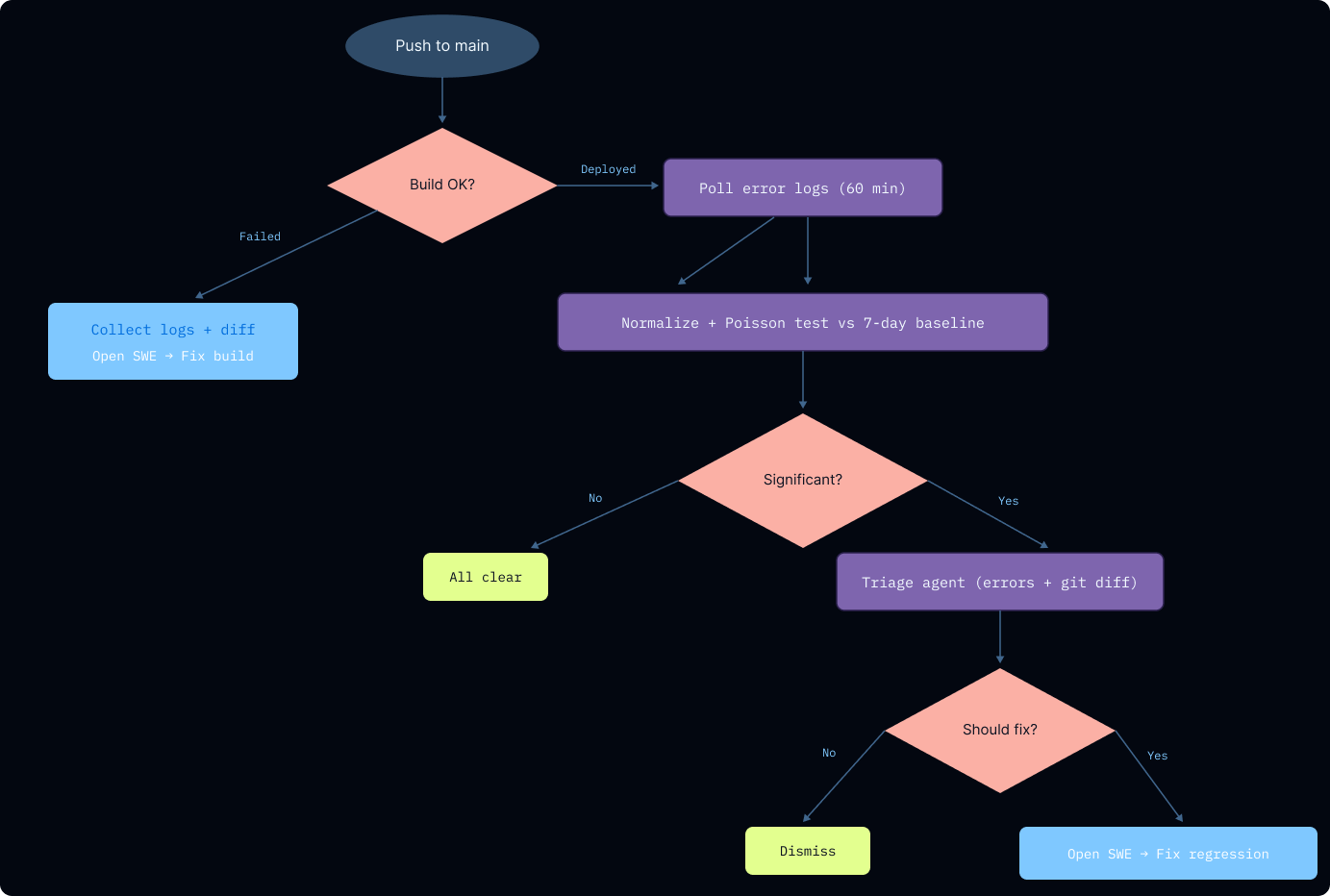
每次向 main 部署后,一个自愈 GitHub Action 会被触发,捕获构建和服务端日志。该流程包含两条路径:立即捕获构建失败,以及在监控窗口内检测服务端回归。
捕获 Docker 构建失败
流水线会检查构建日志中的 Docker 镜像失败。当检测到失败时,“流水线会自动从 CLI 中提取错误日志,获取最近一次提交到 main 的 git diff,然后将其交给 Open SWE——全程无人参与。“
监控部署后的错误
任何生产系统都存在一定的背景错误率——网络超时、第三方 API 问题、瞬态故障。
错误签名归一化
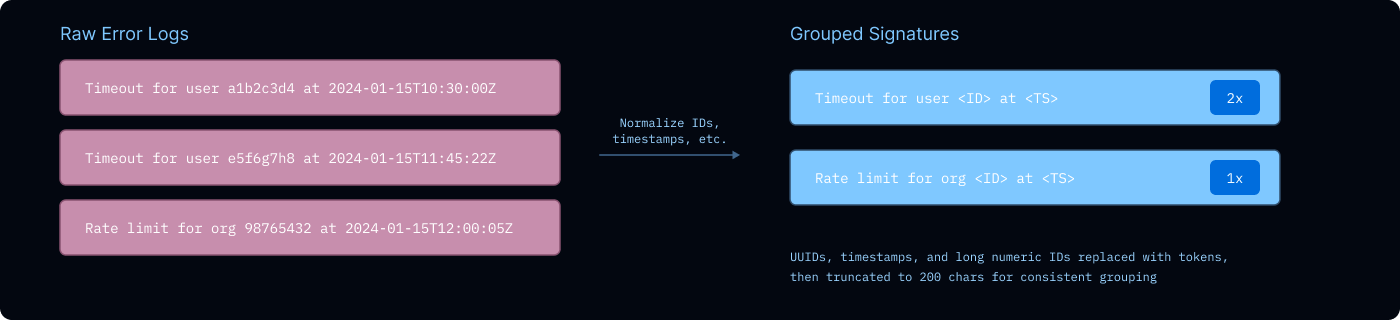
系统会将错误”归一化为错误签名——通过正则替换 UUID、时间戳和长数字字符串,然后截断到 200 个字符,使逻辑上相同的错误被归入同一个桶中。“
使用 Poisson 检验进行门控
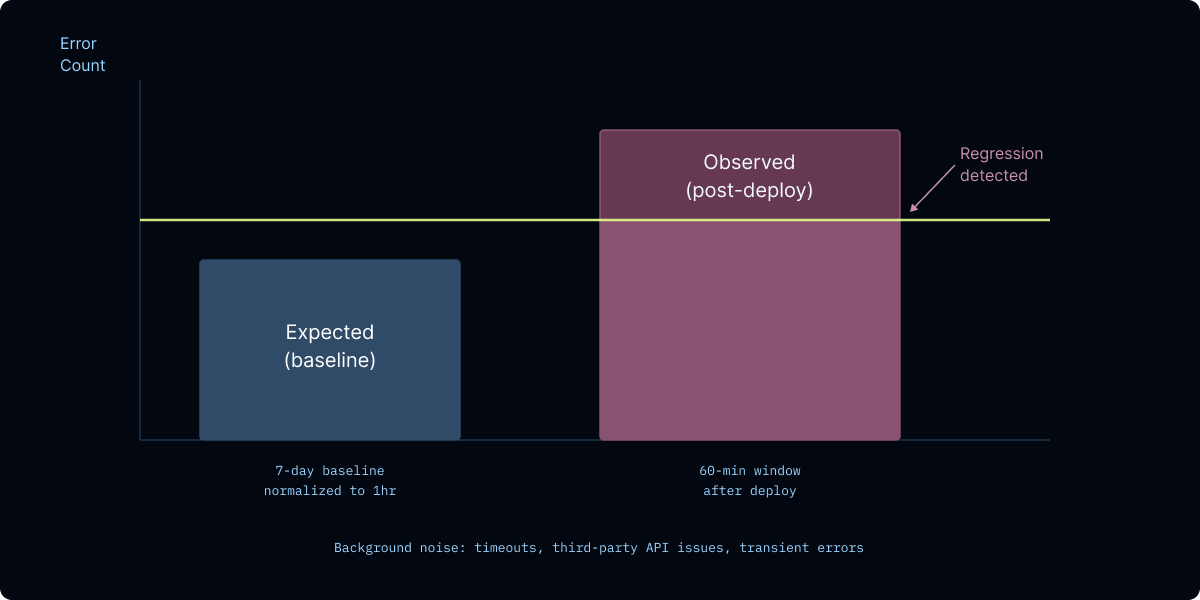
Poisson 分布用于建模在给定已知平均速率(λ)的固定时间间隔内,某事件发生的次数。
