原文标题:End-to-end lineage with DVC and Amazon SageMaker AI MLflow apps
原文链接:https://aws.amazon.com/blogs/machine-learning/end-to-end-lineage-with-dvc-and-amazon-sagemaker-ai-mlflow-apps/
作者:Manuwai Korber、Paolo Di Francesco、Nick McCarthy 和 Sandeep Raveesh-Babu,发布于 2026 年 4 月 21 日,收录于 Amazon SageMaker AI、技术操作指南
生产环境中的机器学习(ML)团队往往难以追踪一个模型的完整血缘:训练该模型所用的数据和代码、它所消费的确切数据集版本,以及证明其部署合理性的实验指标。缺乏这种可追溯性,诸如”当前生产中的模型是用哪些数据训练的?“或”我们能否复现六个月前部署的模型?“这类问题,往往需要花费数天时间在散落的日志、笔记本和 Amazon Simple Storage Service(Amazon S3)存储桶中搜寻答案。这一差距在受监管行业中尤为突出,例如医疗健康、金融服务、自动驾驶汽车等领域,审计要求必须将已部署的模型与其精确的训练数据相关联,而且个别记录可能需要根据请求从未来的训练中被排除。
在本文中,我们将展示如何结合三种工具来弥补这一差距:
- DVC(数据版本控制)——用于对数据集进行版本控制并将其与 Git 提交关联
- Amazon SageMaker AI——用于可扩展的处理、训练和部署
- Amazon SageMaker AI MLflow Apps——用于实验追踪、模型注册表和血缘管理
我们将介绍两种可部署的模式——数据集级别血缘追踪和记录级别血缘追踪,您可以使用配套笔记本在自己的 AWS 账户中端到端地运行这两种模式。
解决方案概述
该架构将 DVC、SageMaker AI 和 SageMaker AI MLflow App 整合到一个统一的工作流中,使每个模型都能追溯到其确切的训练数据。
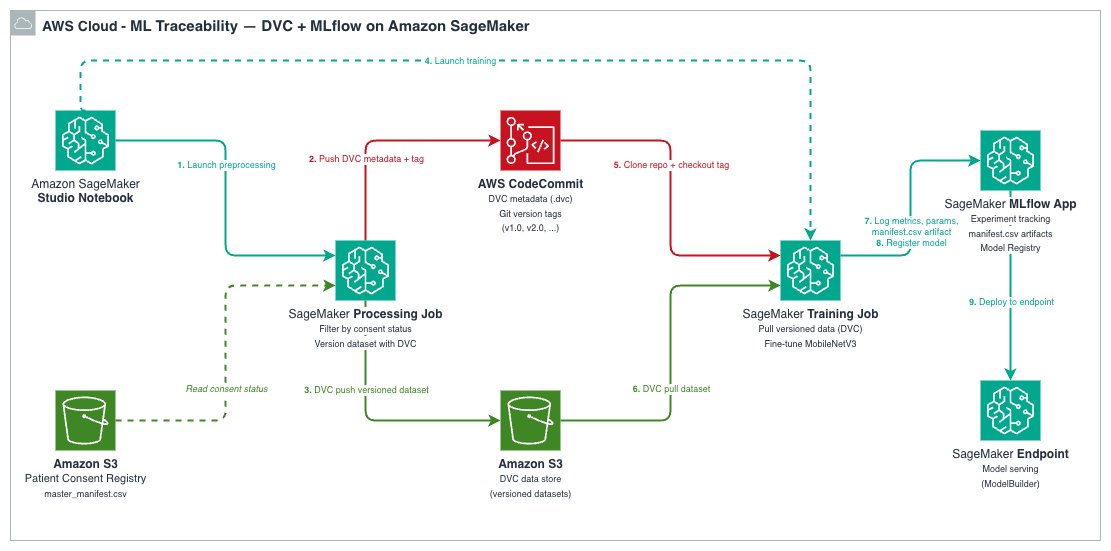
各工具承担不同的职责:
| 工具 | 职责 | 存储内容 |
|---|---|---|
| DVC | 数据和制品版本控制 | Git 中的轻量级 .dvc 元文件;实际数据存储在 Amazon S3 |
| Amazon SageMaker AI | 用于处理、训练和托管的可扩展计算 | 处理/训练作业编排和模型托管 |
| Amazon SageMaker AI MLflow App | 实验追踪、模型注册表、血缘管理 | 参数、指标、制品、已注册模型 |
数据流经四个阶段:
- SageMaker AI 处理作业对原始数据进行预处理,并使用 DVC 对处理后的数据集进行版本控制,将数据推送到 S3,将元数据推送到 Git 仓库。
- SageMaker AI 训练作业在特定 Git 标签处克隆 DVC 仓库,运行
dvc pull以检索确切的版本化数据集,训练模型,并将所有内容记录到 MLflow。 - 每次 MLflow 训练运行都记录
data_git_commit_id,即指向 Amazon S3 中确切数据集的 DVC 提交哈希值。 - 训练完成的模型在 MLflow 模型注册表中注册,并可部署到 SageMaker AI 端点。
这创建了一条完整的可追溯链:生产模型 → MLflow 运行 → DVC 提交 → Amazon S3 中的确切数据集。
先决条件
要跟随本文进行操作,您必须满足以下先决条件:
- 一个 AWS 账户,具有 Amazon SageMaker(处理、训练、MLflow Apps、端点)、Amazon S3、AWS CodeCommit 和 AWS 身份访问管理(IAM)的权限。
- Python 3.11 或 Python 3.12。
- SageMaker Python SDK v3.4.0 或更高版本。
配套仓库包含一个列有所有依赖项的 requirements.txt 文件。如果在 SageMaker Studio 外部运行,您的 IAM 角色必须具有允许 sagemaker.amazonaws.com 代入它的信任关系。
