原文标题:58% of PRs in our largest monorepo merge without human review
原文链接:https://vercel.com/blog/58-percent-of-prs-in-our-largest-monorepo-merge-without-human-review
9分钟阅读
复制URL 已复制到剪贴板! 2026年4月6日
我们最大和最古老的Next.js应用之一是一个包含多个关键属性的monorepo:Vercel营销网站、我们的文档、注册流程、仪表板和内部工具。该仓库平均每周收到超过400个pull request。直到最近,每个pull request在合并前都需要人工批准。
如今,一个agent审查并合并了其中58%的pull request,不需要人工审查员,平均合并时间下降了62%,从29小时降至10.9小时。
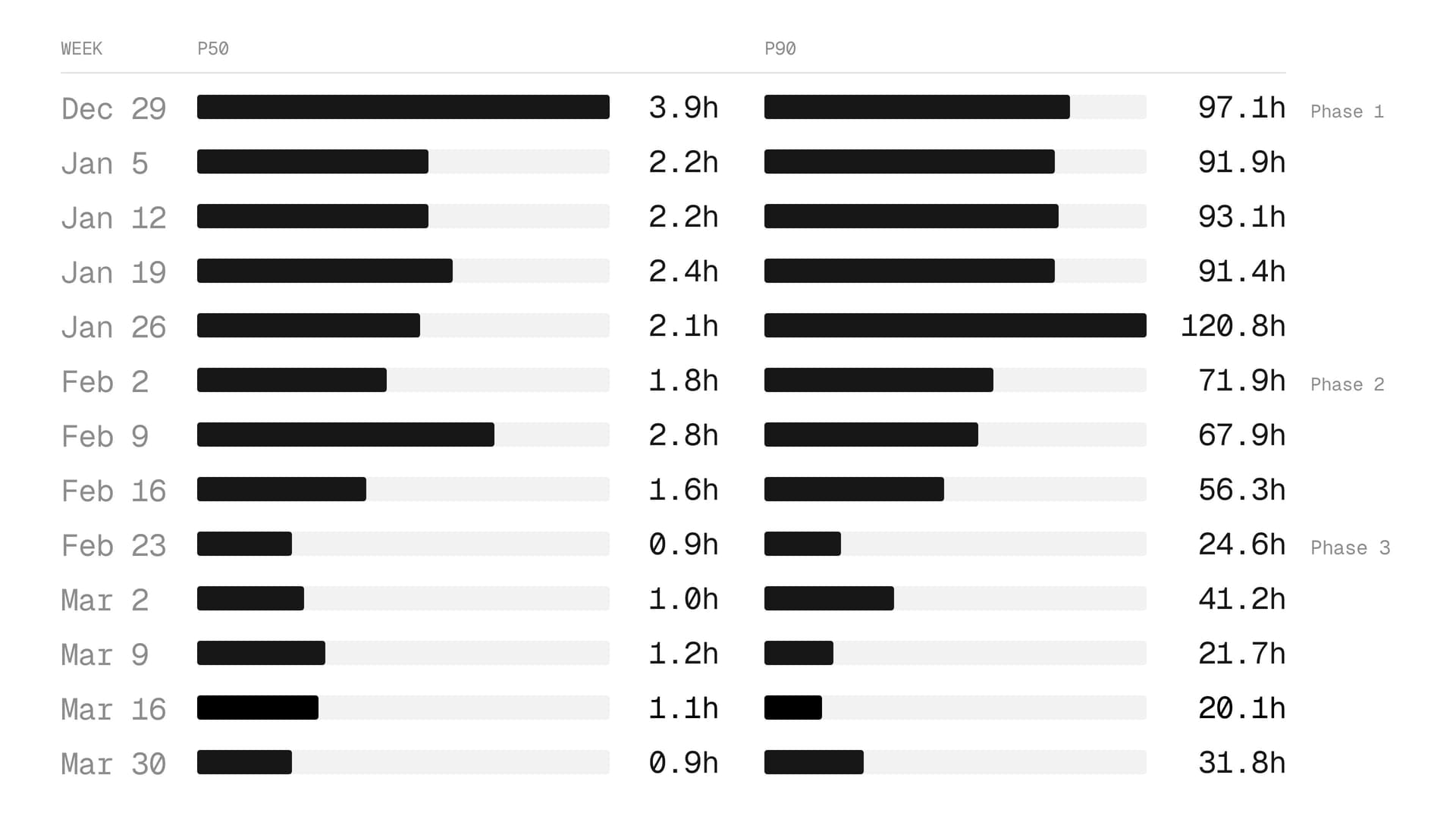
P50和P90合并时间在实验过程中下降。
合并agent生成的代码可能很危险。这是一个真实的例子,说明如何安全地使用agent本身部署到生产环境。
问题:审查瓶颈
关键的设计更新和A/B测试需要尽快上线,但它们没有以我们希望的速度进入生产环境。分析仓库中的PR后,我们发现从准备好审查到合并的平均时间是29小时。这相当于花费了整个工作日来等待。
进一步深入分析,我们发现超过一半的PR由人工批准,且零评论。18%的PR在5分钟内被仓促批准。
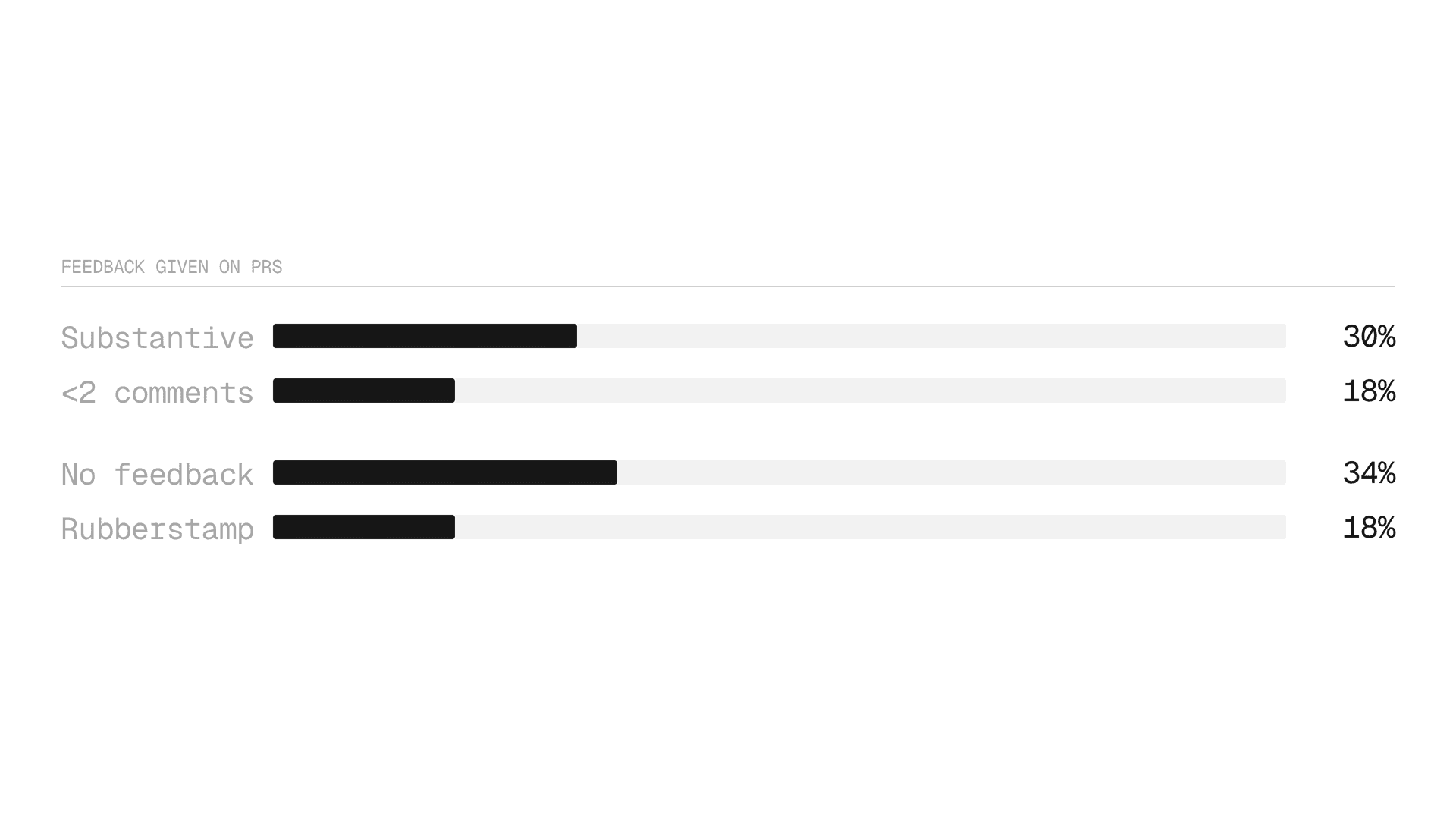
很大比例的PR被合并而不带任何评论。
所以我们问自己:如果大多数审查没有发现任何问题,那么它们究竟在保护什么?
