原文标题:Cost-effective multilingual audio transcription at scale with Parakeet-TDT and AWS Batch
原文链接:https://aws.amazon.com/blogs/machine-learning/cost-effective-multilingual-audio-transcription-at-scale-with-parakeet-tdt-and-aws-batch/
许多组织正在归档大型媒体资料库、分析联络中心录音、为 AI 准备训练数据,或处理点播视频以生成字幕。当数据量大幅增长时,托管自动语音识别(ASR)服务的费用往往迅速成为可扩展性的首要限制因素。
为了应对这一成本可扩展性挑战,我们使用 NVIDIA Parakeet-TDT-0.6B-v3 模型,通过 AWS Batch 部署在 GPU 加速实例上。Parakeet-TDT 的令牌与时长转换器(Token-and-Duration Transducer)架构能够同时预测文本令牌及其时长,从而智能跳过静音和冗余处理,实现比实时处理快数个数量级的推理速度。通过仅为短暂的计算峰值付费,而非为音频的完整时长付费,你可以按照本文所述基准测试,以每小时音频仅需几分之一美分的成本进行大规模转录。
本文将介绍如何构建一套可扩展的、事件驱动的转录流水线,该流水线可自动处理上传至 Amazon Simple Storage Service(Amazon S3)的音频文件,并展示如何通过 Amazon EC2 Spot 实例和缓冲流式推理进一步降低成本。
模型能力
Parakeet-TDT-0.6B-v3 于 2025 年 8 月发布,是一款开源多语言 ASR 模型,支持 25 种欧洲语言的自动语言检测,并以 CC-BY-4.0 协议灵活授权。根据 NVIDIA 发布的指标,该模型在清洁条件下的词错误率(WER)为 6.34%,在 0 dB 信噪比下为 11.66%,并支持使用本地注意力模式处理长达三小时的音频。
25 种支持的语言包括:保加利亚语、克罗地亚语、捷克语、丹麦语、荷兰语、英语、爱沙尼亚语、芬兰语、法语、德语、希腊语、匈牙利语、意大利语、拉脱维亚语、立陶宛语、马耳他语、波兰语、葡萄牙语、罗马尼亚语、斯洛伐克语、斯洛文尼亚语、西班牙语、瑞典语、俄语和乌克兰语。这有助于避免在服务欧洲国际市场时需要为不同语言配置独立模型或进行针对性配置的需要。在 AWS 上部署时,该模型需要配备至少 4 GB 显存的 GPU 实例,但 8 GB 显存能提供更好的性能。根据我们的测试,G6 实例(NVIDIA L4 GPU)在推理工作负载上提供最佳成本性能比。该模型在 G5(A10G)、G4dn(T4)上同样表现良好;如需最大吞吐量,可选用 P5(H100)或 P4(A100)实例。
解决方案架构