关于 Git 提供商的说明: 笔记本使用 AWS CodeCommit 作为 DVC 元数据的 Git 后端。但 DVC 也可与其他 Git 提供商(GitHub、GitLab、Bitbucket)配合使用。您只需替换
git remote add originURL 并配置适当的凭证即可。例如,通过将令牌存储在 AWS Secrets Manager 中并在运行时获取,或使用 AWS CodeConnections。关键要求是您的 SageMaker AI 执行角色能够访问 Git 仓库,或具有使用 AWS CodeConnections 的权限。
DVC 与 SageMaker AI MLflow 如何协同工作
这一架构背后的核心洞见在于:DVC 和 MLflow 各自解决了血缘问题的一半,两者结合则形成了完整的闭环。
DVC(数据版本控制)是一个免费的开源工具,它扩展了 Git 以处理大型数据集和 ML 制品。Git 本身无法管理大型二进制文件,因为仓库会变得臃肿且缓慢,而 GitHub 等平台会阻止超过 100 MB 的文件。DVC 通过代码化来解决这个问题:它在 Git 中追踪轻量级的 .dvc 元文件(内容寻址指针),而实际数据则存储在 Amazon S3 等远程存储中。这为可达数 GB 或 TB 的数据集提供了类似 Git 的版本控制语义(分支、标记、差异比较),同时不会让仓库变得臃肿。
存储效率:
DVC 使用内容寻址存储(MD5 哈希),因此只存储新增或修改的文件,而不是复制整个数据集。内容相同的文件在 DVC 缓存中只存储一次,即使它们以不同的名称出现或跨不同的数据集版本存在。例如,向现有数据集中添加 1,000 张新图像时,只会将这些新文件上传到 S3。未更改的文件不会重新上传。但是,如果预处理步骤修改了现有文件,受影响的文件将获得新的哈希值并作为新对象存储。
除了数据版本控制之外,DVC 还支持可重现的数据管道、实验管理,并可作为数据注册表在团队之间共享数据集。在本架构中,我们专门使用 DVC 的数据版本控制功能。每次使用 dvc add 对数据集进行版本控制并提交生成的 .dvc 文件时,您都会创建一个映射到特定数据集状态的 Git 提交。为该提交打标签后,您就有了一个稳定的引用,可以通过 git checkout <tag> && dvc pull 随时返回该状态。有关 DVC 版本控制功能的深入介绍,请参阅数据和模型版本控制指南。
SageMaker AI MLflow App 是 AWS 在 SageMaker AI Studio 中提供的一项完全托管服务,用于管理端到端的 ML 和生成式 AI 生命周期。其核心功能包括实验追踪(记录每次训练运行的参数、指标和制品)、带有版本控制和生命周期阶段管理的模型注册表、模型评估以及部署集成。在本文的架构中,我们将 MLflow 用于完整的实验追踪(包括 DVC 结果)和模型注册表。通过在每次训练运行中将 DVC 提交哈希值记录为参数(data_git_commit_id),我们创建了桥梁:MLflow 注册表中的模型可以追溯到确切的 Git 标签,该标签映射到 S3 中的确切数据集。
虽然 DVC 本身可以同时处理数据版本控制和实验追踪,但 MLflow 提供了更成熟的模型注册表,具备模型版本控制、用于生命周期管理的别名以及部署集成。通过使用 DVC 进行数据版本控制、使用 MLflow 进行模型生命周期管理,我们实现了清晰的职责分离:DVC 负责数据到训练的血缘追踪,MLflow 负责训练到部署的血缘追踪,Git 提交哈希值将两者连接在一起。
模式一:数据集级别血缘追踪(基础模式)
在构建集成之前,理解 DVC 的数据集版本控制与 MLflow 的运行追踪如何相互补充以形成完整血缘至关重要。基础笔记本通过模拟一个常见场景来演示核心模式:从有限的标注数据开始,随时间逐步扩展。
工作流程
笔记本使用 CIFAR-10 图像分类数据集运行两个实验:
- v1.0:使用 5% 的数据进行处理和训练(约 2,250 张训练图像)
- v2.0:使用 10% 的数据进行处理和训练(约 4,500 张训练图像)
对于每个版本,执行相同的两步骤管道:
步骤 1 — 处理作业:SageMaker 处理作业下载 CIFAR-10,对配置的比例进行采样,分割为训练/验证/测试集,以 ImageFolder 格式保存图像,并使用 DVC 对结果进行版本控制。处理后的数据集通过 dvc push 推送到 S3,Git 元数据(包括类似 v1.0-02-24-26_1430 的唯一标签)被推送到 CodeCommit。
处理作业通过环境变量接收 DVC 仓库 URL 和 MLflow 追踪 URI:
processor_v1 = FrameworkProcessor(
image_uri=processing_image,
role=role,
instance_type="ml.m5.xlarge",
instance_count=1,
env={
"DVC_REPO_URL": dvc_repo_url,
"DVC_REPO_NAME": dvc_repo_name,
"MLFLOW_TRACKING_URI": mlflow_app_arn,
"MLFLOW_EXPERIMENT_NAME": experiment_name,
"PIPELINE_RUN_ID": pipeline_run_id_v1,
}
)
processor_v1.run(
code="preprocessing_foundational.py",
source_dir="../source_dir",
arguments=[
"--data-fraction", str(data_fraction_v1),
"--data-version", data_version_v1,
"--val-split", "0.1"
],
wait=True
)在处理脚本内部,预处理完成后,数据集使用 DVC 进行版本控制,提交哈希值被记录到 MLflow:
def version_with_dvc(repo_path, version_tag, pipeline_run_id):
"""Add data to DVC and push to remote."""
subprocess.check_call(["dvc", "add", "dataset"], cwd=repo_path)
subprocess.check_call(["git", "add", "dataset.dvc", ".gitignore"], cwd=repo_path)
subprocess.check_call(
["git", "commit", "-m", f"Add dataset version {version_tag}"],
cwd=repo_path
)
subprocess.check_call(["git", "tag", pipeline_run_id], cwd=repo_path)
subprocess.check_call(["dvc", "push"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", "main"], cwd=repo_path)
subprocess.check_call(["git", "push", "origin", pipeline_run_id], cwd=repo_path)
commit_id = subprocess.check_output(
["git", "rev-parse", "HEAD"], cwd=repo_path
).decode().strip()
return commit_id步骤 2 — 训练作业:SageMaker AI 训练作业在步骤 1 的确切标签处克隆 DVC 仓库,运行 dvc pull 下载版本化数据集,并对预训练的 MobileNetV3-Small 模型进行微调。训练脚本将参数(包括 DVC 提交哈希值)、每轮指标和训练好的模型记录到 MLflow。模型自动注册到 MLflow 模型注册表中。
关键的血缘桥梁(将 DVC 提交哈希值记录到 MLflow)在训练脚本中实现:
# Fetch data: clone DVC repo at the exact tag, then dvc pull
data_git_commit_id = fetch_data_from_dvc()
with mlflow.start_run(run_name=run_name) as run:
mlflow.log_params({
"data_version": data_version,
"data_git_commit_id": data_git_commit_id, # <-- the lineage bridge
"dvc_repo_url": dvc_repo_url,
"model_architecture": "mobilenet_v3_small",
"epochs": args.epochs,
"learning_rate": args.learning_rate,
# ...
})在 MLflow 中看到的内容
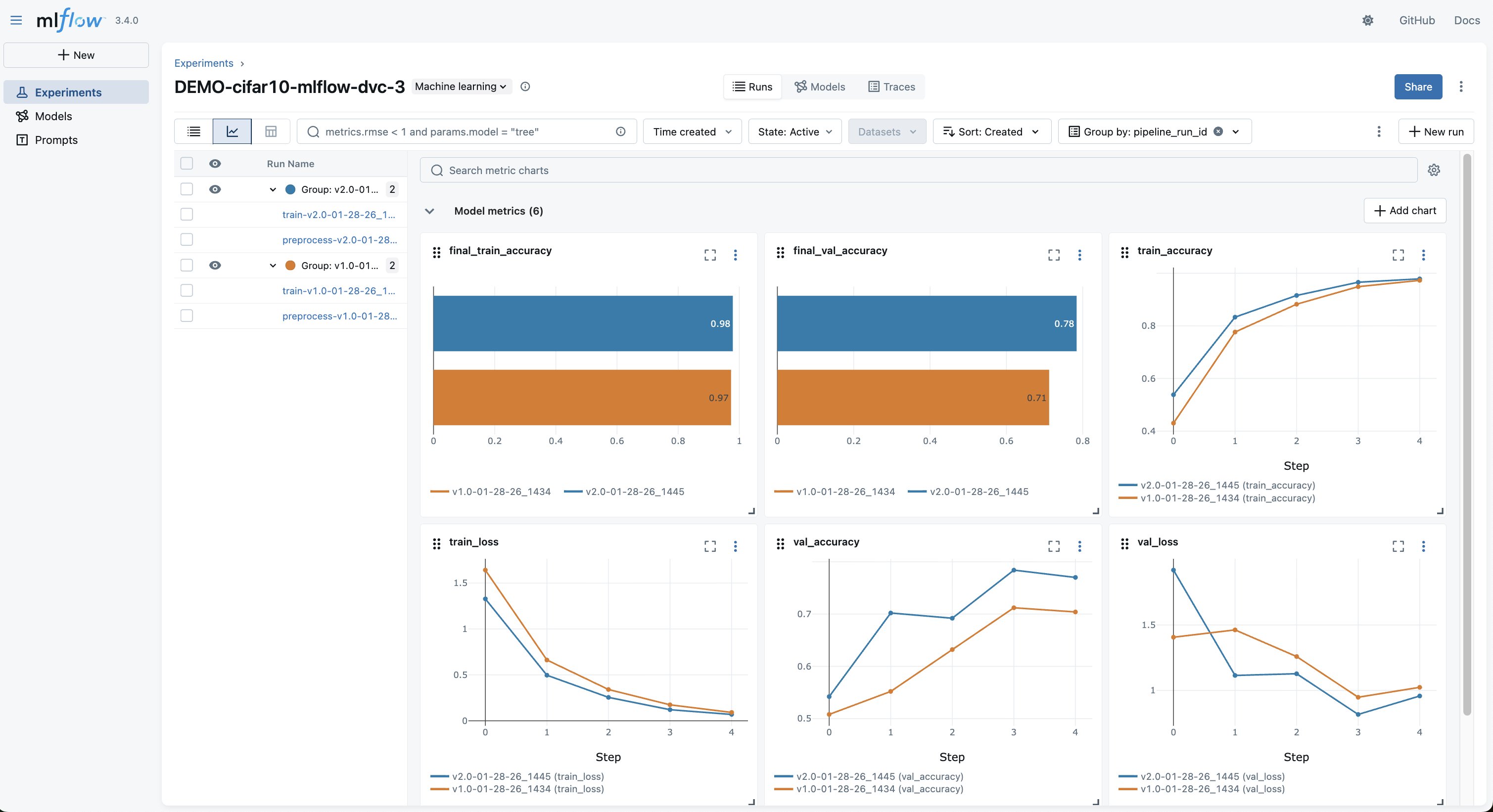
两个实验完成后,MLflow 界面会并排显示两次运行,如下方截图所示。在 MLflow 实验中,您可以比较:
- 不同数据版本的训练和验证准确率曲线
- 每次运行的确切超参数和数据版本
- 将每个模型与其 DVC 数据集关联的
data_git_commit_id
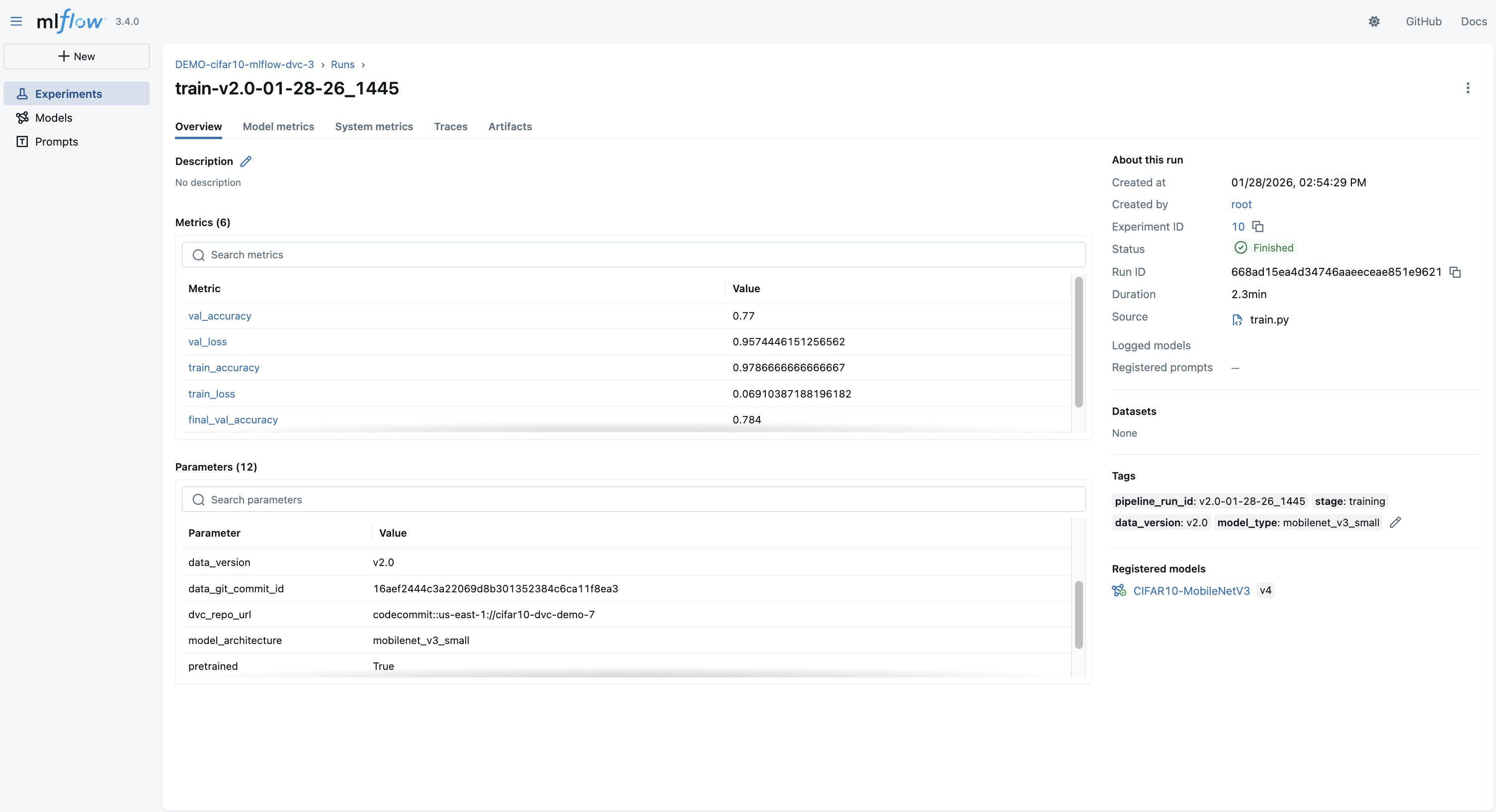
点击某次运行可查看完整详情、损失曲线、参数以及链接到 S3 中确切数据集的 DVC 提交,如下方截图所示。
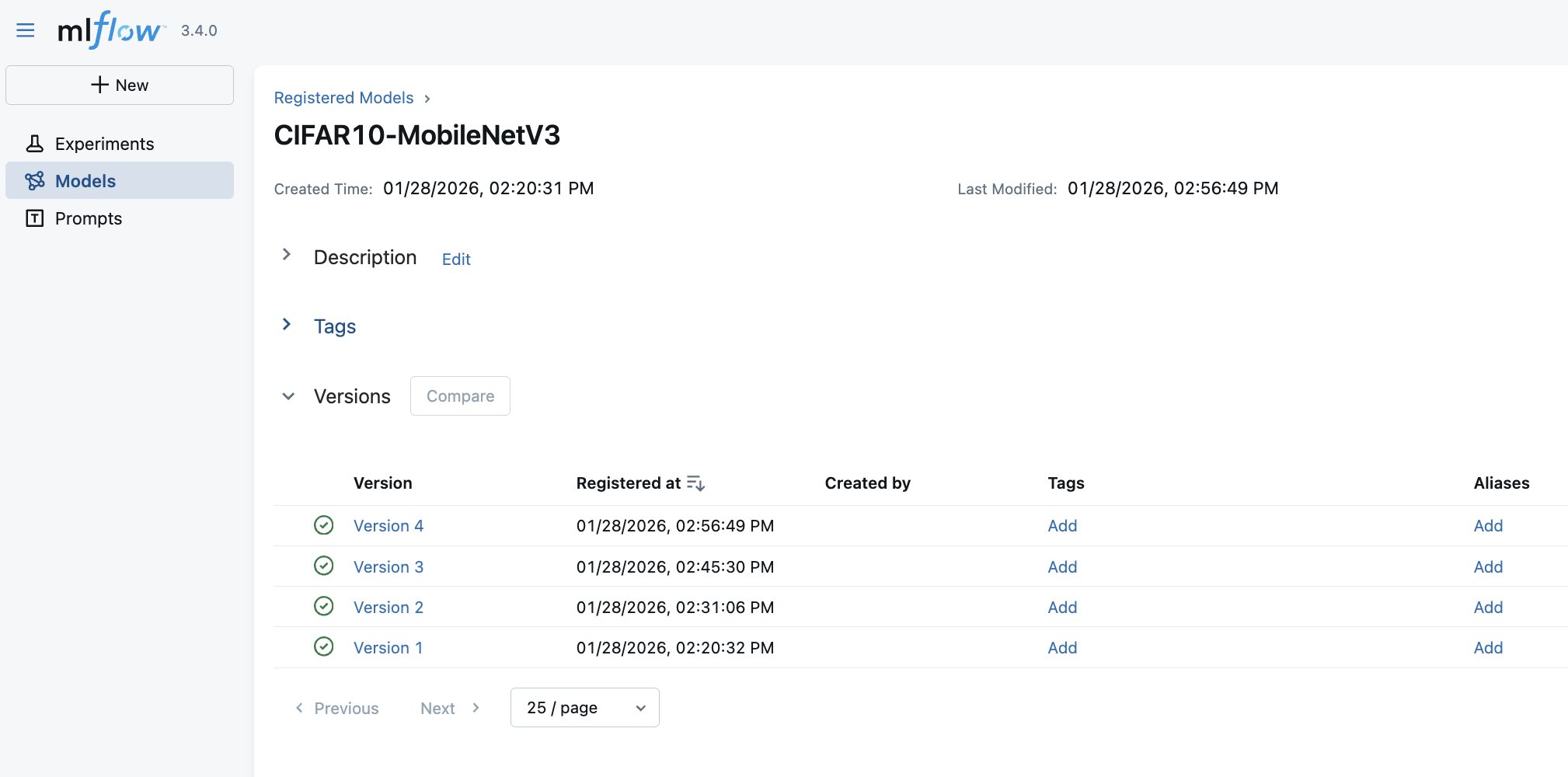
最后,训练完成的人工智能和机器学习(AI/ML)模型会自动注册到 MLflow 模型注册表中,带有版本历史记录和指向生成它们的训练运行的链接,如下方截图所示。此外,随着 SageMaker AI MLflow App 与 SageMaker AI 模型注册表集成,MLflow 会自动将已注册的模型记录到 SageMaker AI 模型注册表中。
部署模型
笔记本使用 ModelBuilder 将推荐模型(v2.0,使用更多数据训练)从 MLflow 模型注册表部署到 SageMaker AI 实时端点。部署后,您可以使用原始图像字节调用端点并获取分类预测结果。完整的部署和推理代码在笔记本中。
此模式能回答的问题
借助数据集级别的血缘追踪,您可以回答:
- “哪个数据集版本训练了这个模型?” — 在 MLflow 运行中查找
data_git_commit_id - “我能重现这个模型的训练数据吗?” — 运行
git checkout <tag> && dvc pull以恢复确切的数据集 - “为什么模型性能发生了变化?” — 在 MLflow 中比较运行并追踪每个运行对应的数据版本