Pull request可以轻易地混淆两种不同的活动:
- 对齐是就构建内容和方式达成一致:架构、结构和设计决策
- 验证是确认所构建的内容是否正确运行
在这样一个成熟的代码库中,大多数更改只需要验证,而AI可以很好地处理验证。要求人工审批每个CSS调整和文档更新不会使代码库更安全,只会让工程师变慢,并不必要地延迟基本更新。
讽刺的是,AI使问题变得更糟:随着agent生成代码,更多PR流入瓶颈。但答案不是要求工程师审查得更硬和更快。而是构建能够区分需要人类判断的更改和不需要的更改的系统。
这是我们如何构建自动合并工作流以及我们在此过程中学到的内容。
从风险框架开始
初始分析中显而易见的关键见解是:并非所有PR的风险相等。文档修复和身份验证更改具有根本上不同的影响范围。我们需要一种方法来自动分类该风险。
我们使用Gemini构建了一个基于LLM的PR分类器,它基于diff、标题和描述来评估每个PR。该分类器分配两个标签之一。
- 高风险包括身份验证、支付、数据完整性、安全性和基础设施的更改。这些总是需要人工审查
- 低风险包括UI更改、样式、测试、文档、重构和已关闭的功能标志。这些是自动批准的候选者。
该分类器返回结构化JSON:
{
"evidenceQuotes": ["+ color: var(--ds-gray-600)"],
"rationale": "CSS-only theme changes",