流程从你向 S3 存储桶上传音频文件开始。这会触发一条 Amazon EventBridge 规则,向 AWS Batch 提交一个任务。AWS Batch 配置 GPU 加速计算资源,已配置的实例从 Amazon Elastic Container Registry(Amazon ECR)拉取预缓存了模型的容器镜像。推理脚本下载并处理文件,然后将带时间戳的 JSON 转录结果上传至输出 S3 存储桶。该架构在空闲时自动缩减至零,因此只有在活跃计算期间才会产生费用。
如需深入了解通用架构组件,请参阅我们此前的文章:由 AWS Batch 和 AWS Inferentia 驱动的 Whisper 音频转录。
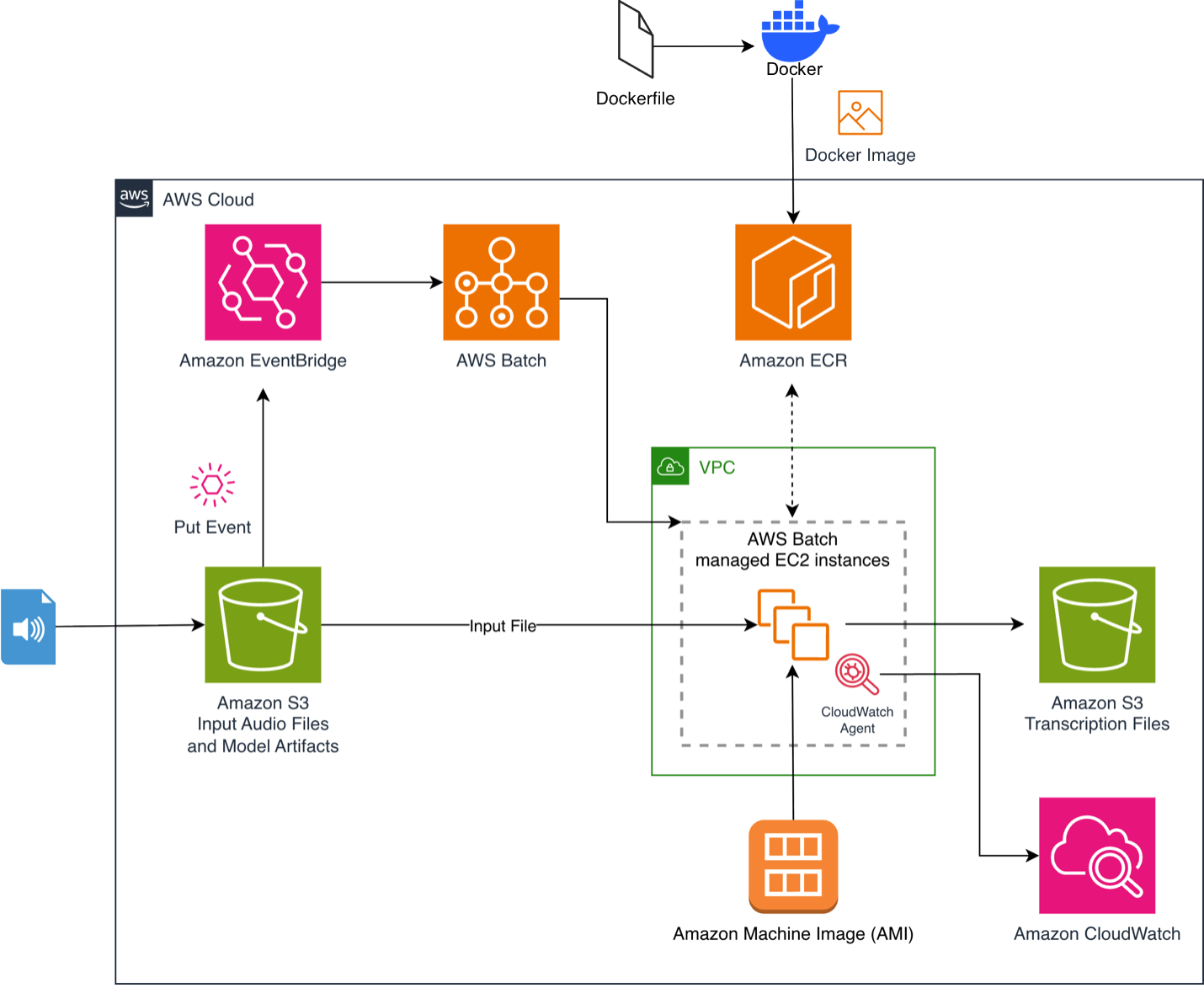
图 1. 基于 Amazon EventBridge 和 AWS Batch 的事件驱动音频转录流水线
前置条件
-
如果还没有 AWS 账户,请创建一个并登录。按照添加用户中的说明,使用 AWS IAM Identity Center 创建一个拥有完整管理员权限的用户。
-
在你的本地开发机器上安装 AWS 命令行界面(AWS CLI),并按照配置 AWS CLI 中的说明为管理员用户创建配置文件。
-
在你的本地机器上安装 Docker。
-
将 GitHub 仓库克隆至本地机器。
构建容器镜像
该仓库提供了一个 Dockerfile,用于构建针对推理性能优化的精简容器镜像。镜像以 Amazon Linux 2023 为基础,安装 Python 3.12,并在构建期间预缓存 Parakeet-TDT-0.6B-v3 模型,以消除运行时的下载延迟:
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
WORKDIR /app
# Install system dependencies, Python 3.12, and ffmpeg
RUN dnf update -y && \
dnf install -y gcc-c++ python3.12-devel tar xz && \
ln -sf /usr/bin/python3.12 /usr/local/bin/python3 && \
python3 -m ensurepip && \
python3 -m pip install --no-cache-dir --upgrade pip && \
dnf clean all && rm -rf /var/cache/dnf
# Install Python dependencies and pre-cache the model
COPY ./requirements.txt requirements.txt
RUN pip install -U --no-cache-dir -r requirements.txt && \
rm -rf ~/.cache/pip /tmp/pip* && \
python3 -m compileall -q /usr/local/lib/python3.12/site-packages
COPY ./parakeet_transcribe.py parakeet_transcribe.py
