原文标题:Building RAG workflows in n8n: choosing the right Pinecone node
原文链接:https://www.pinecone.io/learn/pinecone-assistant-vs-pinecone-vector-store-node-n8n/
给 n8n 用户的特别优惠:在 2026 年 5 月 1 日前使用 Assistant 节点进行构建,升级到 Pinecone Standard 方案时可获得折扣。点击这里了解更多。
当你在 n8n 中构建 RAG(检索增强生成)工作流时,很容易在做出任何有用成果之前就陷入 pipeline 细节决策。该用哪种 chunking 策略?哪种 embedding 模型?需不需要 reranker?为什么结果不符合预期?!不知不觉就过去了三天,还是没有交付任何东西。Pinecone Assistant 节点的存在,就是为了把这些问题都移除——它会为你处理 chunking、embedding、retrieval 和 reranking,让你专注在“要构建什么”,而不是“检索如何工作”。但有时你确实需要那种控制力。本文会帮你判断何时该选哪一个。
理解这两个节点
Pinecone Assistant 节点:托管式 RAG pipeline
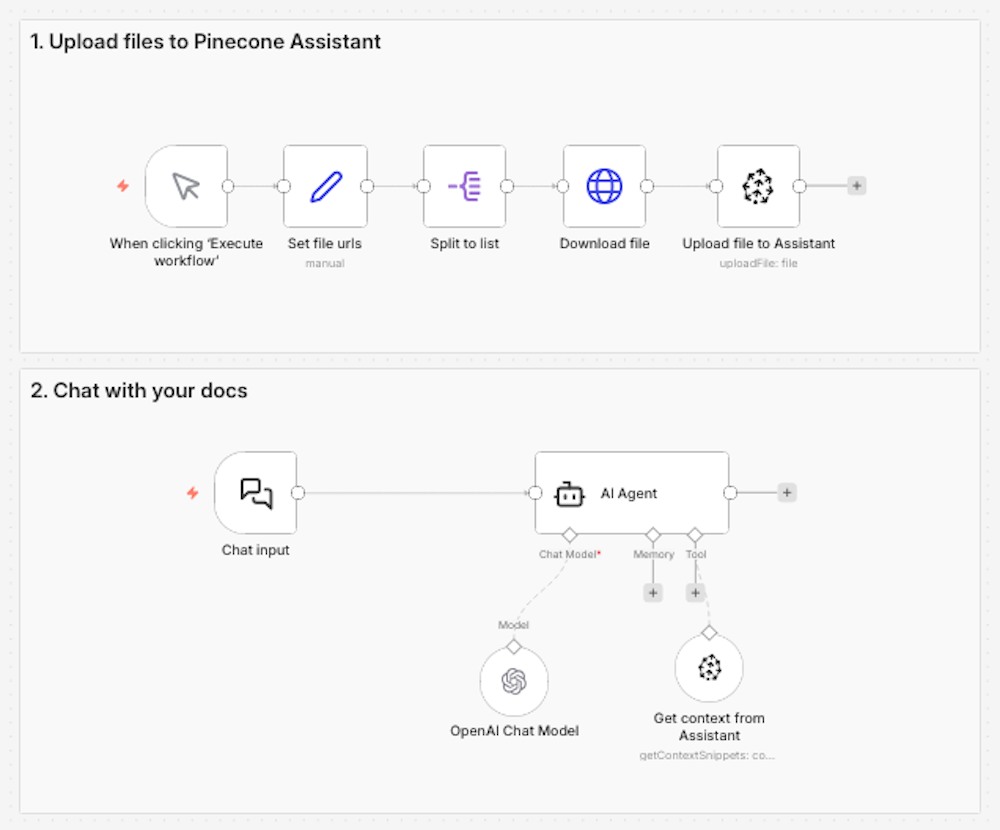
把 Pinecone Assistant 节点理解成一个托管式 RAG pipeline。当你通过这个节点向 Assistant 添加文档时,Pinecone 会自动处理文档 chunking、embedding 生成、查询理解、结果 reranking,以及 prompt engineering。在你的 n8n 工作流里,你只需要与一个 Assistant 节点交互:发送文档、发起查询,并拿回相关上下文。
技术考量:
- 需要管理 1-2 个节点
- 只需管理一个 Pinecone API key
- Assistant 产品改进时可自动获得更新
- 基于检索最佳实践提供有倾向性的默认配置
- chunking 和 embedding 由系统代管
- 查询规划与语义搜索由系统代管
- 支持自定义 metadata 过滤
