原文标题:Cost-efficient custom text-to-SQL using Amazon Nova Micro and Amazon Bedrock on-demand inference
原文链接:https://aws.amazon.com/blogs/machine-learning/cost-efficient-custom-text-to-sql-using-amazon-nova-micro-and-amazon-bedrock-on-demand-inference/
Text-to-SQL 生成在企业 AI 应用中仍然是一个持久性挑战,尤其是在处理自定义 SQL 方言或特定领域的数据库 schema 时。虽然基础模型(FM)在标准 SQL 上表现出色,但要实现生产级别的专用方言准确率,则需要进行微调。然而,微调引入了一个运营权衡:在持久基础设施上托管自定义模型会产生持续成本,即便在零使用量期间也不例外。
结合微调 Amazon Nova Micro 模型的 Amazon Bedrock 按需推理提供了一个替代方案。通过将 LoRA(低秩适配)微调的高效性与无服务器的按 token 计费推理相结合,企业可以实现自定义 Text-to-SQL 能力,而无需持续托管模型所带来的额外开销。尽管应用 LoRA 适配器会产生额外的推理时间开销,但测试表明其延迟适合于交互式 Text-to-SQL 应用,成本随使用量扩展而非按预置容量计费。
本文演示了两种微调 Amazon Nova Micro 以实现自定义 SQL 方言生成的方法,以兼顾成本效益和生产就绪的性能。我们的示例工作负载在每月 2.2 万次查询的样本流量下维持了 0.80 美元的月均成本,与持续托管模型基础设施相比实现了显著的成本节约。
前提条件
要部署这些解决方案,你需要以下条件:
- 一个启用计费的 AWS 账户
- 配置标准 IAM 权限和角色以访问:
- Amazon Bedrock Nova Micro 模型
- Amazon SageMaker AI
- Amazon Bedrock 模型自定义功能
- 针对 Amazon SageMaker AI 训练的 ml.g5.48xl 实例配额
解决方案概述
该解决方案包含以下高层次步骤:
- 准备自定义 SQL 训练数据集,其中包含特定于你组织 SQL 方言和业务需求的输入/输出对。
- 使用准备好的数据集和选定的微调方法,启动 Amazon Nova Micro 模型的微调过程。
- Amazon Bedrock 模型自定义:用于简化部署的托管方式
- Amazon SageMaker AI:用于精细训练自定义和控制
- 将自定义模型部署到 Amazon Bedrock 以使用按需推理,消除基础设施管理负担,只需为 token 使用量付费。
- 使用特定于自定义 SQL 方言和业务用例的测试查询来验证模型性能。
为了在实践中演示这种方法,我们提供了两个完整的实现路径,以满足不同的组织需求。第一种使用 Amazon Bedrock 的托管模型自定义,适合优先考虑简单性和快速部署的团队。第二种使用 Amazon SageMaker AI 训练作业,适合需要对超参数和训练基础设施进行更精细控制的组织。两种实现共享相同的数据准备流程,并部署到 Amazon Bedrock 进行按需推理。以下是每个 GitHub 代码示例的链接:
以下架构图说明了端到端工作流,涵盖数据准备、两种微调方法以及支持无服务器推理的 Bedrock 部署路径。
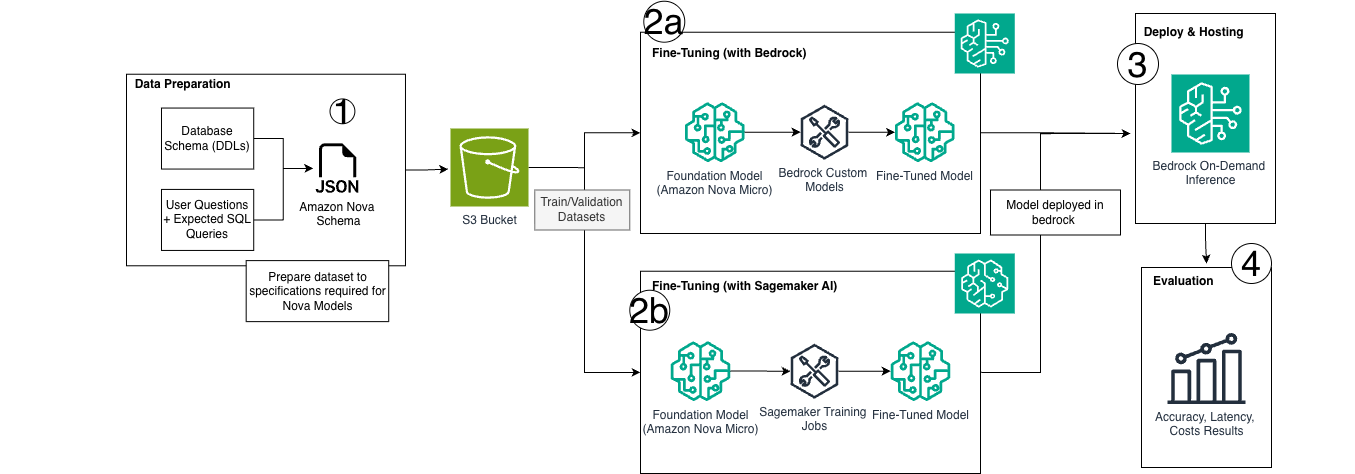
1. 数据集准备
我们的演示使用 sql-create-context 数据集。该数据集是 WikiSQL 和 Spider 数据集的精选组合,包含超过 7.8 万个自然语言问题与 SQL 查询的配对样本,涵盖多样化的数据库 schema。该数据集是 Text-to-SQL 微调的理想基础,因为其查询复杂度涵盖广泛,从简单的 SELECT 语句到带有聚合的复杂多表连接。