但它无法在无需额外工作的情况下回答:“记录 X 是否在这个模型的训练数据中?” 您需要拉取完整数据集并搜索。这正是模式二发挥作用的地方。
模式二:记录级别血缘追踪(医疗健康合规)
模式二直接建立在数据集级别方法之上,通过清单和同意注册表添加记录/患者级别的可追溯性。医疗健康合规笔记本示例将基础模式扩展到受监管环境,在这些环境中,您需要追踪整个 ML 生命周期中的单个记录,而不仅仅是数据集。
关键新增功能:清单
区别在于清单。清单是一个结构化的 CSV 文件,列出了每个数据集版本中的每个单独记录:
patient_id,scan_id,file_path,split,label
PAT-00001,PAT-00001-SCAN-0001,train/normal/00042.png,train,normal
PAT-00023,PAT-00023-SCAN-0015,train/tubercolosis/00015.png,train,tubercolosis
...此清单保存在 DVC 版本化数据集目录内,并且在每次训练运行时作为 MLflow 制品记录。这使得单个记录无需从 DVC 拉取完整数据集即可直接从 MLflow 中查询。
同意注册表
该工作流由同意注册表驱动——一个列出每位患者及其同意状态的 CSV 文件。在生产环境中,这将是一个具有事务性提交、自身审计跟踪的数据库,并可能有事件驱动的触发器来启动重新训练。此处的 CSV 方法为演示目的而简化,但集成模式是相同的:处理作业读取注册表,只包含具有活跃同意的记录。
处理代码是幂等的。它不了解也不关心退出同意(opt-out),只过滤 consent_status == "active" 的记录并处理剩余部分。退出同意是一种输入变更,当同一管道再次运行时会产生一个新的、干净的数据集。
退出同意工作流
笔记本演示了完整的退出同意周期:
- v1.0 — 基线 — 使用所有已同意患者进行处理和训练。清单列出患者扫描记录。模型以清单作为制品注册到 MLflow 中。
- 退出同意事件 — 患者
PAT-00023请求退出同意。其同意状态在注册表中更新为revoked,更新后的注册表上传到 S3。 - v2.0 — 干净数据集 — 相同的处理作业使用更新后的注册表运行。
PAT-00023的图像被自动排除。DVC 对新数据集(137 位患者)进行版本控制。模型重新训练并作为新版本注册到 MLflow 中。 - 审计验证 — 查询 MLflow 以确认
PAT-00023仅出现在 v1.0 模型中,并且在退出同意日期之后训练的模型中不存在。
