原文标题:Announcing ADK for Java 1.0.0: Building the Future of AI Agents in Java
原文链接:https://developers.googleblog.com/announcing-adk-for-java-100-building-the-future-of-ai-agents-in-java/
Announcing ADK for Java 1.0.0: Building the Future of AI Agents in Java

作者:Guillaume Laforge,Developer Advocate
AI 和 Agent 领域演进极快,我们一直希望所有开发者在创作智能应用时都能感到高效。这就是 Google 提供开源 Agent Development Kit(ADK)框架的原因。从最初的 Python 起步,如今已发展为一个多语言生态:Python、Java、Go 和 TypeScript。
今天,我们很高兴宣布发布 ADK for Java 1.0.0 版本。让我们一起看看这次发布的亮点,并实际体验一下!
在继续阅读之前,请先看看这段视频,它展示了一个用 ADK for Java 1.0.0 实现的有趣且具体的 Agent 用例。
特性亮点
ADK for Java 1.0.0 的发布引入了多项重大增强:
- 强大的新工具:包含新的 Grounding 能力,如用于获取位置数据的
GoogleMapsTool和用于抓取网页内容的UrlContextTool。还提供了通过ContainerCodeExecutor和VertexAiCodeExecutor实现的强健代码执行能力。 - 集中式 Plugin 架构:新的
App容器管理应用级别的 Plugin,实现全局执行控制,例如日志记录或 Guardrails。 - 增强的 Context 工程:引入 Event Compaction(事件压缩),通过摘要和保留策略来管理 Context Window 的大小。
- Human-in-the-Loop(HITL):支持
ToolConfirmation工作流,允许 Agent 暂停执行等待人工审批或补充输入。 - Session 和 Memory 服务:为状态管理定义了清晰的契约,支持 Vertex AI 和 Firestore 的持久化选项。
- Agent2Agent(A2A)支持:原生支持 A2A 协议,使远程 Agent 能够跨框架无缝协作。
下面我们逐一深入这些特性!
更强大 Agent 的工具
Agent 的核心在于感知外部世界并与之交互,超越驱动它们的大语言模型(LLM)的固有知识边界。为此,Agent 可以配备各种实用工具。
为了让 Agent 给出更准确的回答,你可能知道可以通过 GoogleSearchTool 用 Google 搜索结果来 Ground Agent 的回答。现在,还可以通过 GoogleMapsTool(Gemini 2.5 支持)用来自 Google Maps 的信息来 Ground 回答:
var restaurantGuide = LlmAgent.builder()
.name("restaurant-guide")
.description("A restaurant guide for the traveler")
.instruction("""
You are a restaurant guide for gourmet travelers.
Use the `google_maps` tool when asked to search for restaurants
