原文标题:How we build evals for Deep Agents
原文链接:https://blog.langchain.com/how-we-build-evals-for-deep-agents/
我们如何为 Deep Agents 构建评估
8 分钟阅读 | 2026 年 3 月 26 日
💡 要点
最好的 agent 评估直接衡量我们关心的 agent 行为。以下是我们如何获取数据、创建指标,以及如何随时间推移运行范围明确、有针对性的实验,使 agent 更准确、更可靠。

评估塑造 agent 行为
我们的团队一直在整理评估体系,用于衡量和改进 Deep Agents——一个开源、模型无关的 agent harness,驱动着 Fleet 和 Open SWE 等产品。
每个评估都是一个改变你的 agentic 系统行为的向量。例如,如果一个关于高效文件读取的评估失败了,你很可能会调整系统 prompt 或
read_file工具描述来引导行为,直到它通过为止。
关键在于添加评估时要深思熟虑,不要盲目添加成百上千的测试。这种做法可能制造出改进的假象,却不能反映生产环境中的行为。
核心原则:更多评估 ≠ 更好的 agent。相反,要构建能反映生产环境期望行为的有针对性的评估。
Deep Agents 的方法
在构建 Deep Agents 时,团队会梳理在生产环境中重要的行为,例如跨多个文件检索内容或准确地按顺序组合多次工具调用。他们的三步方法:
- 确定 agent 应遵循哪些行为,然后研究并整理能以可验证方式衡量这些行为的有针对性的评估
- 为每个评估添加 docstring,解释它如何衡量 agent 能力以实现自文档化;用
tool_use等类别标签标记每个评估,以支持分组运行 - 审查输出 trace 以理解失败模式,并更新评估覆盖范围
因为我们将每次评估运行都 trace 到一个共享的 LangSmith 项目中,团队中的任何人都可以随时介入分析问题、做出修复,并重新评估给定评估的价值。
我们如何获取评估数据
获取评估数据有几种方式:
- 使用 dogfooding agent 的反馈
- 从外部基准测试(如 Terminal Bench 2.0 或 BFCL)中筛选评估并进行适配
- 为重要行为编写自定义评估和单元测试
Dogfooding agent 与阅读 trace
我们每天都在 dogfood 自己的 agent。每一个错误都会成为编写评估、更新 agent 定义和上下文工程实践的机会。
关于测试的重要说明
我们将 SDK 的单元测试和集成测试(系统 prompt 透传、中断配置、子 agent 路由)与模型能力评估分开。任何模型都能通过这些测试,因此将它们纳入评分不会增加任何信号。
评估数据来源
Trace 提供了关键数据。 使用 Polly 或 Insights 等内置工具,团队可以大规模分析 trace。目标是理解每种失败模式、提出修复方案、重新运行 agent,并追踪进展和回归。
例如,现在大部分 bug 修复 PR 都是通过 Open SWE 驱动的——我们的开源后台编码 agent。
其他评估来自现有基准测试,如用于函数调用的 BFCL,或来自 Terminal Bench 2.0 的 Harbor 沙盒编码任务。还有许多是从零编写的、针对孤立行为的专注测试。
按类别分组评估
建立评估分类法有助于获得 agent 表现的中间视图(不是单一数字,也不是单次运行结果)。
重要提示:按照评估测试的内容来创建分类法,而不是按照它们的来源。
评估类别
| 类别 | 测试内容 |
|---|---|
file_operations | 文件工具(read、write、edit、ls、grep、glob)、并行调用、分页 |
retrieval | 跨文件查找信息、搜索策略、多跳文档综合 |
tool_use | 选择正确的工具、链接多步调用、跨轮次追踪状态 |
memory | 召回预设上下文、提取隐式偏好、持久化持久信息 |
conversation | 对模糊请求提出澄清问题、在多轮对话中保持正确操作 |
summarization | 处理上下文溢出、触发摘要、在压缩后恢复信息 |
unit_tests | SDK 管道——系统 prompt 透传、中断配置、子 agent 路由、skill 路径解析等是否正常工作? |
目前,所有评估都是 agent 在任务上的端到端运行。我们有意鼓励评估结构的多样性。
我们如何定义指标
选择 agent 的模型时,我们从正确性开始。如果一个模型无法可靠地完成我们关心的任务,其他一切都不重要。
衡量正确性
正确性的衡量取决于测试对象:
- 大多数内部评估使用自定义断言,如”agent 是否并行化了工具调用?”