审计查询
配套的 utils/audit_queries.py 模块提供了三个查询函数,这些函数通过从 MLflow 下载清单制品来工作:
find_models_with_patient("PAT-00023")— 搜索包含患者 ID 的训练运行。仅返回 v1.0 运行。verify_patient_excluded_after_date("PAT-00023", "2025-06-01")— 检查在某日期后训练的模型,并确认患者不存在。返回 PASSED 或 FAILED 及详细信息。get_patients_in_model(run_id)— 列出特定模型训练数据中的患者 ID。
from utils.audit_queries import find_models_with_patient
# "Which models were trained on this patient's data?"
find_models_with_patient("PAT-00023", experiment_name="demo-cxr-mlflow-dvc")这些查询不需要 DVC checkout——它们完全在 MLflow 制品上运行,速度足够快,可用于交互式审计响应。
生产环境注意事项: 上述查询从每次训练运行中下载 manifest.csv 制品并进行扫描。这适用于少量运行,但无法扩展。在生产环境中,请考虑在训练时将(record_id、run_id、data_version)元组写入 Amazon DynamoDB,将 Amazon Athena 指向 S3 中的 MLflow 制品前缀,或使用训练后的 AWS Lambda 来填充索引。
此模式能回答的问题
除了基础模式提供的所有能力之外,记录级别血缘追踪还能回答:
- “哪些模型使用了患者 X 的扫描数据进行训练?” — 跨 MLflow 运行即时查询
- “验证患者 X 在其退出同意日期之后被排除在所有模型之外” — 自动通过/失败审计
- “列出模型 Y 训练数据中的每条记录” — 下载清单制品
虽然此演示使用医疗健康术语,但该模式同样适用于其他需要记录级别可追溯性的领域:金融服务、内容审核(用户提交的内容),或其他受数据删除请求约束的 ML 系统。
最佳实践与治理
三层可追溯性链
集成的工作流在三个层面创建可追溯性:
- Git + DVC 层 — 每个数据集版本都是指向 DVC 提交的 Git 标签。运行
git checkout <tag> && dvc pull即可恢复确切的处理后数据。 - MLflow 层 — 每次训练运行记录