# Cache model during build to eliminate runtime download
RUN python3 -c "from nemo.collections.asr.models import ASRModel; \
ASRModel.from_pretrained('nvidia/parakeet-tdt-0.6b-v3')"
CMD ["python3", "parakeet_transcribe.py"]推送至 Amazon ECR
该仓库提供了一个 updateImage.sh 脚本,用于处理环境检测(CodeBuild 或 EC2)、构建容器镜像、在需要时创建 ECR 仓库、启用漏洞扫描,并推送镜像。运行方式如下:
./updateImage.sh部署解决方案
本解决方案使用 AWS CloudFormation 模板(deployment.yaml)来配置基础设施。buildArch.sh 脚本通过检测你的 AWS 区域、收集 VPC、子网和安全组信息,并部署 CloudFormation 堆栈来自动化部署过程:
./buildArch.sh该脚本在底层执行以下命令:
aws cloudformation deploy --stack-name batch-gpu-audio-transcription \
--template-file ./deployment.yaml \
--capabilities CAPABILITY_IAM \
--region ${AWS_REGION} \
--parameter-overrides VPCId=${VPC_ID} SubnetIds="${SUBNET_IDS}" \
SGIds="${SecurityGroup_IDS}" RTIds="${RouteTable_IDS}"CloudFormation 模板会创建以下资源:使用 G6 和 G5 GPU 实例的 AWS Batch 计算环境、任务队列、引用你的 ECR 镜像的任务定义、启用了 EventBridge 通知的输入和输出 S3 存储桶,以及在 S3 上传时触发 Batch 任务的 EventBridge 规则、用于 GPU/CPU/内存监控的 Amazon CloudWatch agent 配置,以及具有最小权限策略的 IAM 角色。AWS Batch 支持通过在计算环境配置中指定 ImageType: ECS_AL2023_NVIDIA 来选择 Amazon Linux 2023 GPU 镜像。
或者,你也可以通过仓库 README 中提供的启动链接,直接从 AWS CloudFormation 控制台进行部署。
配置 Spot 实例
Amazon EC2 Spot 实例可以利用闲置的 EC2 算力,以最高 90% 的折扣(具体取决于实例类型)运行工作负载,从而进一步降低成本。要启用 Spot 实例,我们需要修改 deployment.yaml 中的计算环境配置:
DefaultComputeEnv:
Type: AWS::Batch::ComputeEnvironment
Properties:
Type: MANAGED
State: ENABLED
ComputeResources:
AllocationStrategy: SPOT_PRICE_CAPACITY_OPTIMIZED
Type: SPOT
BidPercentage: 100
InstanceTypes:
- "g6.xlarge"
- "g6.2xlarge"
- "g5.xlarge"
MinvCpus: !Ref DefaultCEMinvCpus
MaxvCpus: !Ref DefaultCEMaxvCpus
# ... 其余配置不变你可以在运行 aws cloudformation deploy 时通过添加 --parameter-overrides UseSpotInstances=Yes 来启用此配置。SPOT_PRICE_CAPACITY_OPTIMIZED 分配策略会选择中断可能性最小且价格最低的 Spot 实例池。多元化实例类型(G6 xlarge、G6 2xlarge、G5 xlarge)可以提高 Spot 可用性。将 MinvCpus 设置为 0 可确保环境在空闲时自动缩减至零,从而避免在工作负载之间产生费用。由于 ASR 任务是无状态且幂等的,因此非常适合 Spot 实例。如果实例被回收,AWS Batch 会自动重试任务(在任务定义中配置了最多 2 次重试)。
管理长音频的内存问题
Parakeet-TDT 模型的内存消耗随音频时长线性增长。Fast Conformer 编码器必须为完整音频信号生成并存储特征表示,这产生了直接的依赖关系——音频时长翻倍,显存使用量大致也会翻倍。根据模型说明卡,在全注意力模式下,模型在 80 GB 显存的条件下最多可处理 24 分钟的音频。
NVIDIA 通过本地注意力(local attention)模式解决了这一问题,该模式支持在 80 GB A100 上处理长达 3 小时的音频:
# Enable local attention for long audio
asr_model.change_attention_model("rel_pos_local_attn", [128, 128])
asr_model.change_subsampling_conv_chunking_factor(1) # auto select
asr_model.transcribe(["input_audio.wav"])这可能会带来轻微的精度损失,我们建议在你的具体使用场景上进行测试。
缓冲流式推理
对于超过 3 小时的音频,或者需要在 g6.xlarge 等标准硬件上经济高效地处理长音频时,我们使用缓冲流式推理。这项技术改编自 NVIDIA NeMo 的流式推理示例,以重叠块而非加载完整上下文的方式处理音频。
我们配置 20 秒的块长,5 秒的左上下文和 3 秒的右上下文,以保持块边界处的转录质量(注意,更改这些参数可能会降低精度,请通过实验找到最优配置;减小 chunk_secs 会增加处理时间):
# Streaming inference loop
while left_sample < audio_batch.shape[1]:
# add samples to buffer
chunk_length = min(right_sample, audio_batch.shape[1]) - left_sample
