原文标题:Optimize video semantic search intent with Amazon Nova Model Distillation on Amazon Bedrock
原文链接:https://aws.amazon.com/blogs/machine-learning/optimize-video-semantic-search-intent-with-amazon-nova-model-distillation-on-amazon-bedrock/
优化视频语义搜索模型需要在准确性、成本和延迟之间取得平衡。更快、更小的模型缺乏路由智能,而更大、更准确的模型则会增加显著的延迟开销。在本系列第一部分中,我们展示了如何在 AWS 上使用 Amazon Bedrock 中的 Anthropic Claude Haiku 模型,构建具有智能意图路由的多模态视频语义搜索系统。虽然 Haiku 模型对用户搜索意图提供了很强的准确性,但它将端到端搜索时间增加到了 2-4 秒,占总延迟的 75%。
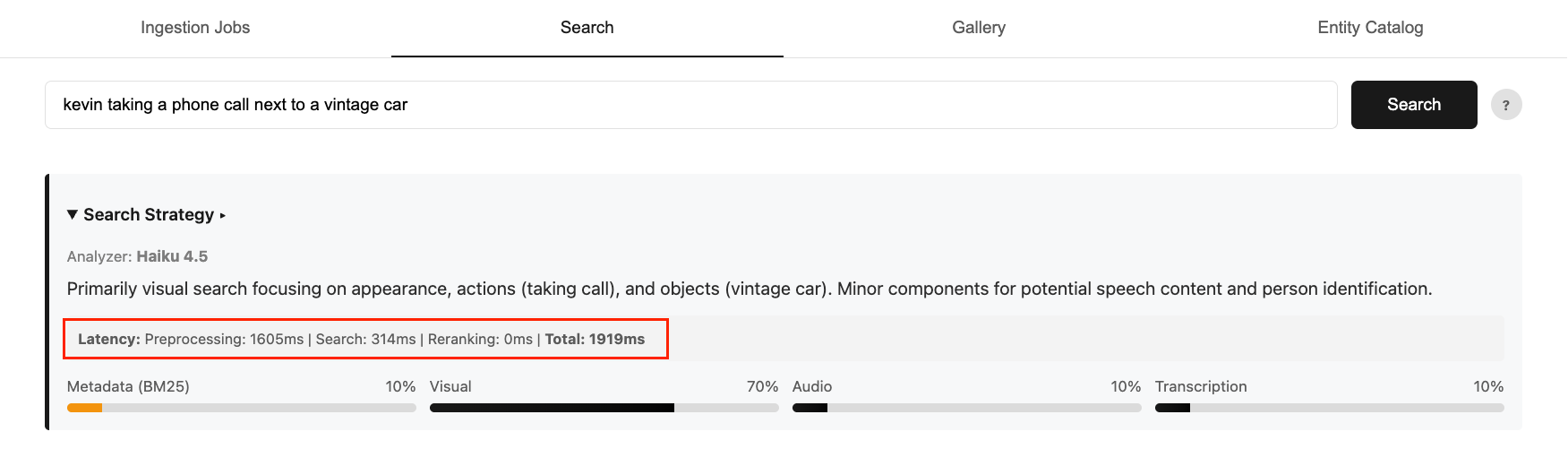
图 1:端到端查询延迟分解示例
现在考虑路由逻辑变得更加复杂时会发生什么。企业级元数据可能远比我们示例中的五个属性(标题、字幕、人物、类型和时间戳)复杂得多。客户可能还需要考虑摄像机角度、情绪与情感、版权和授权窗口,以及更多特定领域的分类法。更细腻的逻辑意味着更繁重的提示词,而更繁重的提示词导致更昂贵、更慢的响应。这正是模型定制发挥作用的地方。与其在”速度快但过于简单”和”准确但过于昂贵或缓慢”之间选择,我们可以通过训练一个小模型以更低的延迟和成本准确执行任务,三者兼得。
在这篇文章中,我们将介绍如何使用 Amazon Bedrock 上的模型定制技术——模型蒸馏(Model Distillation),将路由智能从大型教师模型(Amazon Nova Premier)迁移到更小的学生模型(Amazon Nova Micro)。这种方法在保持任务所需的细腻路由质量的同时,将推理成本降低超过 95%,延迟减少 50%。
解决方案概述
我们将在 Jupyter Notebook 中端到端地演示完整的蒸馏管道。从高层次看,Notebook 包含以下步骤:
- 准备训练数据 — 使用 Nova Premier 生成 10,000 个合成标注示例,并以 Bedrock 蒸馏格式上传数据集到 Amazon Simple Storage Service (Amazon S3)
- 运行蒸馏训练任务 — 配置教师和学生模型标识符,通过 Amazon Bedrock 提交任务
- 部署蒸馏后的模型 — 使用按需推理部署自定义模型,实现灵活的按用量付费
- 评估蒸馏后的模型 — 使用 Amazon Bedrock 模型评估 将路由质量与基础 Nova Micro 和原始 Claude Haiku 基线进行对比
完整的 Notebook、训练数据生成脚本和评估工具可在 GitHub 仓库 中获取。
准备训练数据
我们选择模型蒸馏而非其他定制技术(如监督微调(SFT))的一个关键原因,是蒸馏不需要完全标注的数据集。使用 SFT 时,每个训练示例都需要人工生成的响应作为真实标签。而使用蒸馏,你只需要提示词。Amazon Bedrock 会自动调用教师模型生成高质量响应,并在后台应用数据合成和增强技术,生成多达 15,000 个提示-响应对的多样化训练数据集。
话虽如此,如果你想对训练信号有更多控制,也可以提供标注数据集。JSONL 文件中的每条记录遵循 bedrock-conversation-2024 模式,其中 user 角色(输入提示词)是必填的,assistant 角色(期望响应)是可选的。以下是示例,详见为蒸馏准备训练数据集:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [{ "text": "Return JSON with visual, audio, transcription, metadata weights (sum=1.0) and reasoning for the given video search query." }],