"changes": ["`dashboard-theme.css`: updated color custom properties"],
"riskLevel": "LOW"
}该schema将evidenceQuotes放在首位,riskLevel放在末位。这迫使模型在分类前提取逐字逐句的diff片段并进行推理。如果它在实际代码中找不到风险证据,它默认为LOW。该决策以diff为基础,而不是PR标题。
分类器还被调整为偏向于假阳性而非假阴性。假阳性会导致一次不必要的审查。假阴性让有风险的代码未经审查就发布。它将93%的数据完整性PR和92%的安全PR标记为高风险。在频谱的另一端,0.2%的样式PR和0.4%的文档PR被标记为高风险。

这些类别不是固定的。每项风险评估都包括一个”错误?“链接,该链接将响应记录到Datadog并将通知路由到Slack。当工程师标记分类错误时,我们审查它,如果分类器出错,我们将PR添加到我们的评估中。
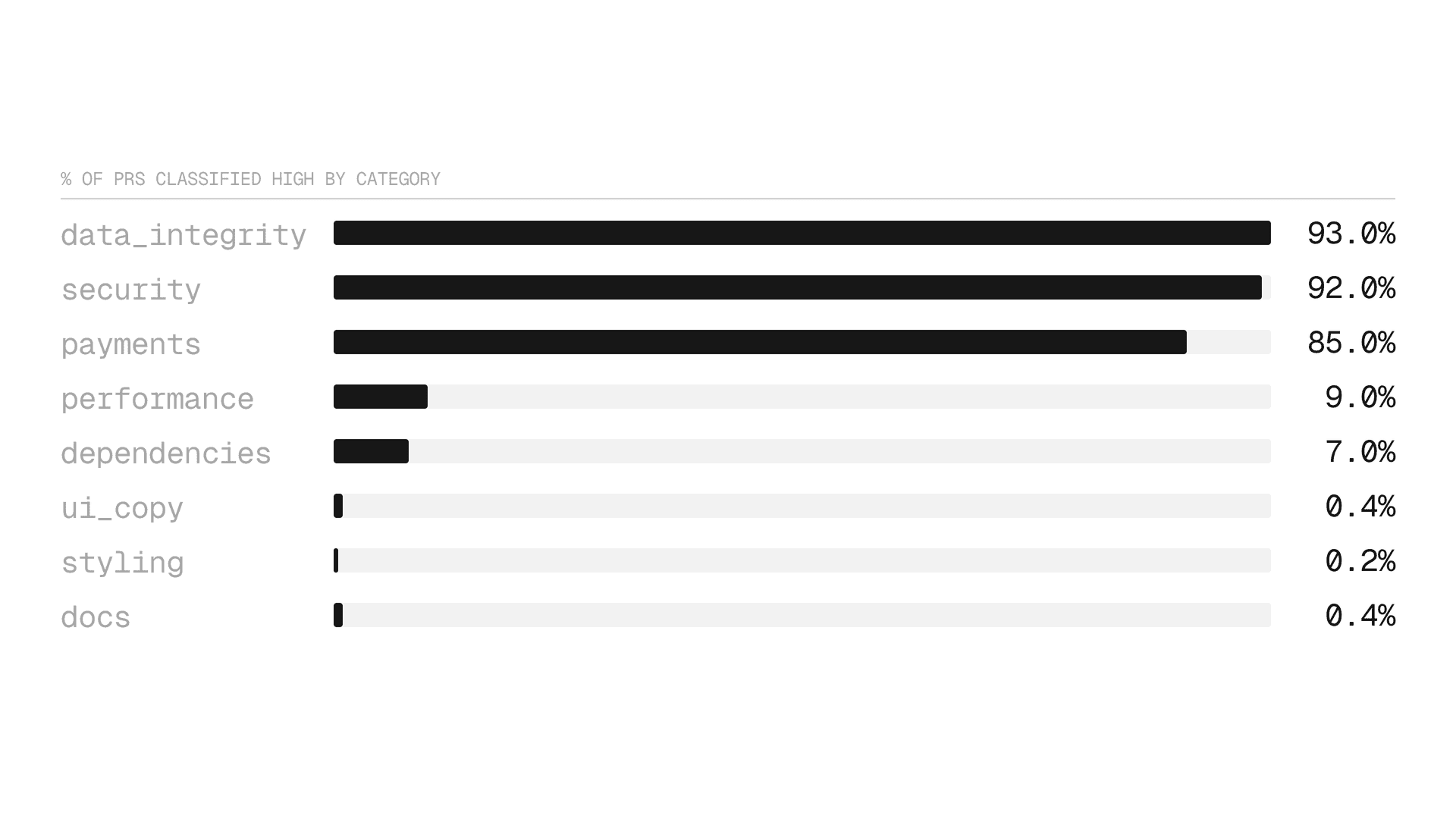
LLM分类器准确地标记了大多数PR。
两条硬规则绕过LLM:具有100+更改文件的PR总是高风险,CODEOWNERS保护的路径总是需要人工审查。
所有LLM调用都通过Vercel AI Gateway路由,用于缓存、速率限制和可观测性。成本约为每次评估$0.054,或每周约$51。
这种方法将我们最近描述的可执行保护栏付诸实践。与其列出什么被视为有风险的wiki页面不同,我们将该判断编码到管道本身。