data_git_commit_id,将模型链接到其 DVC 数据版本。记录级别清单(使用时)使单个记录可查询。 - 模型注册表层 — 每个已注册的模型版本都链接到其训练运行,后者又链接到其数据版本。
受监管环境的安全注意事项
DVC 和 MLflow 提供可追溯性和实验追踪,但本身并不具备防篡改能力。对于受监管的部署(HIPAA、FDA 21 CFR Part 11、GDPR),需要在基础设施级别添加控制措施:
- S3 对象锁定(合规模式)——用于 DVC 远程和 MLflow 制品存储,以避免对版本化数据和模型制品进行修改或删除
- AWS CloudTrail — 用于对存储和训练基础设施的访问进行独立的、只可追加的日志记录
- IAM 策略 — 对生产存储桶、MLflow 追踪服务器和 Git 仓库强制执行最小权限访问
- 静态加密 — 使用 AWS 密钥管理服务(AWS KMS)对存储 DVC 数据和 MLflow 制品的 S3 存储桶进行加密
加速迭代
在运行重复实验(如 v1.0 → v2.0 流程)时,两个 SageMaker AI 功能有助于简化流程:
- SageMaker 托管热池 — 在作业之间保持训练实例热启动,使连续的训练运行可以重复使用已经配置好的基础设施。在
Compute配置中添加keep_alive_period_in_seconds以启用此功能。请注意,热池仅适用于训练作业,不适用于处理作业。 - SageMaker AI Pipelines — 将处理 → 训练 → 注册工作流编排为单个可重复的管道。Pipelines 自动处理步骤依赖关系、在步骤之间传递制品,并可以以编程方式触发(例如,当患者退出同意且清单更新时)。
清理
为避免持续产生费用,请删除演练过程中创建的资源:SageMaker AI 端点、MLflow App(可选)、AWS CodeCommit 仓库和 S3 数据。笔记本包含带有确切命令的清理单元格。主要成本来源是 SageMaker AI 实时端点,测试完成后请确保及时删除它。
结论
在本文中,我们演示了如何构建端到端的 MLOps 工作流,将 DVC 用于数据版本控制、Amazon SageMaker AI 用于可扩展的训练和编排、SageMaker AI MLflow Apps 用于实验追踪和模型注册表。主要成果:
- 完全可重现性 — 模型可以通过存储在 MLflow 中的 DVC 提交哈希值追溯到其确切的训练数据。