"messages": [
{
"role": "user",
"content": [{ "text": "Olivia talking about growing up in poverty" }]
},
{
"role": "assistant",
"content": [{ "text": "{\"visual\": 0.2, \"audio\": 0.1, \"transcription\": 0.6, \"metadata\": 0.1, \"reasoning\": \"The query focuses on spoken content ('talking about'), making transcription most important. Visual and audio elements are secondary since they support the context, while metadata is minimal.\"}" }]
}
]
}在本文中,我们使用 Nova Premier(Nova 家族中最大、能力最强的模型)准备了 10,000 个合成标注示例。数据在视觉、音频、转录和元数据信号查询之间均匀分布,示例涵盖所有预期搜索输入的范围,代表不同难度级别,包含边缘案例和变体,并防止对狭窄查询模式的过拟合。下图展示了四个模态通道的权重分布。
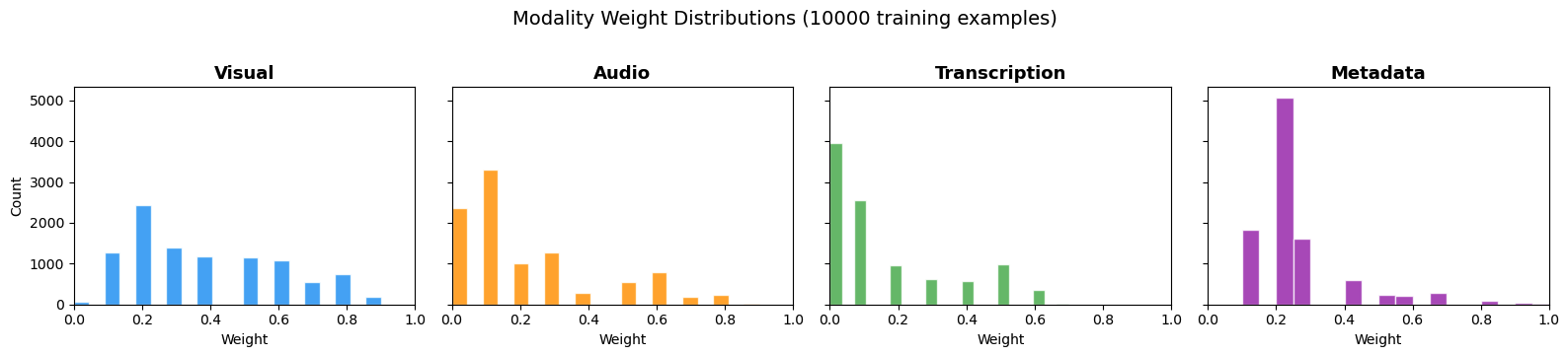
图 2:10,000 个训练示例的权重分布
如果你需要更多示例或希望将查询分布适配到自己的内容领域,可以使用提供的 generate_training_data.py 脚本,通过 Nova Premier 合成生成更多训练数据。
运行蒸馏训练任务
将训练数据上传到 Amazon S3 后,下一步是提交蒸馏任务。模型蒸馏通过使用你的提示词,首先从教师模型生成响应,然后使用这些提示-响应对对学生模型进行微调。在本项目中,教师是 Amazon Nova Premier,学生是 Amazon Nova Micro——一个为高吞吐量推理优化的快速、经济高效的模型。教师的路由决策成为塑造学生行为的训练信号。
Amazon Bedrock 自动管理整个训练编排和基础设施。无需集群配置、无需超参数调整,也无需教师到学生的模型管道设置。你只需指定教师模型、学生模型、训练数据的 S3 路径,以及具有必要权限的 AWS Identity and Access Management(IAM)角色。Bedrock 处理其余一切。以下是触发蒸馏训练任务的示例代码片段:
import boto3
from datetime import datetime
bedrock_client = boto3.client(service_name="bedrock")
teacher_model = "us.amazon.nova-premier-v1:0"
student_model = "amazon.nova-micro-v1:0:128k"
job_name = f"video-search-distillation-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
model_name = "nova-micro-video-router-v1"
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=distillation_role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={"s3Uri": training_s3_uri},