测试、验证和推出
我们分三个阶段推出了这一产品,每个阶段都旨在在增加合并自主水平之前建立信心。在开始测试前,我们定义了kill switch。如果出现以下情况,实验将结束:
- 恢复率超过我们1.7%基线的3倍(5.1%阈值)
- 回滚率超过3倍基线(7.2/周阈值)
- 团队情绪变为负面
以下是实验的各个阶段及其中发生的情况:
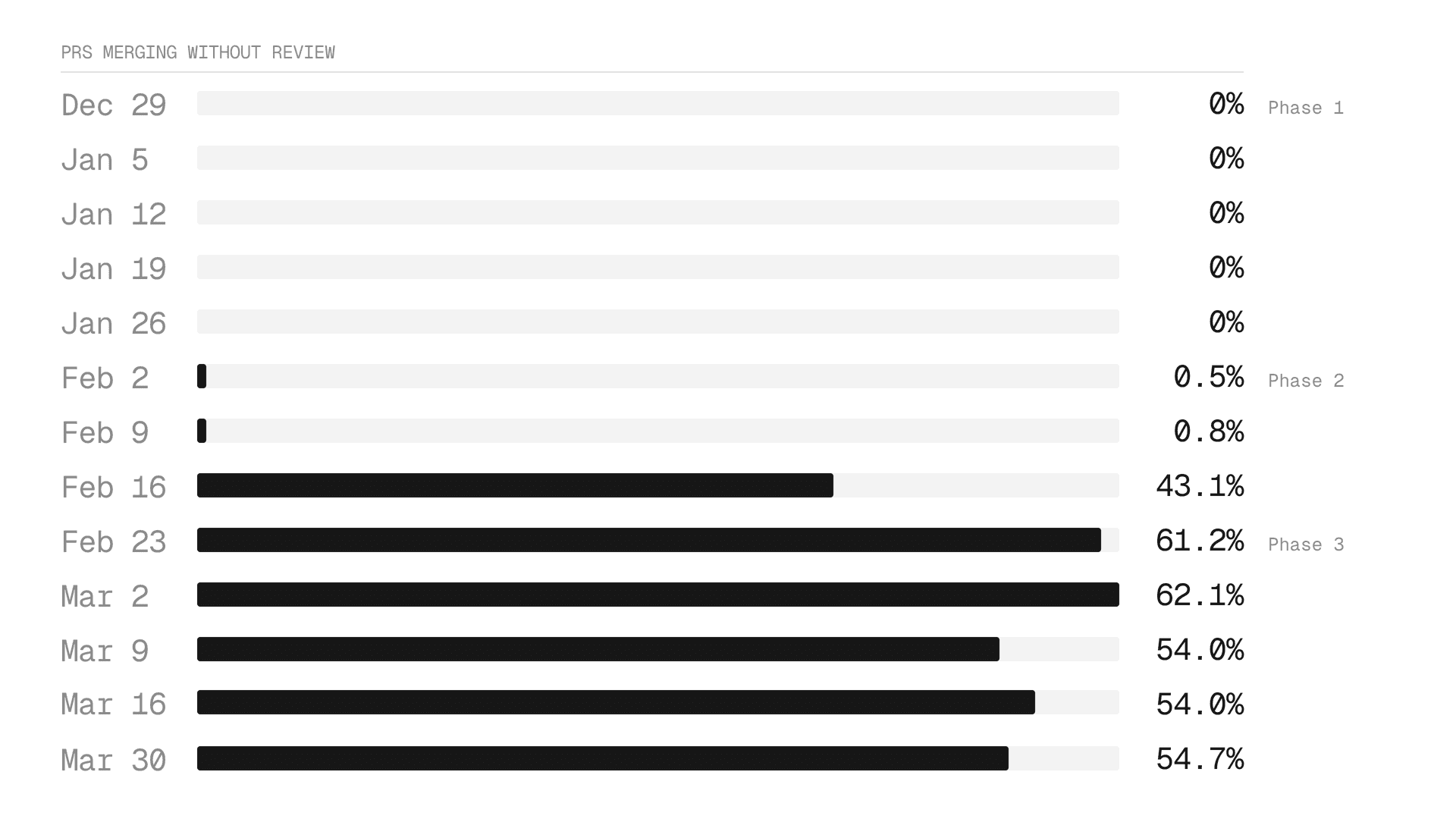
阶段1:静默分类
LLM开始将每个PR标记为低风险或高风险。唯一可见的信号是一个GitHub检查,该检查显示分类。对agent或团队的操作没有任何改变。
我们收集数据并针对我们自己的风险评估验证准确性。花费了大约三周的prompt迭代来达到我们的准确性阈值。此时,我们准备好与我们的工程团队验证结果。
阶段2:可见标签
Vercel Agent开始在每个PR上评论,提供风险分类和原理。工程师可以看到推理、质疑它,并单击”错误?“来标记错误。
阶段3:执行
在此阶段,低风险PR由Vercel Agent自动批准,满足分支保护而无需人工审查员。高风险PR获得警告评论,仍然需要人工批准。
工程师仍然能够请求审查他们提交的任何PR。变化是审查不再是低风险更改的阻碍。
结果通过了每个安全阈值,该工作流现在是仓库的默认设置。
在整个实验和执行过程中维持了SOC-2合规性。
结果
跳过审查不会增加恢复
这是最重要的问题。如果我们让低风险PR跳过审查,会有更多坏代码到达生产吗?