near a certain location.
""")
.model("gemini-2.5-flash")
.tools(new GoogleMapsTool())
.build();如果你问你的餐厅向导巴黎埃菲尔铁塔附近最”美食”的餐厅,它会告诉你埃菲尔铁塔内著名的 Jules Vernes 餐厅,甚至还会告诉你它的评分和评价:
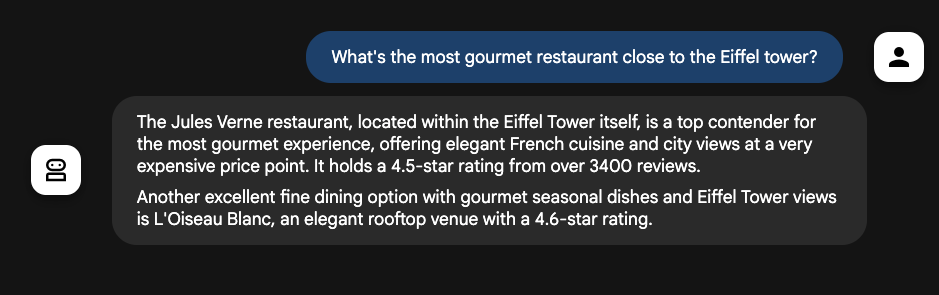
另一个有用的 Grounding 工具是 UrlContextTool,它让 Gemini 抓取 Prompt 中给出的 URL。无需自己创建网页抓取管道来喂给 Agent,它是内置的。
此外还有几个你可能感兴趣的工具:
- 代码执行器
ContainerCodeExecutor和VertexAiCodeExecutor分别可以在本地 Docker 容器中或云端 Vertex AI 中执行代码。 ComputerUseTool抽象可用于驱动真实的 Web 浏览器或计算机(但你需要实现BaseComputer的具体实现,例如通过 Playwright 集成来驱动 Chrome 浏览器)。
使用 App 和 Plugin 实现高级执行控制
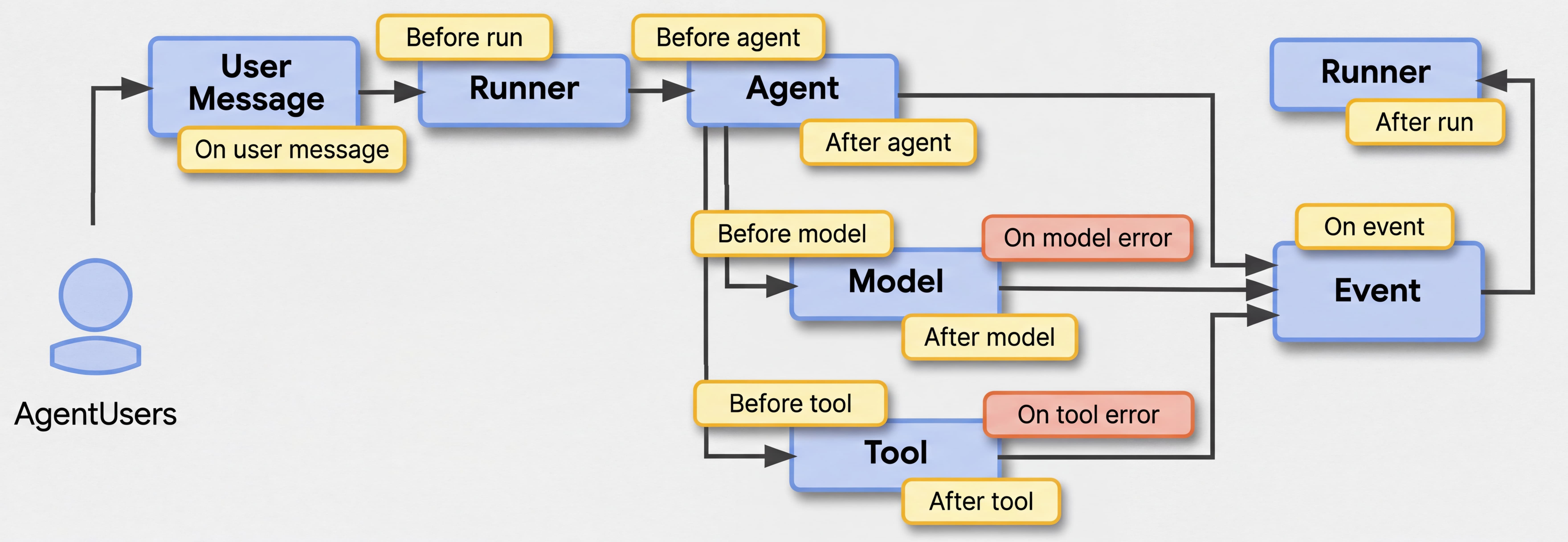
在定义 Agent 时,你可以在 Agent 交互生命周期的不同节点使用 Callback。例如,通过 beforeToolCallback(),你可以记录 Agent 正在调用的工具,甚至阻止其执行并返回预设响应。
Callback 非常有用,但需要在你定义的每个 Agent 和子 Agent 上分别应用。如果你需要在整个 Agent 层级中应用统一的日志实践怎么办?这就是 App 和 Plugin 概念的用武之地。
App 类是 Agent 应用的新顶层容器。它锚定根 Agent,持有全局配置(例如我们后面会讨论的 Event Compaction),并管理应用级别的 Plugin。
Plugin 提供了一种强大的、面向切面的方式来拦截和修改 Agent、工具和 LLM 的行为——全局作用于 App 或 Runner 内的所有 Agent,并提供超越现有 Callback 的额外扩展点。
开箱即用的 Plugin 包括:
- LoggingPlugin:提供 Agent 执行、LLM 请求/响应、工具调用和错误的详细结构化日志。
- ContextFilterPlugin:通过智能过滤较早的对话轮次来保持 LLM Context Window 的可管理性,同时安全地保留必需的函数调用/响应对。
- GlobalInstructionPlugin:为所有 Agent 动态应用一致的应用级指令(例如身份、安全规则、个性)。
假设你希望你的客服 Agent 始终使用全大写书写,可以这样配置 App 和 Plugin,并定义自己的 Runner 循环:
// 定义 Plugin
List<Plugin> plugins = List.of(
new LoggingPlugin(),
new GlobalInstructionPlugin("ALWAYS WRITE IN ALL CAPS")
);
// 构建 App
App myApp = App.builder()
.name("customer-support-app")
.rootAgent(supportAssistant)
.plugins(plugins)
.build();
// 运行应用
Runner runner = Runner.builder()
.app(myApp) // the App!