数据格式化与结构
训练数据按照文档中规定的格式进行结构化。这包括创建 JSONL 文件,其中包含系统提示指令与用户查询及不同复杂度的对应 SQL 响应配对。格式化后的训练数据集随后被分割为训练集和验证集,存储为 JSONL 文件,并上传到 Amazon Simple Storage Service(Amazon S3)以供微调使用。
示例转换记录
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are a powerful text-to-SQL model. Your job is to answer questions about a database. You can use the following table schema for context: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Return the SQL query that answers the following question: How many heads of the departments are older than 56 ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}Amazon Bedrock 微调方法
Amazon Bedrock 的模型自定义功能提供了一种简化的、完全托管的方式来微调 Amazon Nova 模型,无需配置或管理训练基础设施。这种方法非常适合寻求快速迭代和最低运营开销同时实现定制模型性能的团队,满足其 Text-to-SQL 使用场景的需求。
使用 Amazon Bedrock 的自定义能力,训练数据上传到 Amazon S3,微调作业通过 AWS 控制台或 API 进行配置,AWS 负责处理底层训练基础设施。生成的自定义模型可以使用按需推理进行部署,维持与基础 Nova Micro 模型相同的 token 计费定价,且无额外加价,使其成为变化工作负载的经济高效解决方案。当你需要快速为自定义 SQL 方言定制模型而不想管理 ML 基础设施时,或者希望最小化运营复杂性,或者需要具有自动扩展功能的无服务器推理时,这种方法非常适合。
2a. 使用 Amazon Bedrock 创建微调作业
Amazon Bedrock 支持通过 AWS 控制台和 AWS SDK for Python(Boto3)进行微调。AWS 文档包含了使用两种方法提交训练作业的通用指导。在我们的实现中,我们使用了 AWS SDK for Python(Boto3)。请参考我们 GitHub 示例仓库中的示例笔记本,查看我们的分步实现。
配置超参数
选择要微调的模型后,我们配置适合我们用例的超参数。对于在 Amazon Bedrock 上进行 Amazon Nova Micro 微调,可以自定义以下超参数来优化我们的 Text-to-SQL 模型:
| 参数 | 范围/约束 | 用途 | 我们使用的值 |
|---|---|---|---|
| 训练轮数(Epochs) | 1–5 | 完整遍历训练数据集的次数 | 5 轮 |
| 批次大小(Batch Size) | 固定为 1 | 更新模型权重前处理的样本数量 | 1(Nova Micro 固定值) |
| 学习率(Learning Rate) | 0.000001–0.0001 | 梯度下降优化的步长 | 0.00001(稳定收敛) |
| 学习率预热步数(Learning Rate Warmup Steps) | 0–100 | 逐步增加学习率的步数 | 10 |
注意:这些超参数针对我们的特定数据集和使用场景进行了优化。最优值可能因数据集大小和复杂度而异。在示例数据集中,此配置在模型准确率和训练时间之间提供了较好的平衡,训练大约需要 2-3 小时完成。
分析训练指标
Amazon Bedrock 会自动生成训练和验证指标,并存储在你指定的 S3 输出位置。这些指标包括:
- 训练损失: 衡量模型对训练数据的拟合程度
- 验证损失: 表示在未见数据上的泛化性能
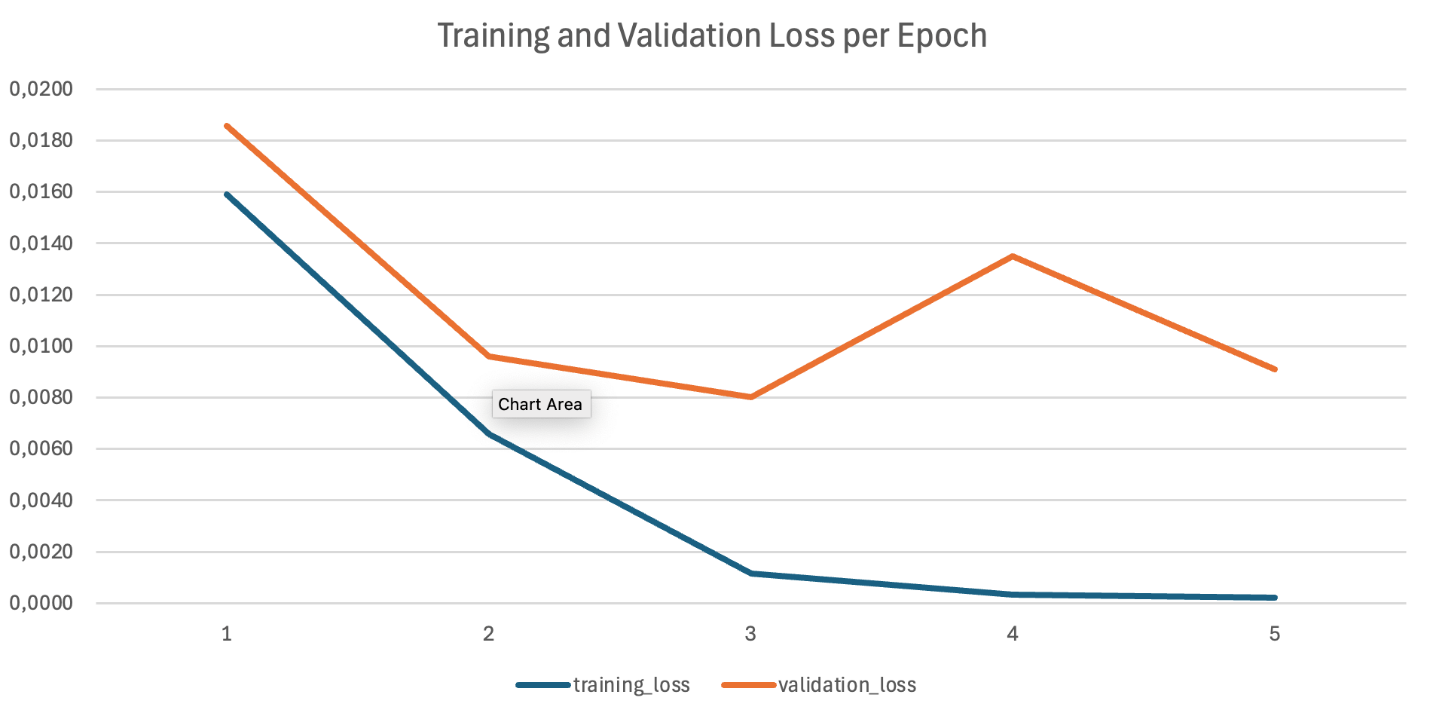
训练和验证损失曲线显示训练成功:两者持续下降,遵循相似的模式,并收敛到相近的最终值。
3a. 使用按需推理部署
微调作业成功完成后,你可以使用按需推理部署自定义的 Nova Micro 模型。这种部署选项提供自动扩展和按 token 计费,非常适合无需预置专用计算资源的变化工作负载。
调用自定义 Nova Micro 模型
部署后,你可以使用部署 ARN 作为模型 ID,通过 Amazon Bedrock Converse API 调用自定义的 Text-to-SQL 模型。
# Use the deployment ARN as the model ID
deployment_arn = "arn:aws:bedrock:us-east-1:<account-id>:deployment/<deployment-id>"
# Prepare the inference request
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """Database schema:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
Question: What are the top 5 products by revenue in the Electronics category?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # Low temperature for deterministic SQL generation
"topP": 0.9
}
)
# Extract the generated SQL query
sql_query = response['output']['message']['content']['text']
print(f"Generated SQL:
{sql_query}")Amazon SageMaker AI 微调方法
虽然 Amazon Bedrock 方法通过托管训练体验简化了模型自定义,但寻求更深度优化控制的组织可能会从 SageMaker AI 方法中受益。SageMaker AI 提供了对训练参数的广泛控制,这些参数可以显著影响效率和模型性能。你可以调整批次大小以优化速度和内存,精细调节各层的dropout 设置以防止过拟合,并配置学习率调度以实现训练稳定性。对于 LoRA 微调,你可以使用 SageMaker AI 自定义缩放因子和正则化参数,针对多模态与纯文本数据集使用不同的优化设置。此外,你还可以调整 Context Window 大小和优化器设置以匹配特定用例需求。请参阅以下笔记本获取完整代码示例。
1b. 数据准备与上传
SageMaker AI 微调方法的数据准备和上传过程与 Amazon Bedrock 实现完全相同。两种方法都将 SQL 数据集转换为 bedrock-conversation-2024 schema 格式,将数据分割为训练集和测试集,并将 JSONL 文件直接上传到 S3。
# S3 prefix for training data
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
# Upload datasets to S3
train_s3_path = sess.upload_data(
path='data/train_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path='data/test_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'Training data uploaded to: {train_s3_path}')