671个低风险PR跳过了审查。零被恢复。(Wilson 95% CI上限:0.6%,远低于我们的1%安全阈值。)
对照组(仍然收到审查的低风险PR)具有相同的恢复率:513个中有2个(0.39%)。跳过审查没有产生可测量的差异。
部署回滚从每周2.8次减少到每周1.9次。实验期间的回滚都不是由自动批准的PR引起的。
唯一导致回滚的事件是中间件重定向更改。分类器将其标记为高风险。人工审查了它,批准了它,并合并了它。分类器捕获了危险更改,但人类让它通过了。
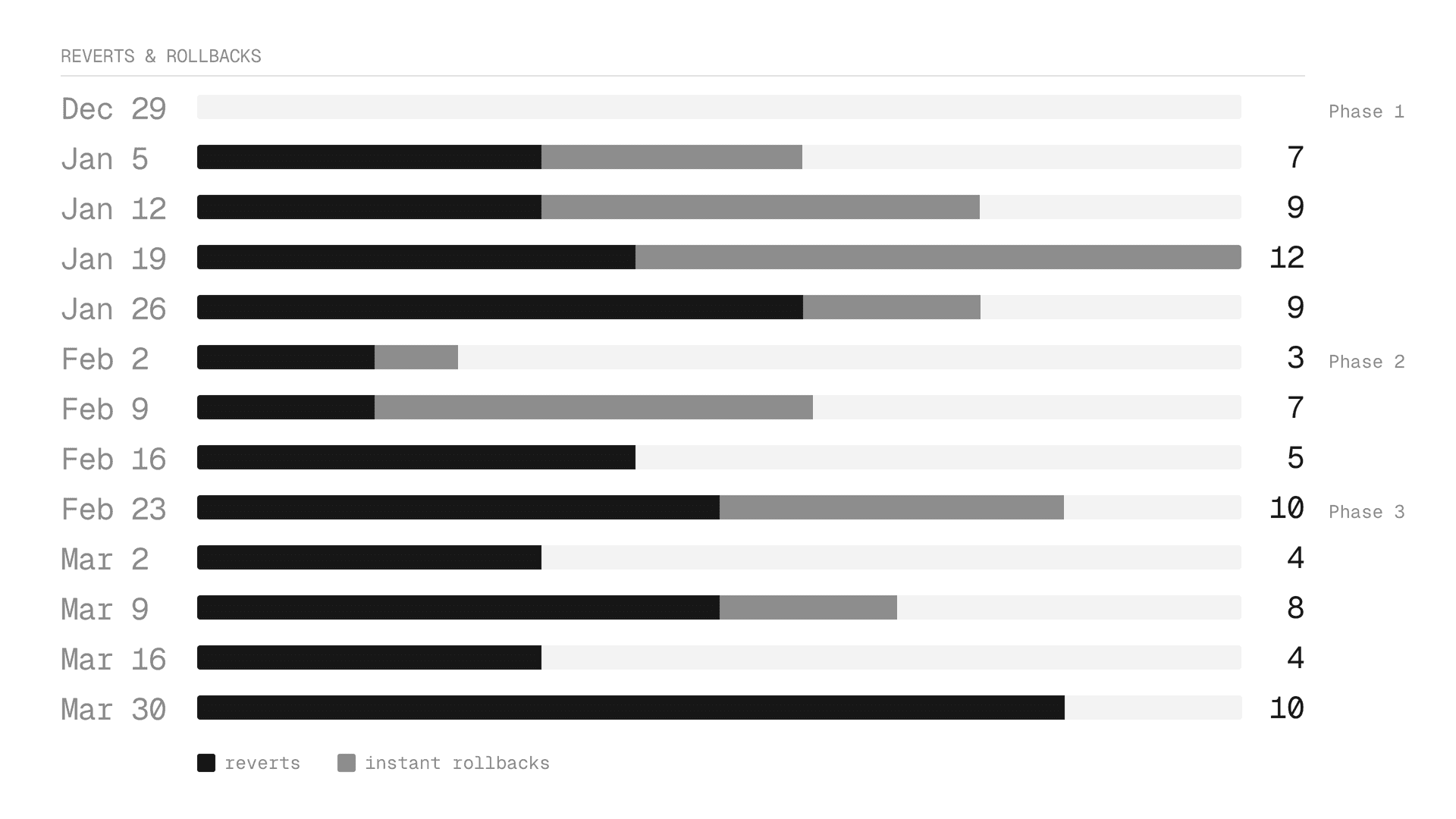
工程师快速发布62%
跳过审查的PR的中位合并时间为0.5小时,而审查过的PR为2.3小时。差距在尾部扩大:在p90,跳过的PR比审查的PR快58.3小时。
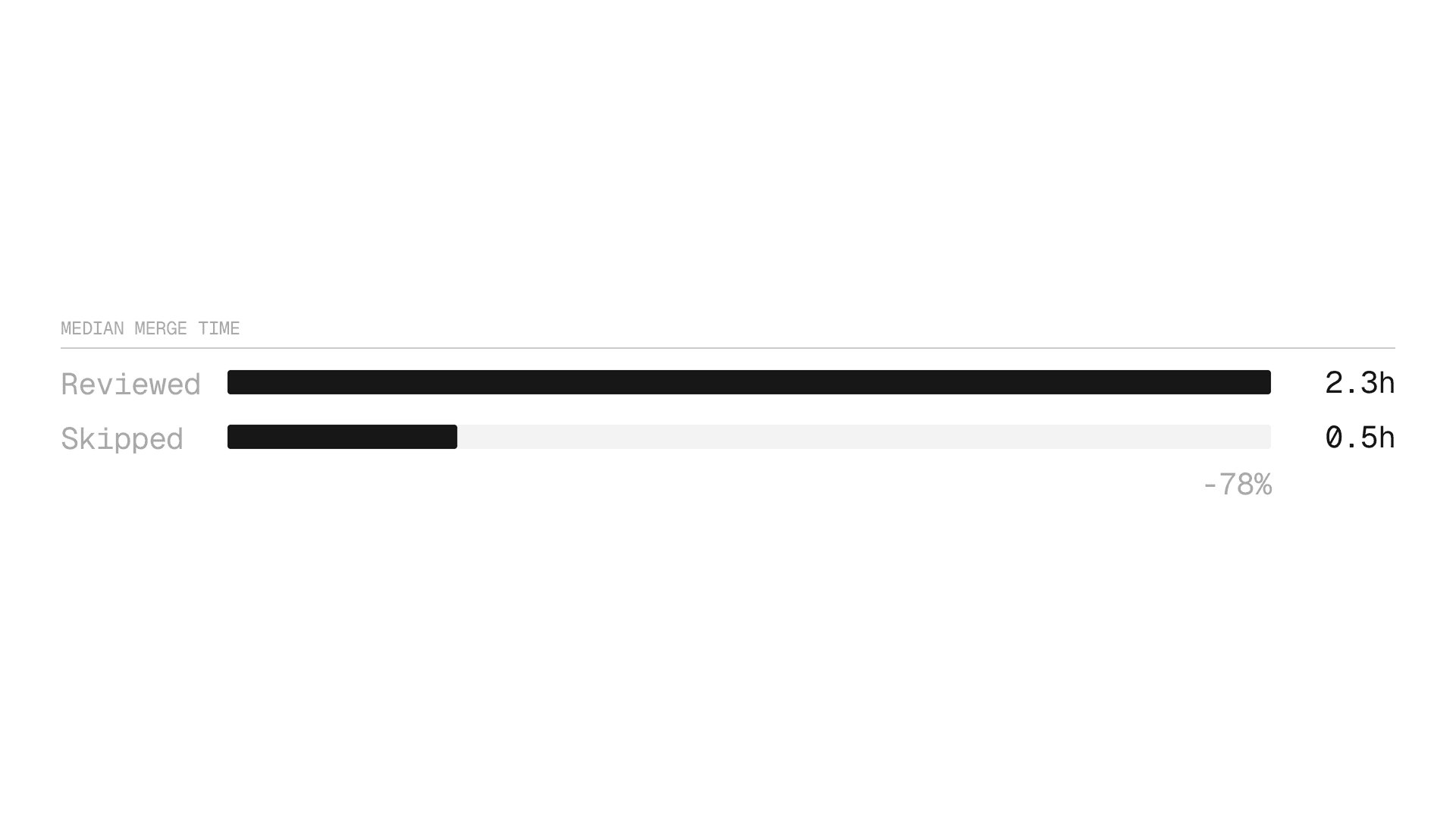
采用是即时的。执行打开的那一周,61%的低风险PR跳过了审查。
个人人工吞吐量增加了46%。每周每个活跃作者的PR从2.6个增加到3.8个。
峰值合并时间从下午2-4点转移到下午6-10点PST。非工作时间合并增加了7.5个百分点,周末合并增加了6.3个百分点。工程师现在在工作完成时合并,而不是在审查者在线时合并。
人工审查在重要的地方变得更好了
高风险、大diff PR的首次审查时间从24.7小时下降到9.0小时,提高了2.7倍。当风险更改需要人类关注时,它会更快地获得关注。

审查员工作负载也从每周13个PR减少到刚超过5个。由于PR较少,工程师进行更彻底的审查。

高风险PR的仓促批准率保持不变(11.9% vs 12.4%基线)。审查中标记的安全问题从6.3%跳升至27.2%。小高风险diff的审查深度改进了。
工程师同意分类器吗?