outputDataConfig={"s3Uri": output_s3_uri},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": 1000
}
}
}
)
job_arn = response['jobArn']任务以异步方式运行。你可以在 Amazon Bedrock 控制台的基础模型 > 自定义模型下监控进度,或通过编程方式查询:
status = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job status: {status}") # Training, Complete, or Failed训练时间因数据集大小和所选学生模型而异。对于使用 Nova Micro 的 10,000 个标注示例,预计任务将在几小时内完成。
部署蒸馏后的模型
蒸馏任务完成后,自定义模型将在你的 Amazon Bedrock 账户中可用并准备好部署。Amazon Bedrock 为自定义模型提供两种部署选项:适用于可预测、高容量工作负载的预配吞吐量,以及适合灵活按用量付费的按需推理(无需前期承诺)。
对于大多数刚起步的团队,推荐按需推理路径。无需端点配置,无需按小时承诺,也没有最低使用要求。以下是部署代码:
import uuid
deployment_name = f"nova-micro-video-router-{datetime.now().strftime('%Y-%m-%d')}"
response = bedrock_client.create_custom_model_deployment(
modelDeploymentName=deployment_name,
modelArn=custom_model_arn,
description="Distilled Nova Micro for video search modality weight prediction (4 weights)",
tags=[
{"key": "UseCase", "value": "VideoSearch"},
{"key": "Version", "value": "v2-4weights"},
],
clientRequestToken=f"deployment-{uuid.uuid4()}",
)
deployment_arn = response['modelDeploymentArn']
print(f"Deployment ARN: {deployment_arn}")一旦状态显示 InService,你就可以像使用任何其他基础模型一样,通过标准 InvokeModel 或 Converse API 调用蒸馏后的模型。你只需按 Nova Micro 推理费率支付所消耗的 Token 费用:输入 Token $0.000035/千 Token,输出 Token $0.000140/千 Token。
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
custom_model_arn = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn
)['outputModelArn']
response = bedrock_runtime.converse(
modelId=custom_model_arn,
messages=[
{
"role": "user",
"content": [{"text": query}]
}
]
)
routing_weights = json.loads(
response['output']['message']['content']['text']
)
print(routing_weights)