这种简化会产生复利效应。当 RAG 变成一个托管积木,而不是你要持续维护的 pipeline 时,你会改变自己思考“要构建什么”的方式。你不再问“怎么搭 chunking 和 embeddings”,而是问“下一步我该做什么产品能力”。这种从“基础设施思维”到“产品思维”的切换,才是 Assistant 节点真正的价值。
Pinecone Vector Store 节点:完整 pipeline 控制
Pinecone Vector Store 节点让你直接访问向量数据库。你需要在 n8n 工作流中自行搭建并维护整个 RAG pipeline:选择 chunking 策略、为数据生成 embeddings、并实现检索方案。
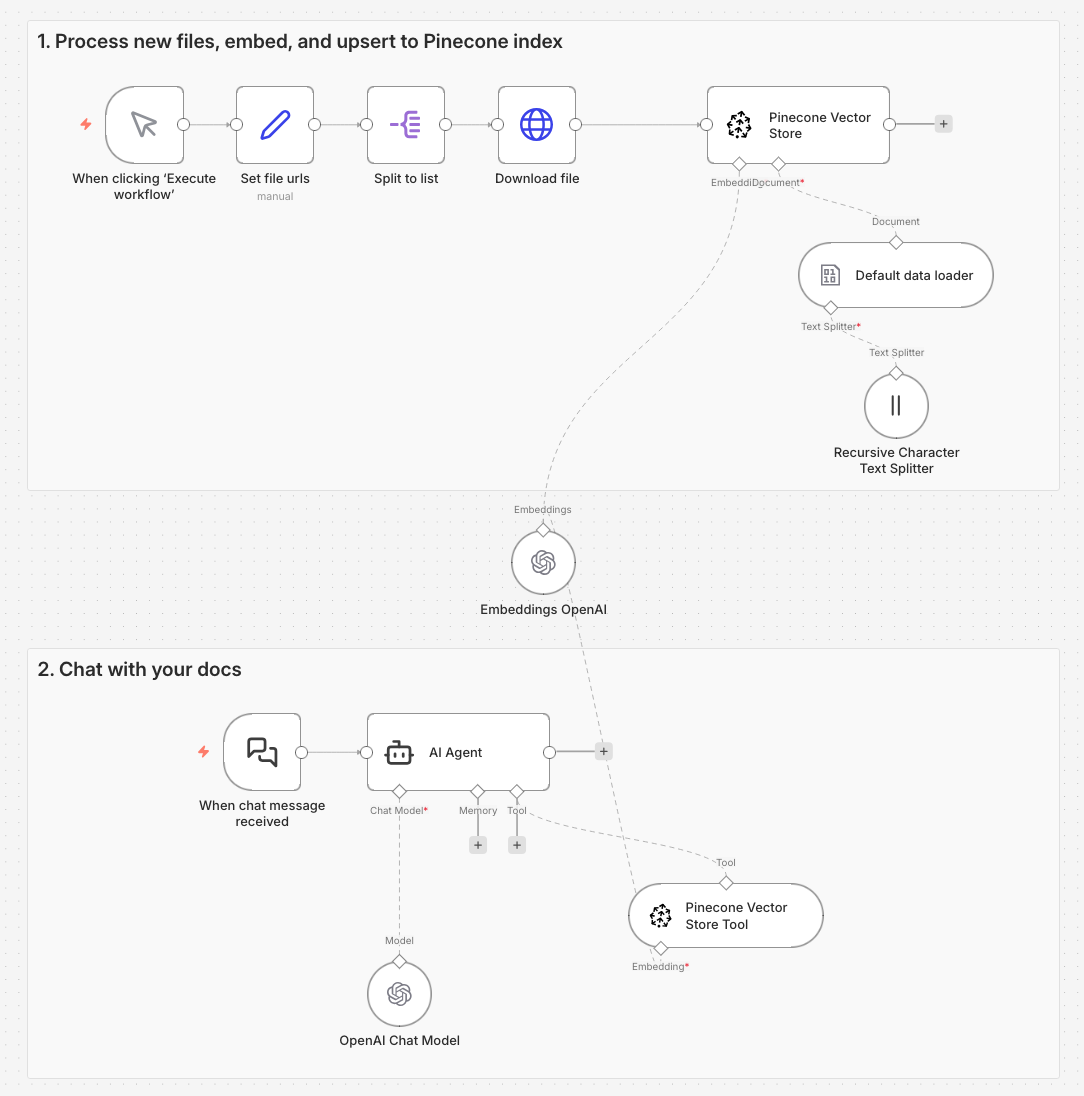
技术考量:
- 需要管理 5 个以上节点(vector store、embedding model、data loader、text splitter、reranker)
- 需要管理多个 API key(Pinecone、embedding 模型、reranker)
- 对 pipeline 每个组件拥有完整控制权
- 可配合任意 embedding 模型(OpenAI、Cohere、自定义模型)
- 可直接访问向量数据库
- 支持 hybrid search 和 metadata filtering 等高级技术
- 架构变更(例如切到 hybrid search 或更换 embedding 模型)需要更新 pipeline
- 出现故障时,需要你自己跨节点与多集成链路排查
如何判断该用哪个节点?
归根结底是一个问题:你是否需要对 chunking、embeddings、retrieval 或 reranking 做自定义控制?

何时使用 Pinecone Assistant 节点
Assistant 节点最适合标准知识检索类应用,例如客服 chatbot、内部知识库、FAQ 系统和产品文档搜索。如果你做的是常规文档检索,而管理 chunking 策略和 embeddings 的复杂度并不会给你的场景增加实际价值,那么 Assistant 节点会自动处理全部环节。它也适用于你需要快速上线、但不想先成为 RAG pipeline 专家的时候,或者你希望在 Assistant 新能力发布时自动获得更新。
何时使用 Pinecone Vector Store 节点
