原文标题:Introducing Gemma 3n: The developer guide
原文链接:https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/
第一个 Gemma 模型于去年年初发布,此后已发展成为一个拥有超过 1.6 亿次累计下载量的繁荣 Gemmaverse 生态系统。这个生态系统涵盖了我们超过十几个专业模型的家族,涉及从安全防护到医疗应用等各类场景,最令人振奋的是社区带来的无数创新。从 Roboflow 构建企业级计算机视觉,到东京科学大学打造高性能的日语 Gemma 变体,你们的工作为我们指明了前进的方向。
在这一势头的基础上,我们很高兴地宣布 Gemma 3n 的完整版正式发布。上个月的预览版虽然展示了它的一角,但今天我们将释放这一移动优先架构的完整能力。Gemma 3n 是为帮助塑造 Gemma 的开发者社区而设计的,支持你喜爱的工具,包括 Hugging Face Transformers、llama.cpp、Google AI Edge、Ollama、MLX 等,让你能够轻松地为特定的端侧应用进行微调和部署。本文是开发者深度解析:我们将探讨 Gemma 3n 背后的一些创新技术,分享新的基准测试结果,并展示如何从今天开始构建。
Gemma 3n 有哪些新功能?
Gemma 3n 代表了端侧 AI 的重大进步,将强大的多模态能力带到了边缘设备上,其性能以前只在去年的云端前沿模型中才能见到。
-
多模态原生设计: Gemma 3n 原生支持图像、音频、视频和文本输入,以及文本输出。
-
专为端侧优化: 以效率为核心进行工程设计,Gemma 3n 模型提供两种基于有效参数量的规格:E2B 和 E4B。虽然原始参数量分别为 5B 和 8B,但架构创新使其运行时的内存占用可与传统的 2B 和 4B 模型相媲美,最低仅需 2GB(E2B)和 3GB(E4B)内存即可运行。
-
突破性架构: Gemma 3n 的核心包含多项创新组件:MatFormer 架构用于灵活计算、Per Layer Embeddings(PLE)用于内存效率优化、LAuReL 和 AltUp 用于提升架构效率,以及专为端侧用例优化的全新音频编码器和基于 MobileNet-v5 的视觉编码器。
-
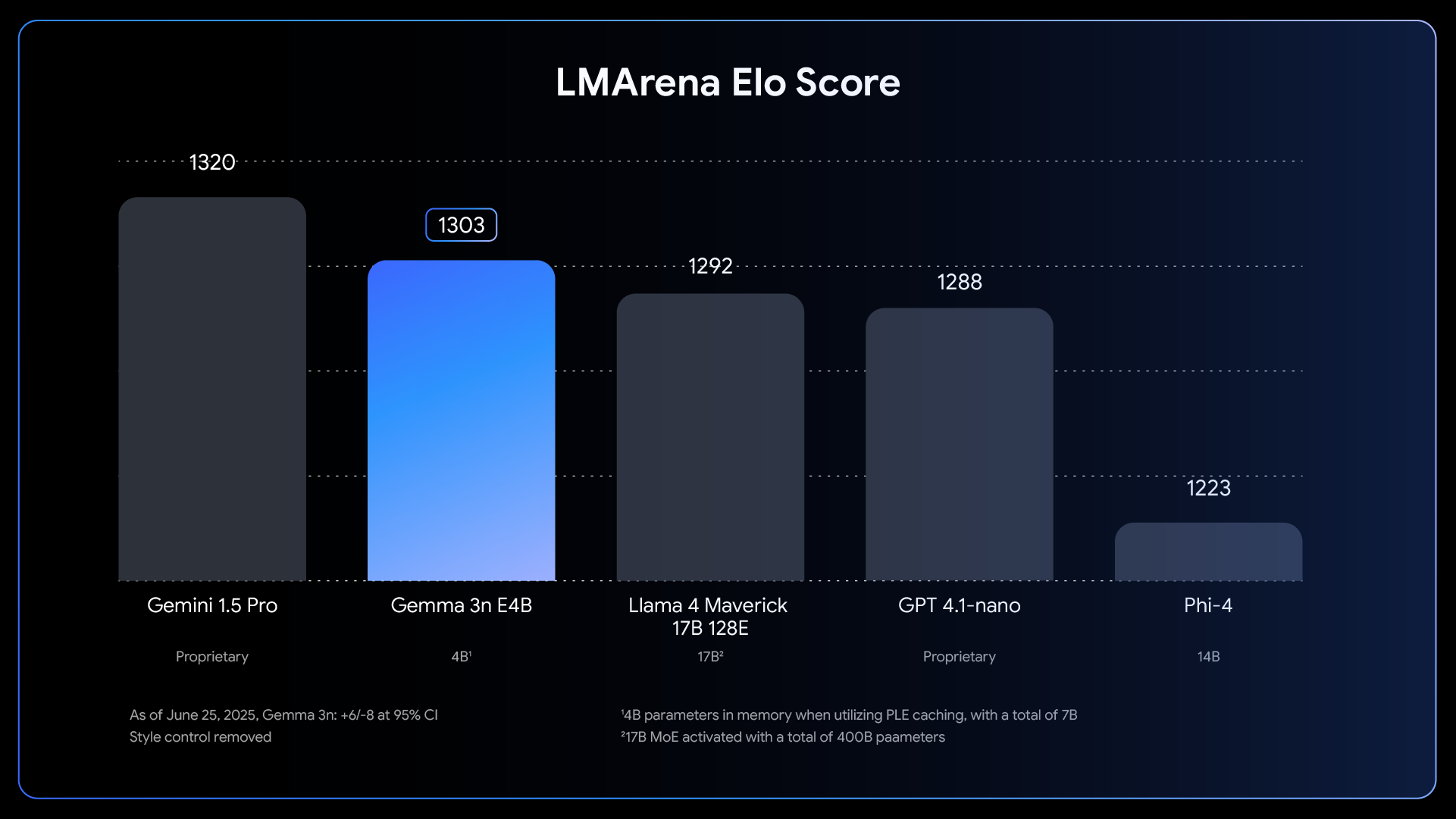
质量全面提升: Gemma 3n 在多语言支持(支持 140 种语言的文本处理和 35 种语言的多模态理解)、数学、编程和推理方面均取得了显著进步。E4B 版本在 LMArena 评分中达到 1300 分以上,成为首个突破此基准的 100 亿参数以下模型。