# {"visual": 0.7, "audio": 0.1, "transcription": 0.1, "metadata": 0.1}评估蒸馏后的模型
在与原始路由器对比之前,值得先验证蒸馏是否改善了基础模型执行路由任务的能力。下表展示了同一提示词分别通过基础 Nova Micro 和蒸馏后的 Nova Micro 处理的结果对比。
| 查询 | 蒸馏后的 Nova Micro | 基础 Nova Micro |
|---|---|---|
"CEO discussing quarterly earnings" | {"visual": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "The query focuses on spoken content (transcription) about earnings, but visual cues (CEO's appearance) and audio (tone/clarity) are also important..."} | 以下是针对关于 CEO 讨论季度收益的视频搜索查询的 JSON 表示:````json{ “video”: { “visual”: 0.3, “audio”: 0.3, “transcription”: 0.2, “metadata”: 0.1, …`(格式不规范) |
"sunset over mountains" | {"visual": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "The query focuses on a visual scene (sunset over mountains), with no audio or transcription elements. Metadata might include location or time-related tags."} | 以下是针对”日落于山峦”视频搜索查询的 JSON 表示:````json{ “query”: “sunset over mountains”, “results”: [ { “video_id”: “123456”, “visual”: 0.4, …`(格式不规范) |
基础模型在指令遵循和输出格式一致性方面都存在困难。它生成自由文本响应、不完整的 JSON,以及非数值的权重值。蒸馏后的模型始终返回格式良好的 JSON,包含四个总和为 1.0 的数值权重,符合路由管道所需的模式。
与原始 Claude Haiku 路由器对比时,两个模型都针对由 Nova Premier 生成的 100 个标注示例的保留集进行评估。我们使用 Amazon Bedrock 模型评估在结构化、托管的工作流中运行对比。为了超越标准指标评估路由质量,我们定义了一个自定义的 OverallQuality 评分标准(见下方代码块),指示 Claude Sonnet 对每个预测在两个维度上评分:与真实标签的权重准确性和推理质量。每个维度映射到具体的 5 分阈值,因此该标准既惩罚数值偏差,也惩罚泛化的模板式推理。
"rating_scale": [
{"definition": "Weights within 0.05 of reference. Reasoning is specific and consistent.",
"value": {"floatValue": 5.0}},
{"definition": "Weights within 0.10 of reference. Reasoning is clear and mostly consistent.",
"value": {"floatValue": 4.0}},
{"definition": "Dominant modality matches. Avg error < 0.15. Reasoning is present but generic.",