# [Logic to manage buffer and flags omitted for brevity]
buffer.add_audio_batch_(...)
# Encode using full buffer [left-chunk-right]
encoder_output, encoder_output_len = asr_model(
input_signal=buffer.samples,
input_signal_length=buffer.context_size_batch.total(),
)
# Decode only chunk frames (constant memory usage)
chunk_batched_hyps, _, state = decoding_computer(...)
# Advance sliding window
left_sample = right_sample
right_sample = min(right_sample + context_samples.chunk, audio_batch.shape[1])以固定块大小处理音频将显存使用量与音频总时长解耦,使单个 g6.xlarge 实例能够以与处理 10 分钟音频相同的内存占用来处理 10 小时的音频文件。
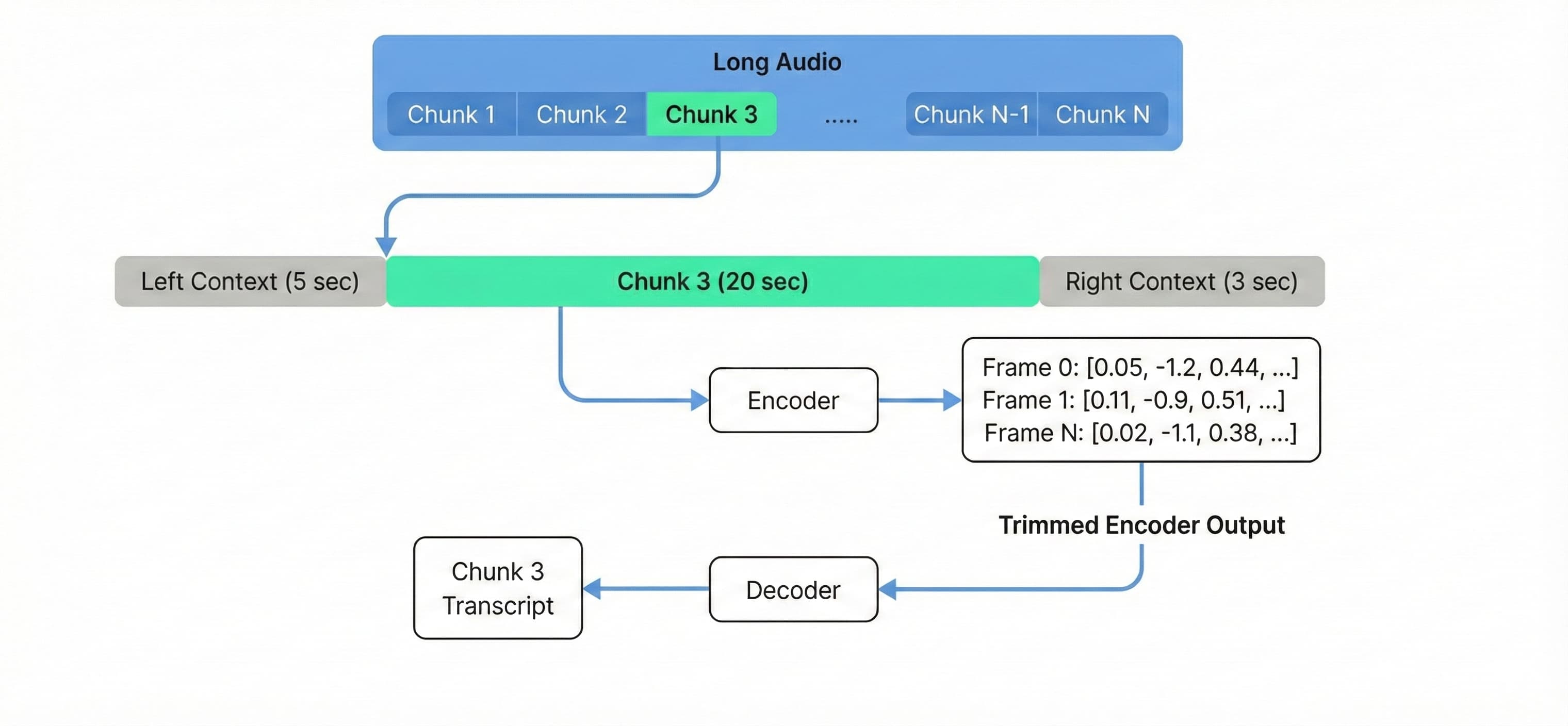
图 2. 缓冲流式推理以恒定内存使用量的重叠块方式处理音频。
要在启用缓冲流式推理的情况下部署,请设置 EnableStreaming=Yes 参数:
aws cloudformation deploy \
--stack-name batch-gpu-audio-transcription \
--template-file ./deployment.yaml \
--capabilities CAPABILITY_IAM \
--parameter-overrides EnableStreaming=Yes \
VPCId=your-vpc-id SubnetIds=your-subnet-ids SGIds=your-sg-ids RTIds=your-rt-ids测试与监控
为了在规模上验证解决方案,我们进行了一次实验:在 100 个 g6.xlarge 实例上分发了 1,000 个相同的 50 分钟音频文件(来自一场 NASA 发射前机组成员新闻发布会),每个实例处理 10 个文件。
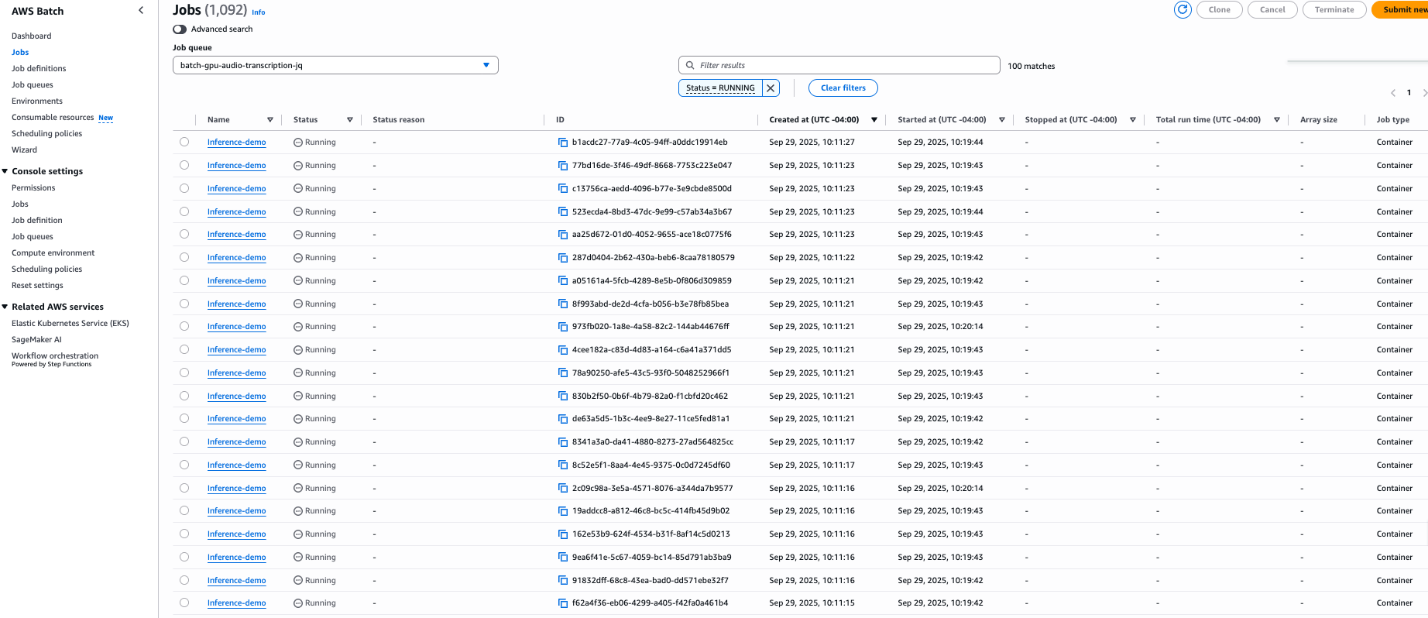
图 3. Batch 任务在 100 个 g6.xlarge 实例上并发运行。
该部署方案包含一个 Amazon CloudWatch agent 配置,以 10 秒为间隔采集 GPU 利用率、功耗、显存使用量、CPU 利用率、内存消耗和磁盘使用量等指标。这些指标显示在 CWAgent 命名空间下,便于你构建实时监控仪表板。
性能与成本分析
为了验证架构的效率,我们使用多个长音频文件对系统进行了基准测试。