要实现端侧性能的这一飞跃,需要从根本上重新思考模型架构。Gemma 3n 独特的移动优先架构是其基础,而这一切都从 MatFormer 开始。
MatFormer:一个模型,多种规格
Gemma 3n 的核心是 MatFormer(🪆Matryoshka Transformer)架构,这是一种专为弹性推理而构建的全新嵌套式 Transformer。可以把它想象成俄罗斯套娃:一个大模型内部包含多个完全可用的小模型版本。这种方法将Matryoshka 表征学习的概念从仅适用于嵌入层扩展到了所有 Transformer 组件。

在 4B 有效参数(E4B)模型的 MatFormer 训练过程中,一个 2B 有效参数(E2B)的子模型同时在其中被优化,如上图所示。这为开发者今天提供了两项强大能力和应用场景:
1. 预提取模型: 你可以直接下载并使用完整的 E4B 模型以获得最高能力,或者使用我们已经预先提取好的独立 E2B 子模型,可提供最高 2 倍的推理速度。
2. Mix-n-Match 自定义规格: 如需针对特定硬件约束进行更精细的控制,你可以使用我们称为 Mix-n-Match 的方法,在 E2B 和 E4B 之间创建各种自定义规格的模型。这一技术允许你精确切片 E4B 模型的参数,主要通过调整每层前馈网络的隐藏维度(从 8192 到 16384)并有选择性地跳过某些层来实现。我们正在发布 MatFormer Lab,这是一个展示如何获取这些最优模型的工具,这些模型是通过在 MMLU 等基准上评估各种设置来确定的。
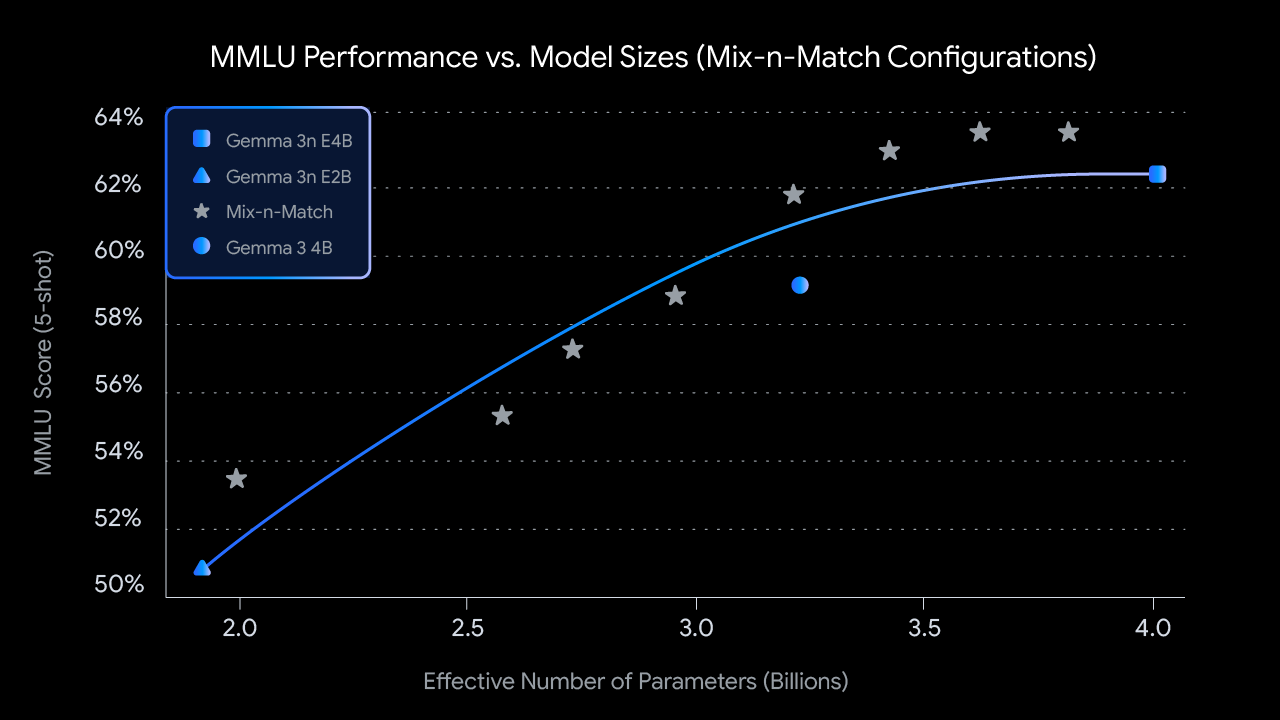
不同模型规格下预训练 Gemma 3n 检查点的 MMLU 评分(使用 Mix-n-Match)
展望未来,MatFormer 架构还为弹性执行铺平了道路。虽然这一能力尚未包含在今天发布的实现中,但它允许单个已部署的 E4B 模型动态地在 E4B 和 E2B 推理路径之间实时切换,从而根据当前任务和设备负载实现性能与内存使用的实时优化。
Per-Layer Embeddings(PLE):释放更强的内存效率
Gemma 3n 模型引入了 Per-Layer Embeddings(PLE)。这项创新专为端侧部署而设计,能够在不增加设备加速器(GPU/TPU)高速内存占用的前提下,显著提升模型质量。
虽然 Gemma 3n E2B 和 E4B 模型的总参数量分别为 5B 和 8B,但 PLE 允许将其中相当一部分参数(与每层相关联的嵌入)高效地在 CPU 上加载和计算。这意味着只有核心 Transformer 权重(E2B 约 2B,E4B 约 4B)需要占用通常更为有限的加速器内存(VRAM)。