- 外部基准测试(如 BFCL)使用与 ground truth 答案的精确匹配
- 对于语义正确性(例如 agent 是否持久化了正确的记忆),使用 LLM-as-a-judge
效率指标
一旦多个模型都达到了正确性门槛,我们就转向效率。两个解决同一任务的模型在实践中可能表现截然不同。一个可能需要更多轮次、进行不必要的工具调用,或者因为模型规模更大而执行得更慢。
完整指标表
| 指标 | 定义 |
|---|---|
| 正确性(Correctness) | 模型是否正确完成了任务 |
| 步骤比率(Step ratio) | 观测到的 agent 步骤数 / 理想 agent 步骤数 |
| 工具调用比率(Tool call ratio) | 观测到的工具调用数 / 理想工具调用数 |
| 延迟比率(Latency ratio) | 观测到的延迟 / 理想延迟 |
| 求解率(Solve rate) | 预期步骤数 / 观测到的延迟,如果任务未正确完成则为 0 |
求解率衡量的是 agent 解决任务的速度,按预期步骤数归一化。
模型选择流程
- 首先检查正确性:哪些模型在真正重要的任务上足够准确?
- 然后比较效率:在准确的模型中,哪个在正确性、延迟和成本之间提供了最佳权衡?
通过理想轨迹理解成功与失败