- 记录级别血缘追踪 — 清单模式支持查询哪些单个记录训练了给定模型。这对于退出同意合规和审计响应至关重要。
- 无状态合规对齐 — 同意注册表模式在不更改处理代码的情况下处理记录排除。退出同意是一种通过相同管道流动的输入变更。
- 实验比较 — MLflow 提供在不同数据版本上训练的模型的并排比较,具有完整的参数和指标追踪。
配套 GitHub 仓库中的两个笔记本可以直接部署。基础模式适合需要数据集级别可追溯性的团队。医疗健康合规模式将其扩展到需要记录级别审计跟踪的受监管环境。两者共享相同的 SageMaker AI 训练代码和架构。
虽然笔记本演示了交互式工作流,但相同的模式可以直接集成到自动化管道中。SageMaker AI Pipelines 可以编排处理和训练步骤,DVC 标记和 MLflow 日志记录在每个作业内部完全相同地进行。无论从笔记本还是 SageMaker AI Pipeline 触发,血缘链都保持不变。

Manuwai Korber
Manuwai Korber 是 AWS 的 AI/ML 专业解决方案架构师,具有 ML 工程背景。他帮助客户在完整的模型生命周期中构建生产级 AI/ML 系统——从实验、训练和微调到服务和生产部署。此外,他还负责构建基于 GenAI 的应用程序和智能体 AI 系统。

Paolo Di Francesco
Paolo Di Francesco 是亚马逊云服务(AWS)的高级解决方案架构师。他拥有电信工程博士学位,具有软件工程经验。他对机器学习充满热情,目前专注于利用自身经验帮助客户在 AWS 上实现目标,重点探讨 MLOps 相关话题。业余时间,他喜欢踢足球和阅读。

Sandeep Raveesh
Sandeep Raveesh 是 AWS 的 GenAI 专业解决方案架构师。他陪伴客户走过 AIOps 之旅,涵盖模型训练、检索增强生成(RAG)、GenAI 智能体以及 GenAI 用例的扩展。他还专注于市场推广战略,帮助 AWS 在生成式 AI 领域构建和调整产品以解决行业挑战。您可以在 LinkedIn 上找到 Sandeep。

Nick McCarthy
Nick McCarthy 是 Amazon Bedrock 团队专注于模型定制的高级生成式 AI 专业解决方案架构师。他曾与 AWS 在医疗健康、金融、体育、电信和能源等广泛行业的客户合作,帮助他们通过使用 AI 和机器学习加速业务成果。业余时间,Nick 喜欢旅行、探索新美食以及阅读科技相关书籍。他拥有物理学学士学位和机器学习硕士学位。