print(f'Test data uploaded to: {test_s3_path}')2b. 使用 Amazon SageMaker AI 创建微调作业
选择模型 ID、训练配方和镜像 URI:
# Nova configuration
model_id = "nova-micro/prod"
recipe = "https://raw.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/main/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
# Nova-specific image URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Model ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'Instance type: {instance_type}')
print(f'Instance count: {instance_count}')
print(f'Image URI: {image_uri}')配置自定义训练配方
使用 Amazon SageMaker AI 进行 Nova 模型微调的一个关键差异在于自定义训练配方的能力。配方是 AWS 提供的预配置训练栈,帮助你快速启动训练和微调。在保持与 Amazon Bedrock 标准超参数集(训练轮数、批次大小、学习率和预热步数)兼容的同时,这些配方通过以下方式扩展了超参数选项:
- 正则化参数: hidden_dropout、attention_dropout 和 ffn_dropout,用于防止过拟合。
- 优化器设置: 可自定义的 beta 系数和权重衰减设置。
- 架构控制: LoRA 训练的适配器秩和缩放因子。
- 高级调度: 自定义学习率调度和预热策略。
推荐的方法是从默认设置开始创建基线,然后根据你的特定需求进行优化。以下是可供优化的一些额外参数列表:
| 参数 | 范围/约束 | 用途 |
|---|---|---|
max_length | 1024–8192 | 控制输入序列的最大 Context Window 大小 |
global_batch_size | 16,32,64 | 更新模型权重前处理的样本数量 |
hidden_dropout | 0.0–1.0 | 隐藏层状态的正则化,防止过拟合 |
attention_dropout | 0.0–1.0 | 注意力机制权重的正则化 |
ffn_dropout | 0.0–1.0 | 前馈网络层的正则化 |
weight_decay | 0.0–1.0 | 模型权重的 L2 正则化强度 |
Adapter_dropout | 0.0–1.0 | LoRA 适配器参数的正则化 |
我们使用的完整配方可以在这里找到。
创建并执行 SageMaker AI 训练作业
配置好模型和配方后,初始化 ModelTrainer 对象并开始训练:
from sagemaker.train import ModelTrainer
trainer = ModelTrainer.from_recipe(
training_recipe=recipe,
recipe_overrides=recipe_overrides,
compute=compute_config,
stopping_condition=stopping_condition,
output_data_config=output_config,
role=role,
base_job_name=job_name,
sagemaker_session=sess,
training_image=image_uri
)
# Configure data channels
from sagemaker.train.configs import InputData, S3DataSource