.artifactService(artifactService)
.sessionService(sessionService)
.memoryService(memoryService)
.build();除了现有的 Plugin,你还可以自己扩展 BasePlugin 抽象类,为你的 Agent 应用及其 Agent 定义自己的规则。
使用 Event Compaction 进行 Context 工程
在上一节中,我们了解了 App 概念,它还有另一个重要的配置方法:eventsCompactionConfig()。
Event Compaction 允许你通过仅保留最近事件的滑动窗口和/或摘要较早事件来管理 Agent 的事件流(历史),防止 Context Window 超出 Token 限制,并降低长时间运行 Session 的延迟和成本。这是 Context 工程中的常见做法。
在下面的示例中,我们配置了 Event Compaction 策略。并非所有参数都是必需的,但它们展示了你可以拥有的控制粒度——包括压缩间隔、重叠大小、用于摘要将被丢弃事件的 Summarizer、Token 阈值以及事件保留数量。
App myApp = App.builder()
.name("customer-support-app")
.rootAgent(assistant)
.plugins(plugins)
.eventsCompactionConfig(
EventsCompactionConfig.builder()
.compactionInterval(5)
.overlapSize(2)
.tokenThreshold(4000)
.eventRetentionSize(1000)
.summarizer(new LlmEventSummarizer(llm))
.build())
.build();如果需要更多控制,你可以实现 BaseEventSummarizer 和 EventCompactor 接口来完全自定义事件的摘要和压缩方式。
AI Agent 将人类纳入回路
LLM 是 Agent 的大脑,但它常常需要你的批准才能继续完成目标。Agent 需要请求反馈的理由有很多:比如接受执行一个危险操作,或者因为某些行为必须由人来验证——这是法律、法规或公司流程规则所要求的。
ADK 中的 Human-in-the-Loop(HITL)工作流围绕 ToolConfirmation 概念构建。当一个工具需要人工干预时,它可以暂停执行流程并请求用户确认。一旦用户提供了必要的批准(以及可选的载荷数据),执行就会正确恢复。
流程如下:
- 拦截:注册的工具可以访问其
ToolContext并调用requestConfirmation()。这会自动拦截运行,暂停 LLM 流程直到收到输入。 - 恢复:一旦人类提供了
ToolConfirmation(批准和可选载荷),ADK 就会恢复流程。 - Context 管理:ADK 自动清理中间事件,并将已确认的函数调用显式注入到后续的 LLM 请求 Context 中。这确保模型理解该操作已被批准,不会产生循环。
假设我们需要一个自定义工具来处理用户确认,确保 Agent 在执行任何操作前获得授权,可以这样实现:
@Schema(name = "request_confirmation")
public String requestConfirmation(
@Schema(name = "request_action",
description = "Description of the action to be confirmed or denied")
String actionRequest,
@Schema(name = "toolContext")
ToolContext toolContext) {
boolean isConfirmed = toolContext.toolConfirmation()
.map(ToolConfirmation::confirmed)
.orElse(false);
if (!isConfirmed) {
toolContext.requestConfirmation(
"Should I execute the following action? " + actionRequest, null);
return "Confirmation requested.";
}
return "The following action has been confirmed: " + actionRequest;
}接下来看看从 Agent 定义的角度是什么样的,这里我将 GoogleSearchAgentTool 与确认工具结合,让一个报告 Agent 使用搜索工具来创建报告:
LlmAgent assistant = LlmAgent.builder()
.name("helpful-report-assistant")
.description("A report assistant")
.instruction("""
You are a helpful and friendly report assistant.