借助 Per-Layer Embeddings,你可以在加速器中仅加载约 2B 参数的情况下使用 Gemma 3n E2B。
KV Cache 共享:更快的长上下文处理
处理长输入(例如从音频和视频流中提取的序列)对于许多先进的端侧多模态应用至关重要。Gemma 3n 引入了 KV Cache 共享机制,旨在显著加快流式响应应用的首 token 生成时间(TTFT)。
KV Cache 共享优化了模型处理初始输入的阶段(通常称为”预填充”阶段)。局部注意力和全局注意力中间层的 key 和 value 被直接共享给所有上层,与 Gemma 3 4B 相比,预填充性能提升了显著的 2 倍。这意味着模型可以比以前更快地摄取并理解较长的提示序列。
音频理解:语音转文本与翻译功能介绍
Gemma 3n 使用基于通用语音模型(USM)的先进音频编码器。该编码器每 160 毫秒音频生成一个 token(约每秒 6 个 token),然后作为输入集成到语言模型中,提供对声音上下文的细粒度表示。
这种集成的音频能力为端侧开发解锁了以下关键功能:
-
自动语音识别(ASR): 直接在设备上实现高质量的语音转文字转录。
-
自动语音翻译(AST): 将口语翻译成另一种语言的文字。
我们观察到在英语与西班牙语、法语、意大利语和葡萄牙语之间进行语音翻译时效果尤为出色,为面向这些语言的应用开发者提供了极大的潜力。对于语音翻译等任务,利用思维链提示可以显著提升效果。以下是一个示例:
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>model在发布时,Gemma 3n 编码器的实现支持处理最长 30 秒的音频片段。然而,这并非根本性的限制。底层音频编码器是一个流式编码器,通过额外的长音频训练,能够处理任意长度的音频。后续实现将解锁低延迟的长流式应用场景。
MobileNet-V5:新的最先进视觉编码器
除了集成音频能力外,Gemma 3n 还配备了全新的高效视觉编码器 MobileNet-V5-300M,在边缘设备上的多模态任务中提供了最先进的性能。
MobileNet-V5 专为受约束硬件上的灵活性和强大性能而设计,为开发者提供:
-
多种输入分辨率:原生支持 256x256、512x512 和 768x768 像素分辨率,允许你根据特定应用场景平衡性能与细节。
-
广泛的视觉理解:经过大量多模态数据集的联合训练,擅长各类图像和视频理解任务。
-
高吞吐量:在 Google Pixel 上可达每秒 60 帧,支持实时的端侧视频分析和交互体验。
这一性能水平得益于多项架构创新,包括:
-
MobileNet-V4 基础模块的进一步升级(包括通用倒置瓶颈和 Mobile MQA)。
-