我们通过行为而不是调查来测量工程师的分歧。
| 信号 | 率 |
|---|---|
| 在低风险PR上请求更改 | 0.9% |
| 低风险PR被恢复 | 0.2% |
43%的低风险PR仍然收到自愿审查,尽管不是必需的。其中70%没有评论。一些团队仍然更喜欢进行审查以进行协作和知识共享,但关键是使审查成为选择,而不是门槛。
对抗性强化
分类器处理用户控制的输入并根据结果自动批准。这是一个对抗面。
架构
该系统设计使得即使完全受损的LLM输出也无法造成严重伤害:
- 零工具。LLM输出结构化JSON。没有代码执行、没有文件访问、没有API调用。
- 受约束的输出、预定的操作。该模型只能返回两个有效的风险级别,这映射到两个可能的系统操作:批准或警告评论。没有从LLM输出到任意行为的路径。
- 故障开放。如果LLM失败或返回无效输出,PR将回到标准人工审查。
输入强化
不可见Unicode剥离。我们从所有LLM输入中剥离标签字符、变体选择器和双向重写。这些不可见字符可以向prompt中走私指令。
输出清理。模型生成的文本在发布到GitHub前进行清理。非HTTPS链接和图像嵌入被剥离。
作者门控。来自不可信作者的PR会获得分类和发布的评估,但从不自动批准。
对抗性评估套件。三个prompt注入场景在每次部署时运行,准确率门槛为100%。
我们考虑过但拒绝了什么
我们探索了额外的强化方法,但没有实施它们。
| 防御 | 为什么 |
|---|---|
| 加盐XML标签 | 聊天机器人威胁模型,不是结构化分类。打破prompt缓存。 |
| 三明治防御 | 已发表的研究中成功率太高;针对自适应攻击>95% |
| XML转义输入 | 破坏合法代码 |
限制
分类是概率性的。没有单一防御是绝对的。
分类器加快了简单决策。它不能替代对困难决策的判断。高风险更改总是需要人工审查。成功攻击的最坏情况是一个低风险PR获得自动批准,我们持续监视恢复和回滚率以检测漂移。
合规
工程领导者提出的一个常见问题是:合规性呢?
合规框架要求明确定义的变更管理程序,而不是特别是强制性的对等审查。重要的是变更被授权、记录、测试和通过一致的、可审计的过程批准。
添加基于LLM的风险分类器以三种方式强化了我们的变更管理流程:
- 更好的文档。每个PR现在都获得具有推理、证据和分类的结构化风险评估。审计跟踪从单个批准点击变为每个PR的完整风险原理。
- 基于风险的路由。分类器不是对待每个更改相同,而是将人工注意力路由到最重要的高风险更改。低风险更改通过一致的、可审计的批准流程进行。安全敏感路径仍然通过CODEOWNERS要求指定的审查员。
- 连续监视。恢复率、回滚率和分类器准确性每周跟踪。这创建了强制审查从未有过的反馈循环。
包括基于我们内部基于风险的方法建模的基于LLM的PR分类器增强了我们的变更管理流程,并为可审计性提供了额外的文档。
我们学到了什么
强制审查已经是戏剧了。52%的审查什么都没有产生。自动批准不会移除一个运行的安全网。它停止了要求一个不起作用的那个。671个跳过的审查,相同的恢复率如同审查的PR,合并速度快62%。
真正的收获是焦点,而不仅仅是速度。审查员到达高风险PR的速度快2.7倍。关键PR的瓶颈从来都不是审查容量。它是审查分配。
保守的分类是正确的默认值。假阳性的成本是一次不必要的审查。假阴性的成本是有风险的代码未经审查就发布。过度标记并让工程师选择退出。
审查成为了选择,而不是门槛。43%的低风险PR仍然收到自愿审查。一些团队更喜欢进行审查以进行协作和知识共享,这是理想的状态。
接下来是什么
跳过审查工作流现在在我们最大的monorepo上是永久性的。我们使用相同的三阶段方法将其推出到更多仓库。
随着agent生成更多代码和PR量增加,审查瓶颈对于不适应的团队来说只会变得更糟。答案不是审查更硬。而是构建能够将风险判断编码到管道中的系统。
稀缺的资源是人工判断。在重要的地方花费它。