Pinecone Vector Store 节点面向的是“检索 pipeline 细节确实重要”的专项场景。如果你处理的是有特殊检索需求的结构化内容,比如带代码片段的技术文档、对子句级精度要求极高的法律文档,或需要按语言定制处理的多语内容,Vector Store 节点可能是更好的选择。当你必须指定 embedding 模型时——无论是基于你数据微调的模型、领域专用模型,还是出于合规要求必须使用的模型——它也是正确选择。如果你要实现 hybrid search 或带自定义 reranking 的多阶段检索,Vector Store 节点会给你构建所需方案的控制力。
总结
最好的 RAG pipeline,是那条你不需要反复思考的 pipeline。Pinecone Assistant 节点能把你带到那个状态——托管式检索、更整洁的工作流画布,以及把注意力放回“你真正要构建什么”的空间。
当你遇到真实限制——需要自定义 chunking 的特殊内容、领域专用 embedding 模型、或高级检索技术——Vector Store 节点会给你进一步深入的控制能力。但这是一种有意识的权衡,不应当成为起点。
对多数 n8n 构建者来说,Pinecone Assistant 节点是更合适的起点。你越早不再问“这个怎么搭出来?”,就越早开始问“接下来我该构建什么?”——而有意思的工作,正是从那时开始。
准备好在 n8n 上使用 Pinecone Assistant 节点了吗?查看快速开始文档请点击这里。
如果你在使用 Pinecone Vector Store 节点:
- 通过我们的 n8n quickstart 开始使用 Vector Store 节点
- 了解如何使用 Pinecone Vector Store 节点
- 进一步了解如何选择合适的 chunking strategy
引用
- 原文:Building RAG workflows in n8n: choosing the right Pinecone node
https://www.pinecone.io/learn/pinecone-assistant-vs-pinecone-vector-store-node-n8n/ - Pinecone Assistant(n8n)快速开始:
https://docs.pinecone.io/guides/assistant/quickstart/n8n-quickstart - Pinecone Vector Store(n8n)快速开始:
https://docs.pinecone.io/guides/get-started/quickstart#n8n