"value": {"floatValue": 3.0}},
{"definition": "Dominant modality wrong OR avg error > 0.15. Reasoning vague or inconsistent.",
"value": {"floatValue": 2.0}},
{"definition": "Unparseable JSON, missing keys, or error > 0.30. No useful reasoning.",
"value": {"floatValue": 1.0}},
]蒸馏后的 Nova Micro 模型获得了 4.0/5 的大语言模型评判分数,与 Claude 4.5 Haiku 的路由质量几乎相同,延迟约为其一半(833ms vs 1741ms)。成本优势同样显著。切换到蒸馏后的 Nova Micro 模型,在按需计价下,输入和输出 Token 的推理成本都降低了超过 95%,且无需前期承诺。注意: 大语言模型评判评估具有非确定性,不同运行间分数可能略有差异。
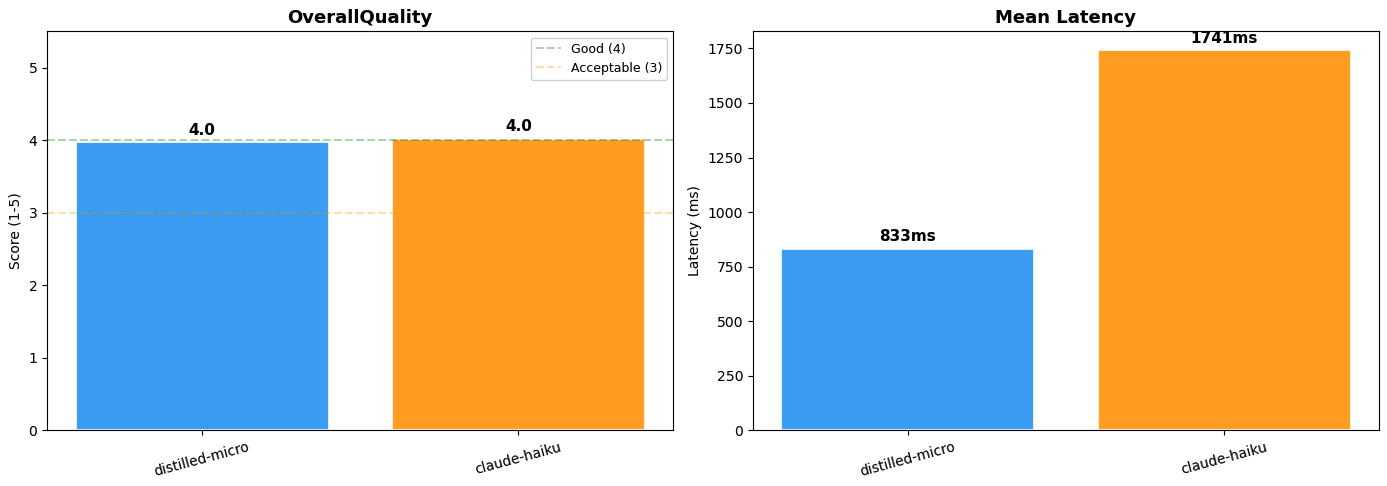
图 3:模型性能对比(蒸馏后的 Nova Micro vs Claude 4.5 Haiku)
以下是并排结果的汇总表:
| 指标 | 蒸馏后的 Nova Micro | Claude 4.5 Haiku |
|---|---|---|
| LLM 评判分数 | 4.0 / 5 | 4.0 / 5 |
| 平均延迟 | 833ms | 1,741ms |
| 输入 Token 成本 | $0.000035 / 1K | $0.80–$1.00 / 1K |
| 输出 Token 成本 | $0.000140 / 1K | $4.00–$5.00 / 1K |
| 输出格式 | 一致的 JSON | 不一致 |
清理资源
为避免持续产生费用,请运行 Notebook 的清理部分,删除所有已预配的资源,包括已部署的模型端点和存储在 Amazon S3 中的任何数据。
结论
本文是两部分系列的第二篇。在第一部分的基础上,本文重点介绍如何应用模型蒸馏来优化视频语义搜索解决方案中构建的意图路由层。所讨论的技术有助于解决真实的生产权衡问题,例如在规模化时平衡路由智能与延迟和成本,同时保持搜索准确性。通过使用 Amazon Bedrock 模型蒸馏将 Amazon Nova Premier 的路由行为蒸馏到 Amazon Nova Micro,我们将推理成本降低了超过 95%,预处理延迟减少了一半,同时保留了任务所需的细腻路由质量。如果你正在大规模运营多模态视频搜索,模型蒸馏是实现生产级成本效率而不牺牲搜索准确性的实用路径。要探索完整实现,请访问 GitHub 仓库并亲自尝试该解决方案。
关于作者

Amit Kalawat
Amit Kalawat 是 Amazon Web Services 驻纽约的首席解决方案架构师。他与企业客户合作,助力其业务转型和云计算之旅。

James Wu
James Wu 是 AWS 的首席 GenAI/ML 专家解决方案架构师,帮助企业设计和执行 AI 转型战略。他专注于生成式 AI、智能体系统和媒体供应链自动化,是知名会议演讲者和技术作者。在加入 AWS 之前,他曾担任工程师、开发人员和技术领导超过 10 年,在工程和营销行业积累了丰富经验。

Bimal Gajjar
Bimal Gajjar 是 AWS 的高级解决方案架构师,与全球客户合作设计、采用和部署可扩展的云存储和数据解决方案。拥有超过 25 年与 HPE、Dell EMC 和 Pure Storage 等领先 OEM 合作的经验,Bimal 将深厚的技术专长与战略商业洞察相结合,这些洞察来源于他在售前架构和全球服务交付方面的端到端参与。