You can use the `google_search_agent` tool to search the internet
in order to create detailed reports about user's requested topics.
Before taking any action, ask the user for confirmation first,
using the `request_confirmation` tool.
""")
.model("gemini-2.5-flash")
.tools(
// Google Search Agent 工具
GoogleSearchAgentTool.create(
Gemini.builder().modelName("gemini-2.5-flash").build()),
// 我们新创建的用户确认工具
FunctionTool.create(this, "requestConfirmation", true)
)
.build();如下面的截图所示,在我与报告助手的交互中,它在使用研究 Agent 准备报告之前请求了我的确认:
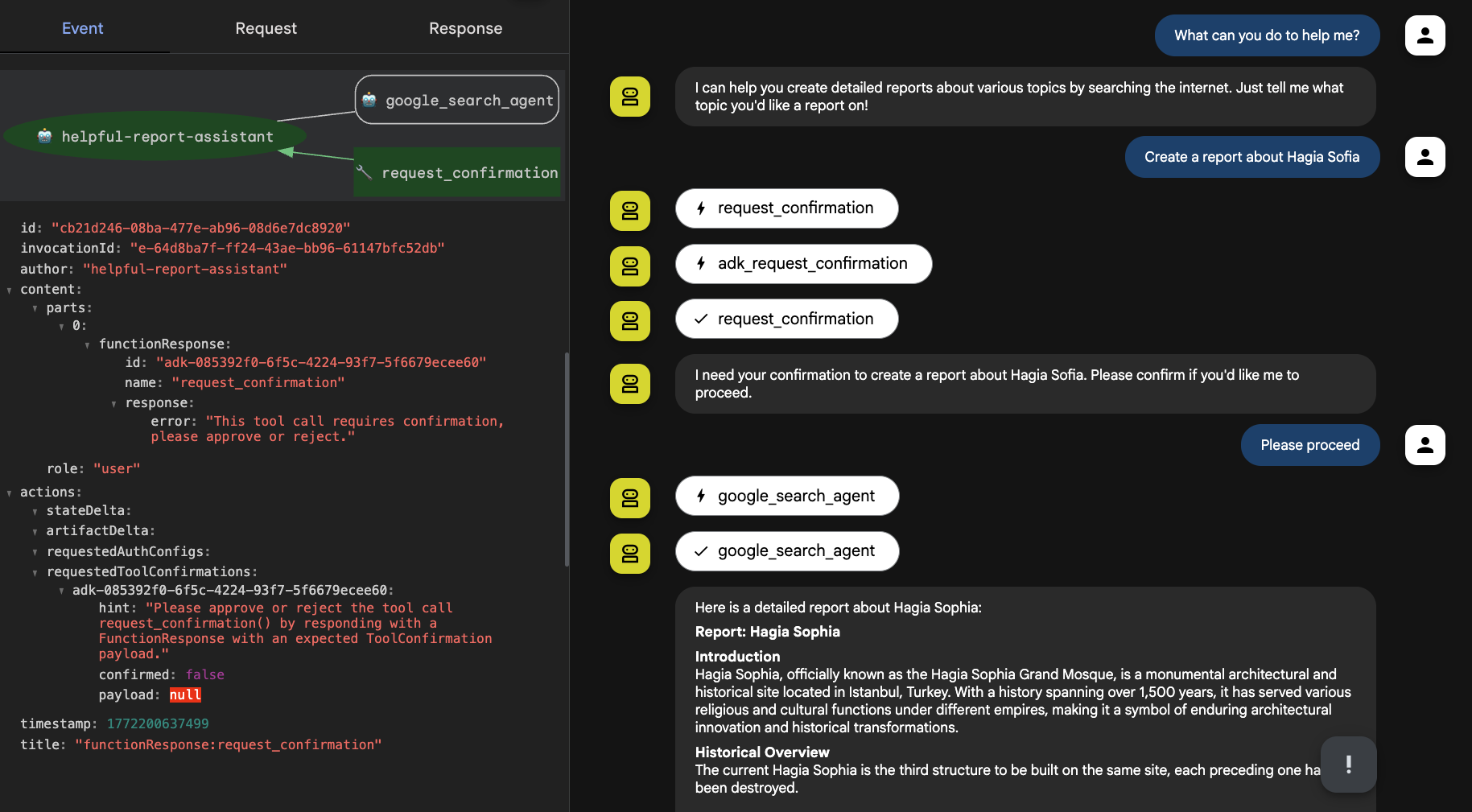
Agent 可能偶尔需要你的帮助——用于验证、澄清等。ADK 现在提供了精确配置何时以及如何与人类交互的能力。
Session 和 Memory 服务
ADK 为管理跨对话的状态、历史和文件定义了清晰的契约。
为了管理单次对话及其状态的生命周期,可以在 Runner 循环中配置以下 Session 服务:
- InMemorySessionService:轻量级、内存中的本地开发存储。
- VertexAiSessionService:由 Google Cloud 托管的 Vertex AI Session API 支持。
- FirestoreSessionService:基于 Google Cloud Firestore 的健壮、可扩展实现(由社区慷慨贡献!)。
为了让 Agent 拥有跨多个 Session 的长期”对话记忆”,提供了以下服务:
- InMemoryMemoryService:简单的关键词匹配,用于本地测试。
- FirestoreMemoryService:使用 Firestore 的持久化 Memory。
在集成方面,只需将 LoadMemoryTool 附加到你的 Agent,它就会自动知道如何从配置的 Memory Service 中查询历史上下文。