Parakeet-TDT-0.6B-v3 模型实现了每分钟音频 0.24 秒的原始推理速度。然而,完整流水线还包括加载模型至内存、加载音频、预处理输入和后处理输出等开销。由于这些开销的存在,最优的成本节省效果出现在长音频处理场景中,因为长音频能最大化处理时间的占比。
基准测试结果(g6.xlarge):
- 音频时长: 3 小时 25 分钟(205 分钟)
- 任务总耗时: 100 秒
- 有效处理速度: 每分钟音频 0.49 秒
- 成本分析
基于 us-east-1 区域的 g6.xlarge 实例定价,我们可以估算每分钟音频处理的成本:
| 定价模型 | g6.xlarge 每小时成本* | 每分钟音频成本 |
|---|---|---|
| 按需实例 | ~$0.805 | $0.00011 |
| Spot 实例 | ~$0.374 | $0.00005 |
*价格基于撰写本文时 us-east-1 区域的费率估算。Spot 价格因可用区而异,随时可能变动。
这一对比凸显了自托管方式在高吞吐量工作负载中的经济优势,与托管 API 服务相比,在大规模转录场景下具有显著的价值。
资源清理
为避免产生后续费用,请删除本解决方案创建的资源:
-
清空所有 S3 存储桶(输入、输出和日志)。
-
删除 CloudFormation 堆栈:
aws cloudformation delete-stack --stack-name batch-gpu-audio-transcription- 可选:删除 ECR 仓库和容器镜像。
详细清理说明请参阅仓库 README 的清理部分。
总结
本文介绍了如何构建一套以每小时音频仅需几分之一美分的成本大规模处理音频的转录流水线。通过将 NVIDIA 的 Parakeet-TDT-0.6B-v3 模型与 AWS Batch 和 EC2 Spot 实例相结合,你可以在 25 种欧洲语言上进行带自动语言检测的转录,与其他方案相比有助于降低成本。缓冲流式推理技术将这一能力扩展至任意时长的音频(使用标准硬件即可),而事件驱动架构则可从零自动扩展以应对变化的工作负载。
如需快速上手,请探索 GitHub 仓库中的示例代码。
关于作者
Gleb Geinke 是 AWS 生成式 AI 创新中心的深度学习架构师。Gleb 与企业客户直接合作,为复杂的业务挑战设计和扩展变革性的生成式 AI 解决方案。
Justin Leto 是 AWS 私募股权团队的全球首席解决方案架构师。Justin 是由 APRESS 出版的《Data Engineering with Generative and Agentic AI on AWS》一书的作者。
Yusong Wang 是 AWS 的首席高性能计算(HPC)专家解决方案架构师,拥有超过 20 年横跨国家级研究机构和大型金融企业的工作经验。
Brian Maguire 是 Amazon Web Services 的首席解决方案架构师,专注于帮助客户在云端实现创意。Brian 是《Scalable Data Streaming with Amazon Kinesis》的合著者。