“利用 7 天的基线数据,我估算每个错误签名的每小时预期错误率,然后将其缩放到 60 分钟的部署后监控窗口。如果观察到的计数显著超过分布预测值(p < 0.05),我就将其标记为潜在回归。”
对于全新的错误签名,如果它们重复出现,也会被标记。
Triage Agent
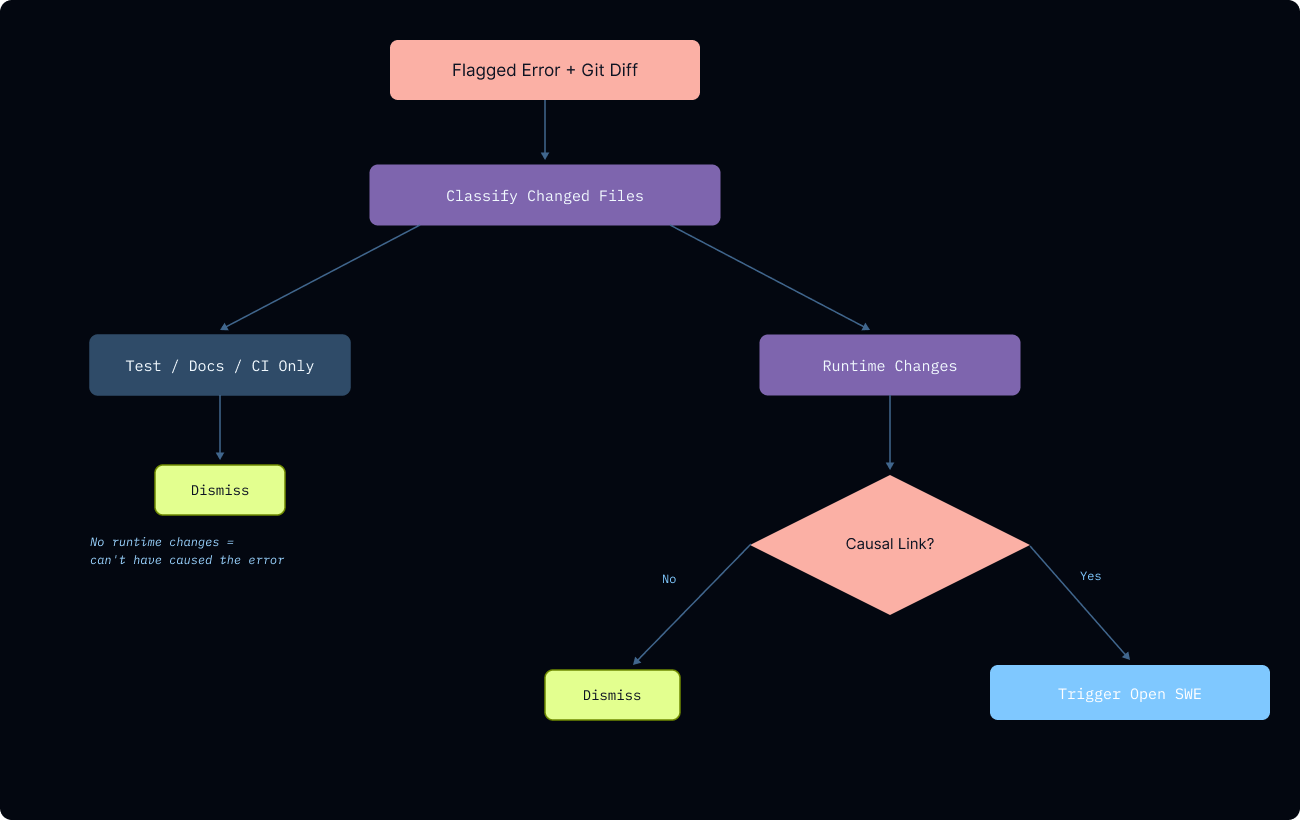
在调用 Open SWE 之前,一个基于 Deep Agents 构建的 Triage Agent 会验证因果关系。它将变更文件分类为”运行时代码、prompt/配置、测试、文档或 CI”。
“对于运行时变更,Agent 必须在 diff 中的特定行与观察到的错误之间建立具体的因果联系。”
如果仅更改了非运行时文件,Triage Agent 会拒绝调查。它返回包含置信度级别和推理过程的结构化判定。
使用 Open SWE 闭环
“一旦 Triage Agent 批准了调查,Open SWE 就会接手,处理 bug 并提交 PR。”
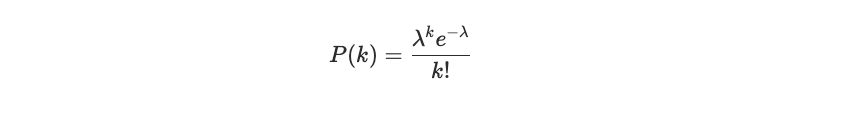
该系统”最有用的场景是捕获那些不会大声崩溃的 bug:返回错误默认值的静默故障、代码与部署之间的配置不匹配,以及级联回归。“
未来改进
更宽的回溯窗口
“Triage Agent 目前只查看当前部署版本与上一次部署版本之间的 diff。“更早引入的 bug 如果延迟浮现,仍然无法被检测到。扩展回溯窗口会引入噪音,使因果归因更加复杂。
更智能的错误分组
当前基于正则的归一化存在局限性。作者建议”将错误消息嵌入向量空间并进行聚类,而不是依赖正则归一化。”
另一种方法参考了 Ramp 的做法——“LLM 读取 diff 并生成针对变更代码的定制化监控器,带有明确的阈值。“
修复前进 vs 回滚
“目前系统总是向前修复——Open SWE 处理 PR 的同时,故障部署仍然在线运行。“改进后的系统应该在高严重性且因果关系不确定的情况下选择回滚。
结语
“我认为这种模式将在部署产品中变得越来越普遍。你的系统越能自主检测、分类和修复自身的回归问题,你就能越快地交付代码。“
引用
- 原文:How My Agents Self-Heal in Production — Vishnu Suresh, LangChain Blog, 2026-04-03
- LangSmith Deployments
- Open SWE