经过大幅扩展的架构,采用混合深度金字塔模型,比最大 MobileNet-V4 变体大 10 倍。
-
新颖的多尺度融合 VLM 适配器,提升 token 质量以获得更好的精度和效率。
得益于新颖的架构设计和先进的蒸馏技术,MobileNet-V5-300M 在基于 SigLip 训练(未使用蒸馏)的 Gemma 3 基线 SoViT 上取得了显著超越。在 Google Pixel Edge TPU 上,量化后速度提升 13 倍(不量化为 6.5 倍),参数减少 46%,内存占用缩小 4 倍,同时在视觉-语言任务上提供显著更高的准确率。
我们很高兴分享这一模型背后的工作。请期待我们即将发布的 MobileNet-V5 技术报告,它将深入探讨模型架构、数据扩展策略和先进蒸馏技术。
与社区携手构建
从第一天起,让 Gemma 3n 易于使用就是我们的优先目标。我们很自豪地与众多出色的开源开发者合作,确保在主流工具和平台上获得广泛支持,包括来自 AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth 和 vLLM 等团队的贡献。
但这个生态系统只是一个开始。这项技术真正的力量在于你将用它构建什么。因此,我们正在发起 Gemma 3n 影响力挑战赛。你的任务:利用 Gemma 3n 独特的端侧、离线和多模态能力,为更美好的世界构建产品。我们设置了 15 万美元的奖金,寻找引人入胜的视频故事和展示现实影响力的”令人惊叹”演示。立即参赛,共同构建更美好的未来。
立即开始使用 Gemma 3n
准备好探索 Gemma 3n 的潜力了吗?以下是入门方式:
-
直接体验: 使用 Google AI Studio 只需点击几下即可试用 Gemma 3n。Gemma 模型也可以直接从 AI Studio 部署到 Cloud Run。
-
下载模型: 在 Hugging Face 和 Kaggle 上找到模型权重。
-
学习与集成: 深入了解我们的综合文档,快速将 Gemma 集成到你的项目中,或从我们的推理和微调指南开始。
-
使用你喜爱的端侧 AI 工具: Google AI Edge Gallery/LiteRT-LLM、Ollama、MLX、llama.cpp、Docker、transformers.js 等。
-
使用你喜欢的开发工具: 利用你偏好的工具和框架,包括 Hugging Face Transformers 和 TRL、NVIDIA NeMo Framework、Unsloth 和 LMStudio。
-
按需部署: Gemma 3n 提供多种部署选项,包括 Google GenAI API、Vertex AI、SGLang、vLLM 和 NVIDIA API Catalog。