train_input = InputData(
channel_name="train",
data_source=S3DataSource(
s3_uri=train_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
val_input = InputData(
channel_name="val",
data_source=S3DataSource(
s3_uri=test_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
# Begin training
training_job = trainer.train(
input_data_config=[train_input,val_input],
wait=False
)训练完成后,我们通过 create_custom_model_deployment Amazon Bedrock API 将模型注册到 Amazon Bedrock,使用已部署模型的 ARN、系统提示和用户消息,通过 converse API 实现按需推理。
在我们的 SageMaker AI 训练作业中,我们使用了默认配方参数,包括 2 轮训练和批次大小 64,我们的数据包含 2 万行,因此完整的训练作业持续了 4 小时。使用 ml.g5.48xlarge 实例,微调 Nova Micro 模型的总成本为 65 美元。
4. 测试与评估
为了评估我们的模型,我们进行了运营测试和准确率测试。为了评估准确率,我们实现了 LLM-as-a-Judge 方法,收集微调模型的问题和 SQL 响应,并使用评判模型将其与真实答案进行评分比较。
def get_score(system, user, assistant, generated):
formatted_prompt = (
"You are a data science teacher that is introducing students to SQL. "
f"Consider the following question and schema:"
f"<question>{user}</question>"
f"<schema>{system}</schema>"
"Here is the correct answer:"
f"<correct_answer>{assistant}</correct_answer>"
f"Here is the student's answer:"
f"<student_answer>{generated}</student_answer>"
"Please provide a numeric score from 0 to 100 on how well the student's "
"answer matches the correct answer. Put the score in <SCORE> XML tags."
)
_, result = ask_claude(formatted_prompt)
pattern = r'<SCORE>(.*?)</SCORE>'
match = re.search(pattern, result)
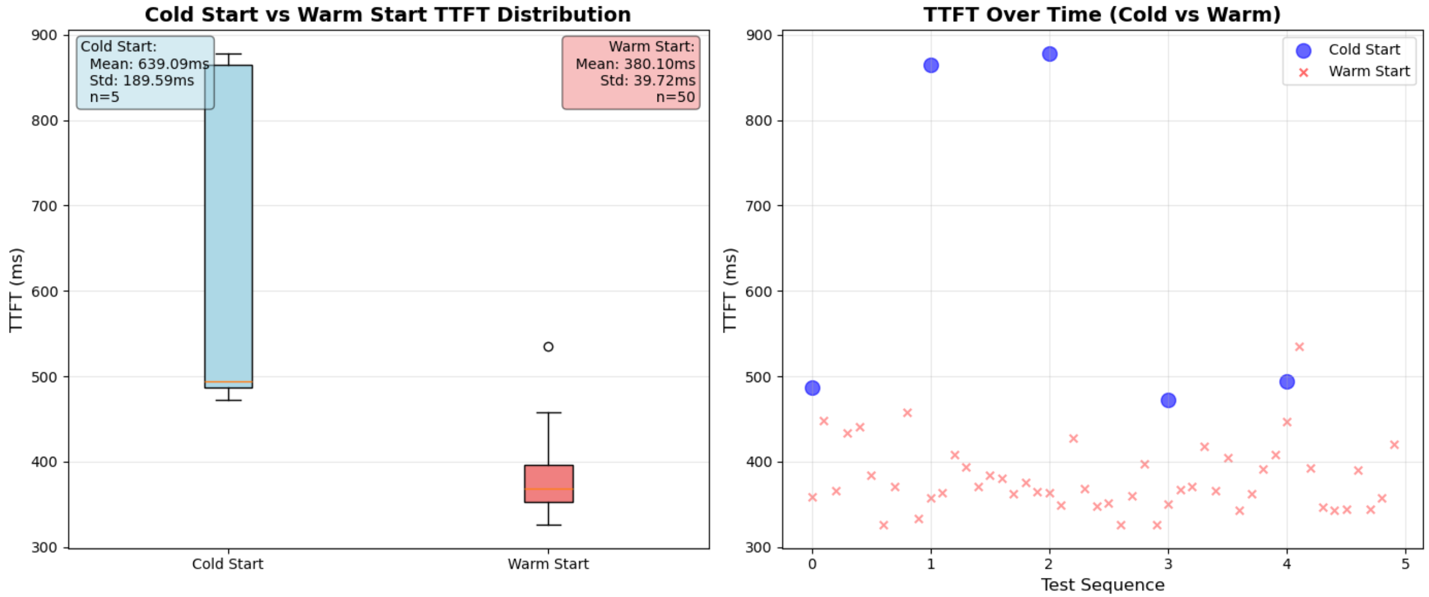
return match.group(1) if match else "0"对于运营测试,我们收集了包括 TTFT(首 token 生成时间)和 OTPS(每秒输出 token 数)在内的指标。与基础 Nova Micro 模型相比,我们观察到冷启动的首 token 生成时间在 5 次运行中平均为 639 毫秒(增加 34%)。这种延迟增加源于在推理时应用 LoRA 适配器,而非将其烘入模型权重。然而,这一架构选择带来了显著的成本优势,因为微调后的 Nova Micro 模型与基础模型收费相同,实现了按需计费和按使用量付费的灵活性,无需最低承诺。在正常运行期间,我们的首 token 生成时间在 50 次调用中平均为 380 毫秒(增加 7%)。端到端延迟合计约 477 毫秒用于完整响应生成。Token 生成速率约为每秒 183 个 token,仅比基础模型降低 27%,同时仍然非常适合交互式应用。