对于对话之外的内容,你的 Agent 还需要处理在 Session 中共享的大型数据对象(图片、PDF):
- InMemoryArtifactService:本地内存存储。
- GcsArtifactService:使用 Google Cloud Storage 的持久化、版本化 Artifact 管理。
永远不要遗漏正在进行的对话细节、过去 Session 中的关键事件,并跟踪所有交换过的重要文件。
使用 Agent2Agent 协议实现 Agent 协作
ADK for Java 现在原生支持官方的 Agent2Agent(A2A)协议,允许你的 ADK Agent 与使用任何语言或框架构建的远程 Agent 无缝通信。
ADK 已迁移使用官方 A2A Java SDK Client。你现在可以从远程端点解析 AgentCard(Agent 的身份 URL,表示其能力和通信偏好),构建客户端,并将其包装在 RemoteA2AAgent 中。这个远程 Agent 可以放入你的 ADK Agent 层级中,行为就像本地 Agent 一样,将事件原生流式传回 Runner。
要通过 A2A 协议暴露你自己的 ADK Agent,你需要创建一个 A2A AgentExecutor。它包装你的 ADK Agent 并通过 JSON-RPC REST 端点暴露它们,让你的 ADK 创作即刻可被更广泛的 A2A 生态系统访问。
你的 Agent 现在已准备好与更广阔的世界交互,在旅途中发现新的 Agent 伙伴,构建一个可互操作的 Agent 生态系统。你可以查看文档了解更多关于 Java 中 A2A 支持的信息。
总结
今天,随着 ADK for Java v1.0.0 的发布,以及本文的介绍,我们希望你已经对这个新版本的功能亮点有了初步了解。我们鼓励你探索本次发布中的所有新特性来增强你的 Agent。在即将发布的文章和视频中,我们将更深入地探讨其中一些主题,因为还有更多内容值得分享。
请务必查看官方 ADK 文档继续你的学习之旅,特别是如果你是初次接触 ADK,请查看入门指南。
你的反馈对我们非常宝贵!
- 报告 Bug:如果你遇到任何问题,请在 GitHub 上提交 Bug 报告。
- 贡献代码:有改进的想法或 Bug 修复?我们欢迎 Pull Request。请先查看贡献指南。
- 分享你的作品:我们很期待看到你用 ADK 构建的东西!请与社区分享你的项目和经验。
Happy agent building! With a cup of Java!