为了使模型比较具有可操作性,我们检查模型是如何成功和失败的。这需要一个具体的参考点,来说明”好的”执行在准确性之外是什么样的。
理想轨迹是指以最少的不必要操作产生正确结果的步骤序列。
示例:“我所在位置的当前时间和天气是什么?”
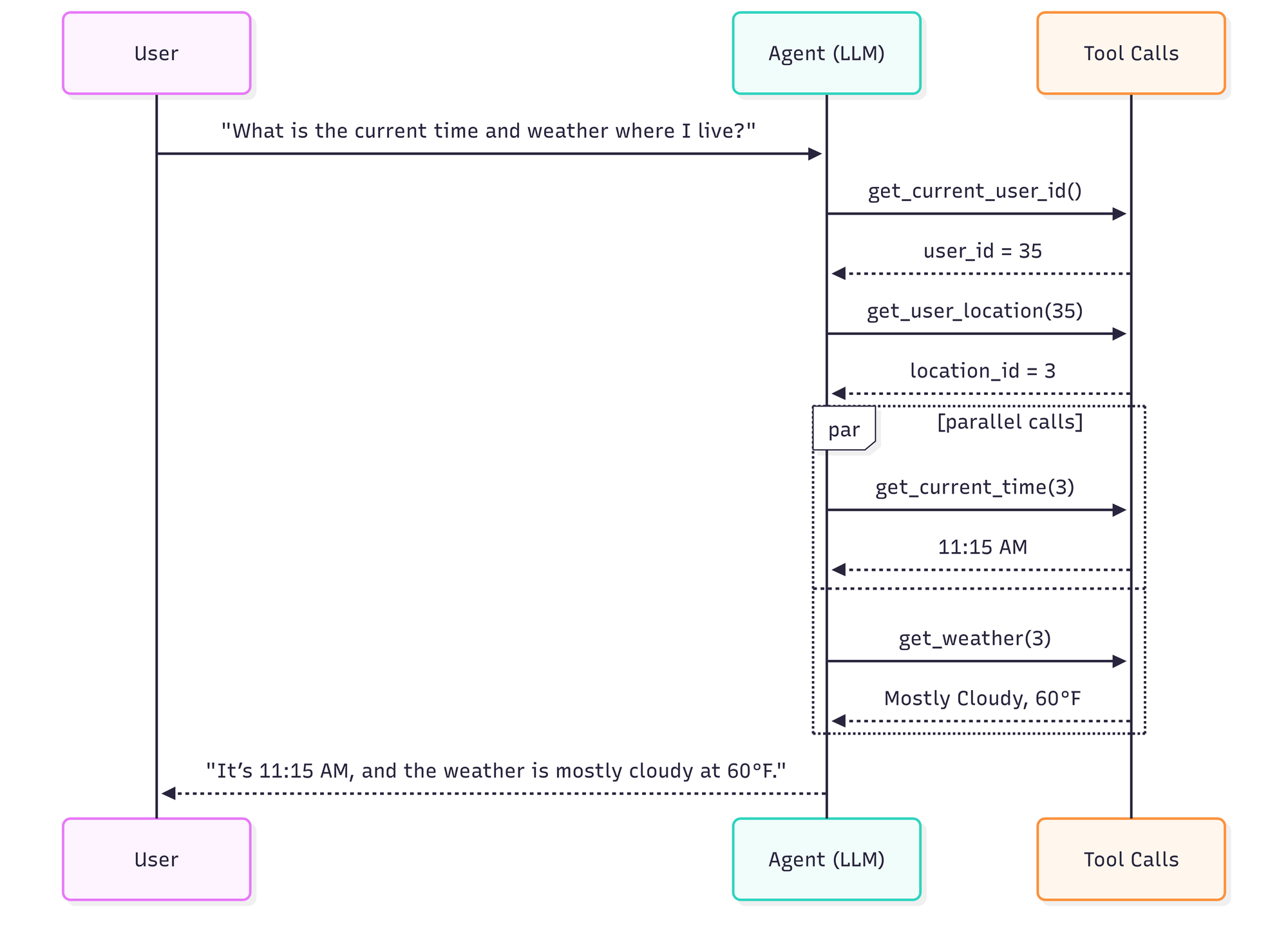
理想轨迹:4 步,4 次工具调用,约 8 秒
- 进行最少必要的工具调用(解析用户 → 解析位置 → 获取时间和天气)
- 在可能的地方并行化独立的工具调用
- 无需不必要的中间轮次即可生成最终答案
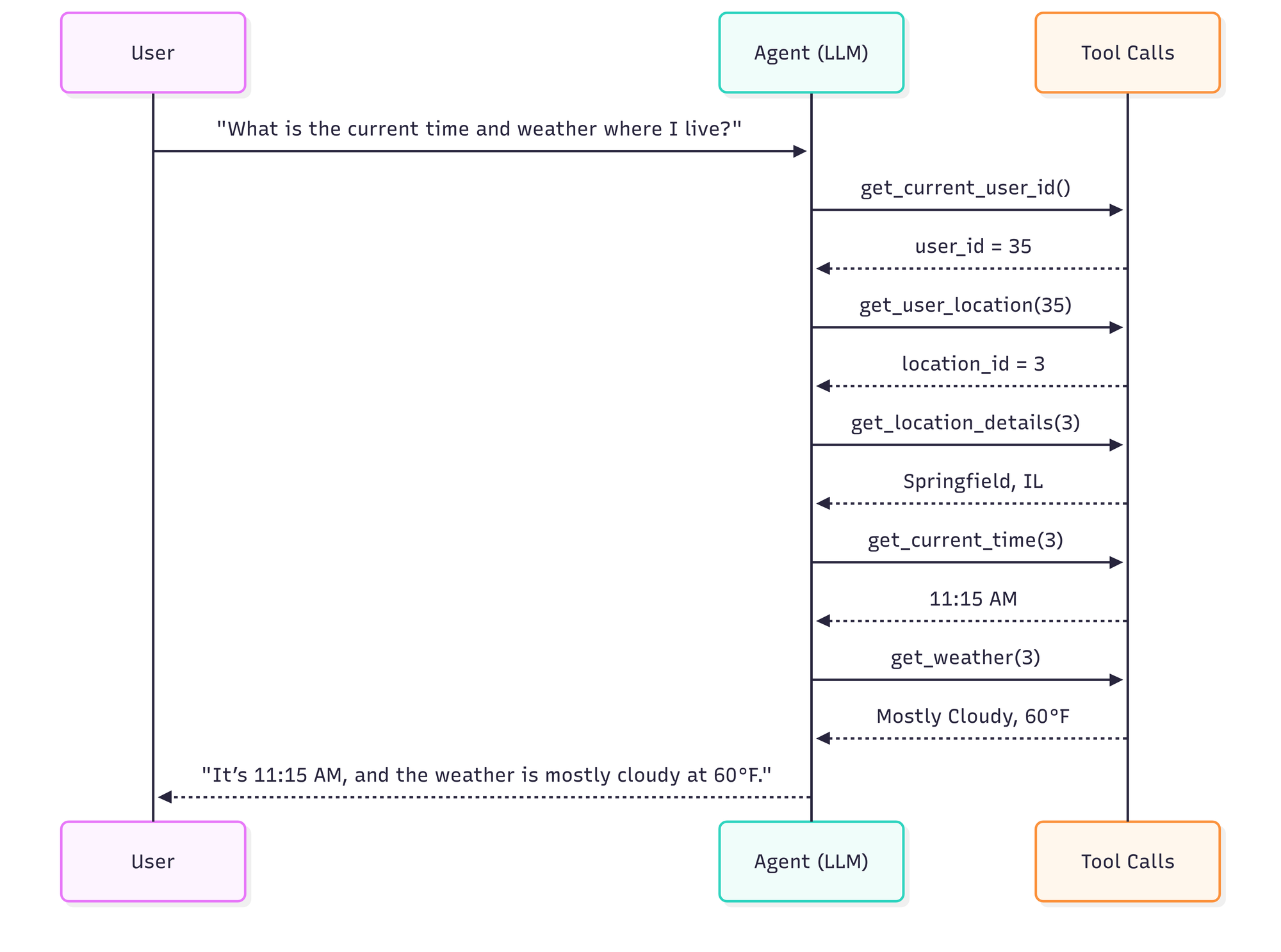
低效但正确的轨迹:6 步,5 次工具调用,约 14 秒
- 包含一次不必要的工具调用
- 没有并行化工具调用
低效运行的指标
| 指标 | 值 | 解释 |
|---|---|---|
| 正确性 | 1 | 运行成功 |
| 步骤比率 | 6 / 4 = 1.5 | 比理想多 50% 的 agent 步骤;越低越好 |
| 工具调用比率 | 5 / 4 = 1.25 | 比理想多 25% 的工具调用;越低越好 |
| 延迟比率 | 14 / 8 = 1.75 | 比理想慢 75%;越低越好 |
| 求解率 | 4 / 14 = 0.29 预期步骤/秒 | 在预期轨迹中的更快进展;越高越好 |
我们如何运行评估
团队使用 pytest 配合 GitHub Actions 在 CI 中以干净、可复现的环境运行评估。每个评估创建一个带有给定模型的 Deep Agent 实例,向其输入一个任务,并计算正确性和效率指标。
评估可以使用标签运行,以节省成本并衡量有针对性的实验:
export LANGSMITH_API_KEY="lsv2_..."
uv run pytest tests/evals --eval-category file_operations --eval-category tool_use --model baseten:nvidia/zai-org/GLM-5我们的评估架构和实现已在 Deep Agents 仓库 中开源。
下一步
团队正在围绕开源 LLM 扩展评估套件。即将推出:
- 开源模型在各评估类别中与闭源前沿模型的对比表现
- 评估作为实时自动改进 agent 任务表现的机制
- 如何随时间维护、精简和扩展每个 agent 的评估
Deep Agents 是完全开源的。试试看并告诉我们你的想法!
引用
- 原文:How we build evals for Deep Agents — LangChain Blog,2026 年 3 月 26 日
- Deep Agents 仓库
- LangSmith 可观测性文档
- Open SWE
- Terminal Bench 2.0
- BFCL 排行榜