成本摘要
一次性成本:
-
Amazon Bedrock 模型训练成本: 每 1000 个 token 0.001 美元 × 训练轮数
- 对于 2000 个示例、5 轮训练,每个约 800 个 token = 8.00 美元
-
SageMaker AI 模型训练成本: 我们使用了 ml.g5.48xlarge 实例,费用为 16.288 美元/小时
- 使用 2 万行数据集训练持续 4 小时 = 65.15 美元
持续成本:
- 存储: 每个自定义模型每月 1.95 美元
- 按需推理: 与基础 Nova Micro 相同的 token 计费定价
- 输入 token:每 1000 个 token 0.000035 美元(Amazon Nova Micro)
- 输出 token:每 1000 个 token 0.00014 美元(Amazon Nova Micro)
生产工作负载的示例计算:
每月 2.2 万次查询(100 个用户 × 每天 10 次查询 × 22 个工作日):
- 每次查询平均 800 个输入 token + 60 个输出 token
- 输入成本:(22,000 × 800 / 1,000) × 0.000035 = 0.616 美元
- 输出成本:(22,000 × 60 / 1,000) × 0.00014 = 0.184 美元
- 月度总推理成本:0.80 美元
这一分析验证了对于自定义方言的 Text-to-SQL 使用场景,在 Amazon Bedrock 上使用 PEFT LoRA 微调 Nova 模型比在持久基础设施上自托管自定义模型更具成本效益。自托管方式可能适合需要对基础设施、安全配置或集成需求进行最大控制的使用场景,但 Amazon Bedrock 按需成本模式为大多数生产 Text-to-SQL 工作负载提供了显著的成本节约。
结论
这些实现选项展示了如何根据组织需求和技术要求定制 Amazon Nova 微调方案。我们探索了两种满足不同受众和使用场景的不同方法。无论你选择 Amazon Bedrock 的托管简单性还是通过 SageMaker AI 训练获得更多控制,无服务器部署模型和按需计费意味着你只需为实际使用量付费,同时无需进行基础设施管理。
Amazon Bedrock 模型自定义方法提供了一种简化的托管解决方案,消除了基础设施复杂性。数据科学家可以专注于数据准备和模型评估,而无需管理训练基础设施,使其非常适合快速实验和开发。
SageMaker AI 训练方法提供了对微调过程每个方面的更多控制。机器学习(ML)工程师可以精细控制训练参数、基础设施选择以及与现有 MLOps 工作流的集成,从而能够根据所需性能、成本和运营要求进行优化。例如,你可以调整批次大小和实例类型来优化训练速度,或修改学习率和 LoRA 参数,根据特定运营需求在模型质量和训练时间之间取得平衡。
在以下情况下选择 Amazon Bedrock 模型自定义: 你需要快速迭代、ML 基础设施专业知识有限,或者希望在实现自定义模型性能的同时最小化运营开销。
在以下情况下选择 SageMaker AI 训练: 你需要细粒度的参数控制、有特定基础设施或合规要求、需要与现有 MLOps 管道集成,或者希望优化训练过程的每个方面。
开始使用
准备好构建你自己的经济高效的 Text-to-SQL 解决方案了吗?访问我们的完整实现:
- Bedrock 微调笔记本:托管、简化的方法
- SageMaker AI 微调笔记本:高级自定义和控制
两种方法使用相同的经济高效部署模型,因此你可以根据团队的专业知识和需求进行选择,而不受成本约束。